Apache Zeppelin部署及案例验证指引
作为大数据研究分析,我越发觉得有必要能有一款快速上手,能够适合单一数据处理、但后端处理语言繁多的场景相关的开源工具。最近我找到了一款Apache Zeppelin,下面是我初步实战初步收获。
-
简要介绍
Apache Zeppelin是一款基于Web的Notebook(类似于jupyter notebook),支持交互式地数据分析。
Zeppelin可实现数据采集、数据发现、数据分析、数据可视化和协作。
支持多种语言,默认是Scala(背后是Spark shell),SparkSQL, Markdown ,SQL,Shell,Markdown和Python等。
另外通过JDBC协议支持多种数据源,默认为postgresql,Mysql、Hive等。
适用场景:Zeppelin适合单一数据处理、但后端处理语言繁多的场景,尤其适合Spark。
-
部署环境
| Name |
Value |
备注 |
| Oracle JDK |
1.7 (set JAVA_HOME) |
|
| OS |
Mac OSX Ubuntu 14.X CentOS 6.X RedHat 5.X Windows 7 Pro SP1 |
|
| Hadoop集群相关 |
Spark-1.6.0 Hive1.1.0 CDH 5.13.3-1 |
相关组件都已经部署正常运行(事业部大数据测试环境服务器,且可上外网) |
| Zeppelin |
0.7.3 |
|
-
部署步骤
-
下载介质
-
Zepplin安装包:wget http://archive.apache.org/dist/zeppelin/zeppelin-0.7.3/zeppelin-0.7.3-bin-all.tgz
-
解压配置
1)、此套环境下载安装介质包统一放在/opt下,下载完成后:
tar -zxvf zeppelin-0.7.3-bin-all.tgz

2)、由于在解压过程中可能属主不是root,还需要通过更改成root:
chown –r root zeppelin-0.7.3-bin-all
3)、解释器相关依赖jar包
统一存放在/opt/zeppelin-0.7.3-bin-all/lib目录下。
Hive相关依赖包:
wget http://central.maven.org/maven2/org/apache/hive/hive-jdbc/0.14.0/hive-jdbc-0.14.0.jar
hadoop-common-2.6.0-cdh5.13.3.jar
wget http://central.maven.org/maven2/org/apache/hadoop/hadoop-common/2.6.0/hadoop-common-2.6.0.jar
wget http://central.maven.org/maven2/mysql/mysql-connector-java/5.1.38/mysql-connector-java-5.1.38.jar
cp hadoop-common-2.6.0-cdh5.13.3.jar /opt/zeppelin-0.7.3-bin-all/lib
spark相关依赖包见spark验证章节配置
4)、定义配置conf/zeppelin-site.xml
默认不需要配置此文件,也可以正常启动服务,但考虑到端口确保不冲突。
cp zeppelin-site.xml.template zeppelin-site.xml,通过vi编辑文件,更改此块内容:
默认web访问端口号:8080,一般建议改成不易冲突且易记忆的端口号。本次我改成了8383:
如果想匿名访问web端,则可以将false更改为true,但一般不建议生产环境这样做。
5)、添加登录账号信息
将conf/shiro.ini.template拷贝为shiro.ini
修改里面的用户名和密码,修改见下面截图:

6)、定义配置conf/zeppelin-env.sh
默认不需要配置此文件,也可以正常启动服务,但我们引入外部hadoop相关组件。
cp zeppelin-env.sh.template zeppelin-env.sh,通过vi编辑文件,在文件尾部加入:
#add env darren 1808028
export JAVA_HOME=/usr/java/jdk1.7.0_79
export JRE_HOME=$JAVA_HOME/jre
export HADOOP_CONF_DIR=/etc/hadoop/conf
export HADOOP_HOME=/opt/cloudera/parcels/CDH-5.13.3-1.cdh5.13.3.p0.2/lib/hadoop
export SPARK_HOME=/opt/cdh5/spark-1.6.0
export HIVE_HOME=/opt/cloudera/parcels/CDH-5.13.3-1.cdh5.13.3.p0.2/lib/hive
export HBASE_HOME=/opt/cloudera/parcels/CDH-5.13.3-1.cdh5.13.3.p0.2/lib/hbase
export MASTER=spark://172.17.XX.XXX:7099
export ZEPPELIN_HOME=/opt/zeppelin-0.7.3-bin-all
7)、访问hive仓库,依赖hive服务下配置文件hive-site.xml。在确保hive server运行正常的前提下,需要从相应运行服务环境。本轮环境是XXX-bigdata-2.novalocal节点上,运行
Scp /opt/cloudera/parcels/CDH/lib/hive/conf/ hive-site.xml
[email protected]: /opt/zeppelin-0.7.3-bin-all/conf
另外记得在该文件尾部添加一段访问hive元数据的账号密码:
8)、启停zeppelin服务
停启一体命令(先停再启)
./opt/zeppelin-0.7.3-bin-all/bin/zeppelin-daemon.sh restart
启命令
./opt/zeppelin-0.7.3-bin-all/bin/zeppelin-daemon.sh start
停命令
./opt/zeppelin-0.7.3-bin-all/bin/zeppelin-daemon.sh stop
9)、默认匿名登录zeppelin web,可直接访问http://172.17.XX.XXX:8383/#,当前部署的环境设置了登录账户信息,不可匿名。
输入账号admin,密码adimin1234
-
案例验证
-
操作流程
-
- MySql
- 建立Interpreters
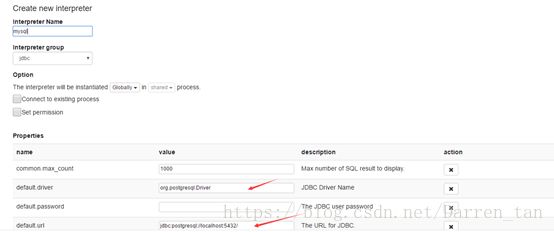
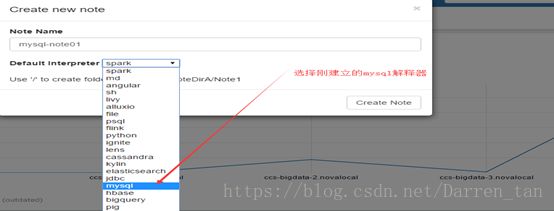
使用配置号的账号admin,登录Zeppelin系统,创建Mysql解释器,并将解释器组选择jdbc类。具体配置如下截图样式:

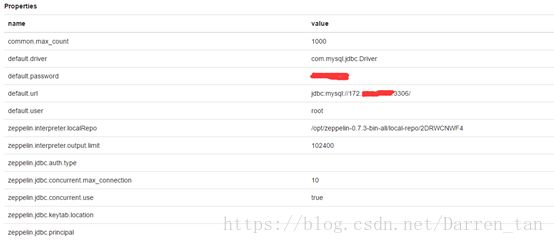
配置项完成内容如下:

-
解释器特别说明
MySql解释器关键内容及依赖特别注释说明,具体如下表内容:
- Properties
| Name |
Value |
| default.driver |
com.mysql.jdbc.Driver |
| default.url |
jdbc:mysql://localhost:3306/ |
| default.user |
mysql_user |
| default.password |
mysql_password |
- Dependencies
| Artifact |
Excludes |
| mysql:mysql-connector-java:5.1.38 |
Maven Repository: mysql:mysql-connector-java
注:需要下载连接mysql的驱动jar包,否则无法连接。
-
操作示例
1)、建立note,需要选择自己需要的解释器,此例我选择的是mysql。其它详情见图示:
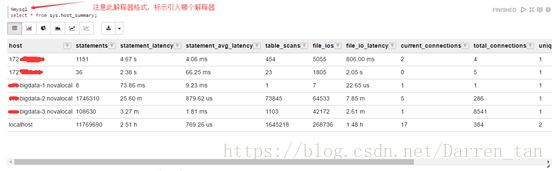
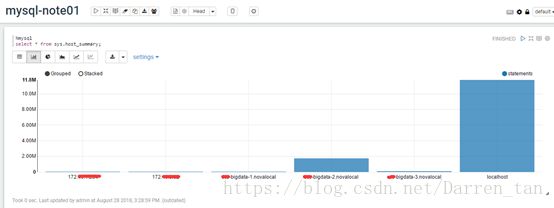
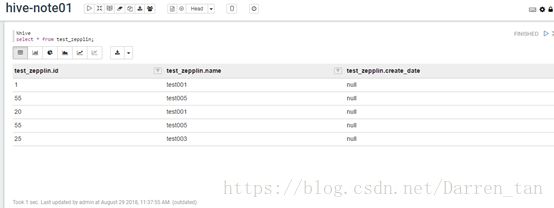
2)、在note中编辑自己需要完成查询或统计任务,如下图例查看服务器主机运行状况。
它支持表格、图形方式展示,同时支持导出csv\tsv。
效果如下图:
表格
柱状图
饼图
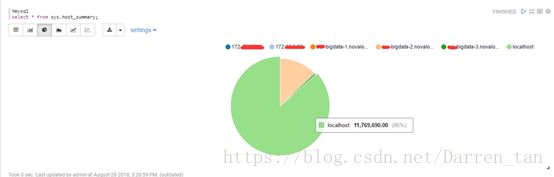
区间图
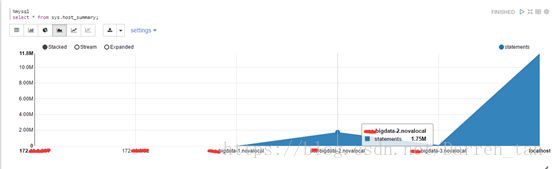
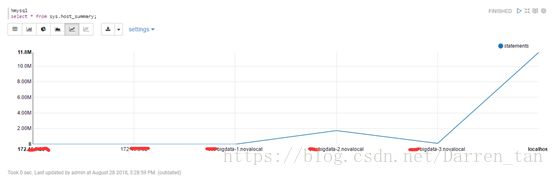
线形图
散点图
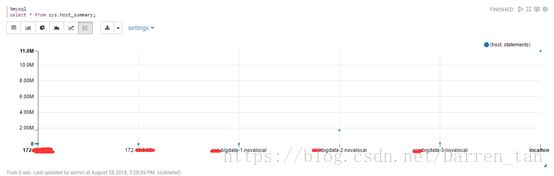
-
Hive
-
建立Interpreters
-
使用配置号的账号admin,登录Zeppelin系统,创建访问hive解释器,并将解释器组选择jdbc类。具体配置如下截图样式:
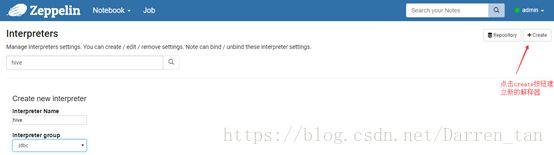

-
解释器特别说明
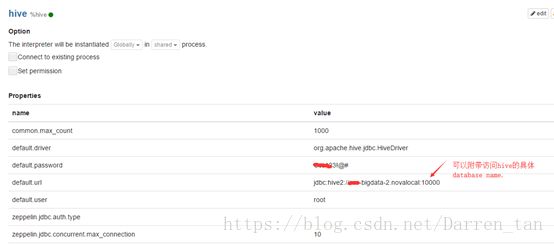
Hive解释器关键内容及依赖特别注释说明,具体如下表内容:
- Properties
| Name |
Value |
| default.driver |
org.apache.hive.jdbc.HiveDriver |
| default.url |
jdbc:hive2://localhost:10000 |
| default.user |
hive_user |
| default.password |
hive_password |
- Dependencies
| Artifact |
Excludes |
| org.apache.hive:hive-jdbc:0.14.0 |
|
| org.apache.hadoop:hadoop-common:2.6.0 |
|
Maven Repository : org.apache.hive:hive-jdbc
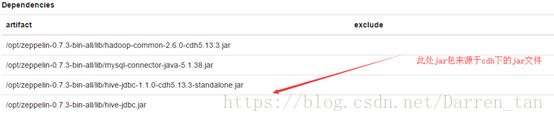
注:由于本次部署环境是CDH-5.13.3,因此此处所依赖的包需要更改成实际对应版本的jar包,具体如下图:
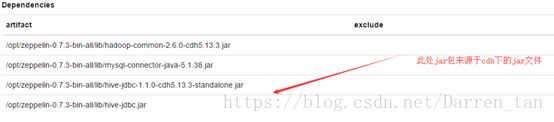
-
操作示例
1)、建立note,需要选择自己需要的解释器,此例我选择的是hive。其它详情见图示:
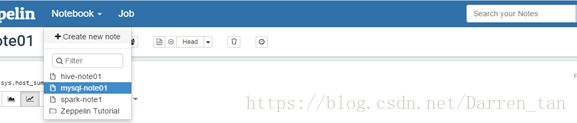
2)、在note中编辑自己需要完成查询或统计任务,如下图例查看服务器主机运行状况。
它支持表格、图形方式展示,同时支持导出csv\tsv。
3)、变化定义分组方式等信息,点击界面Settings按钮实现。拖拽变化定义keys、group和Values。
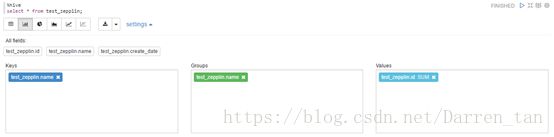
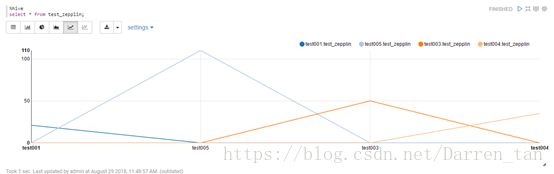
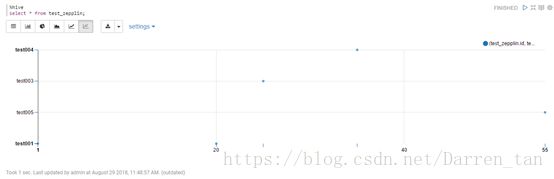
效果如下图:
表格
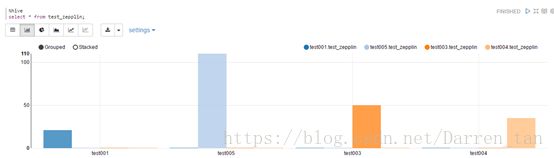
柱状图
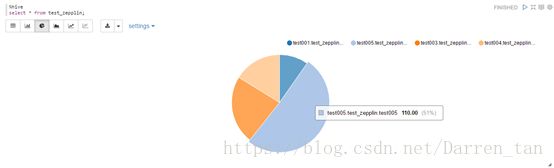
饼图
区间图
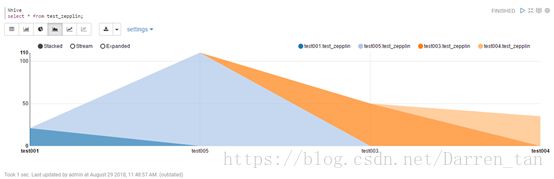
线形图
散点图
-
Spark
-
修改Interpreters
使用配置号的账号admin,登录Zeppelin系统,搜索出spark解释器。具体配置如下截图样式:
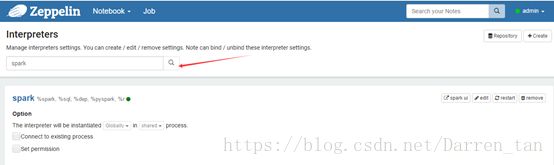
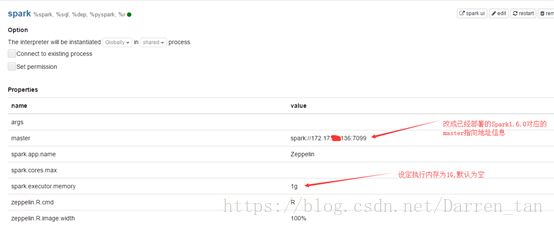
添加引入spark-1.6.0所需要的jar包

-
解释器特别说明
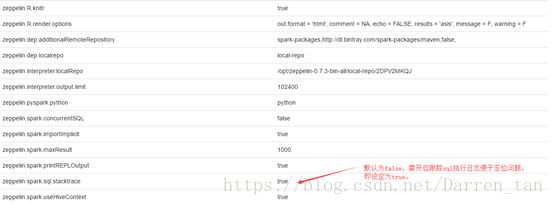
Spark解释器关键内容及依赖特别注释说明,具体如下表内容:
- Properties
| Property |
Default |
Description |
| args |
Spark commandline args |
|
| master |
local[*] |
Spark master uri. ex) spark://masterhost:7077 |
| spark.app.name |
Zeppelin |
The name of spark application. |
| spark.cores.max |
Total number of cores to use. Empty value uses all available core. |
|
| spark.executor.memory |
1g |
Executor memory per worker instance. ex) 512m, 32g |
| zeppelin.dep.additionalRemoteRepository |
spark-packages, |
A list of id,remote-repository-URL,is-snapshot; for each remote repository. |
| zeppelin.dep.localrepo |
local-repo |
Local repository for dependency loader |
| zeppelin.pyspark.python |
python |
Python command to run pyspark with |
| zeppelin.spark.concurrentSQL |
false |
Execute multiple SQL concurrently if set true. |
| zeppelin.spark.maxResult |
1000 |
Max number of Spark SQL result to display. |
| zeppelin.spark.printREPLOutput |
true |
Print REPL output |
| zeppelin.spark.useHiveContext |
true |
Use HiveContext instead of SQLContext if it is true. |
| zeppelin.spark.importImplicit |
true |
Import implicits, UDF collection, and sql if set true. |
- Dependencies
注:由于本次部署环境是CDH-5.13.3,且Spark为1.6.0版本,因此需要将依赖包引入部署的spark1.6.0下面lib中的相关包。
具体见spark解释器建立小节 Dependencies截图说明。
-
操作示例
1)、建立note,需要选择自己需要的解释器,此例我选择的是spark。其它详情见图示:
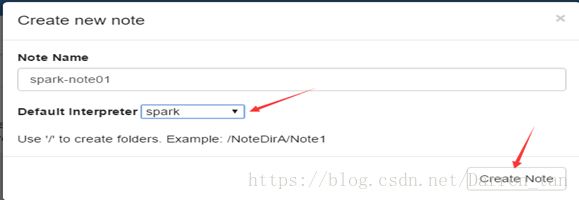
2)、在note中编辑自己需要完成查询或统计任务,如下图例查看服务器主机运行状况。
它支持表格、图形方式展示,同时支持导出csv\tsv。
3)、变化定义分组方式等信息,点击界面Settings按钮实现。拖拽变化定义keys、group和Values。
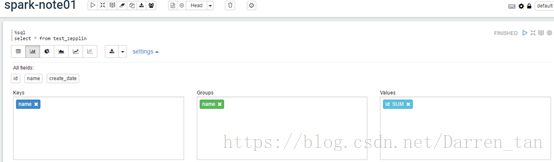
效果如下图:
表格
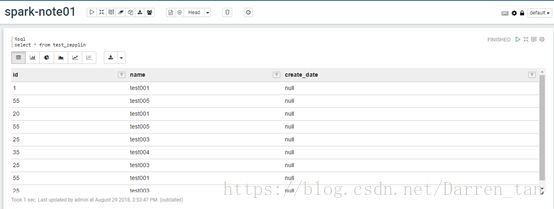
柱状图
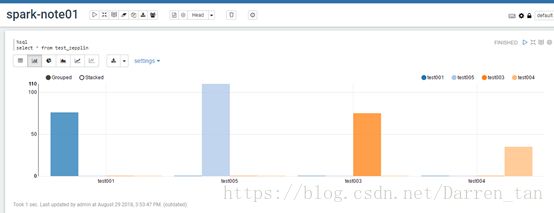
饼图
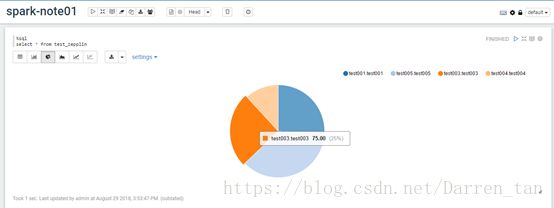
区间图
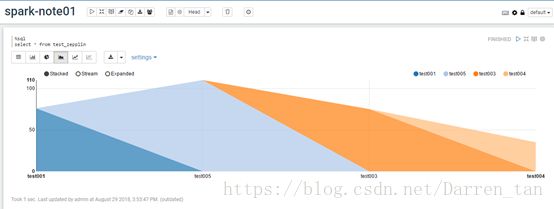
线形图
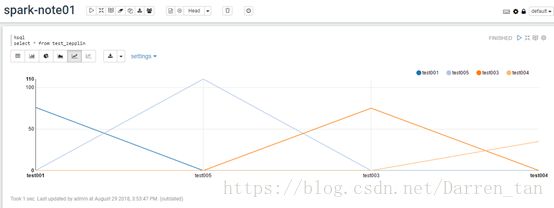
散点图
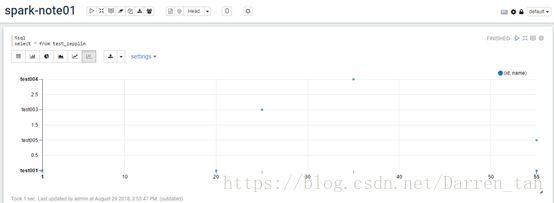
Note编辑器声明解释器对应类:
| Name |
Class |
Description |
| %spark |
SparkInterpreter |
Creates a SparkContext and provides a Scala environment |
| %spark.pyspark |
PySparkInterpreter |
Provides a Python environment |
| %spark.r |
SparkRInterpreter |
Provides an R environment with SparkR support |
| %spark.sql |
SparkSQLInterpreter |
Provides a SQL environment |
| %spark.dep |
DepInterpreter |
Dependency loader |
-
异常集锦
-
Hive解释器错误
【报错信息】定义访问hive下表数据,报
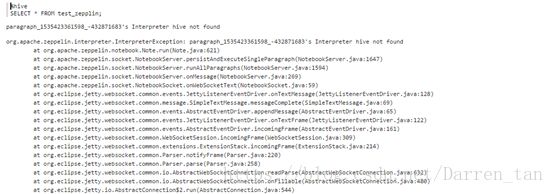
【原因分析】未定义有效访问的解释器,导致执行查询抛出没有找到hive解释器
【解决方法】重新定义创建有效访问hive的jdbc解释器,具体方法见4.4章节
【报错信息】访问hive下表数据,报
java.lang.NoSuchMethodError: org.apache.hive.service.auth.HiveAuthFactory.getSocketTransport
【原因分析】因为采用apache官网提供的jar包版本与当前环境部署的cdh所使用的hive相关版本不匹配,导致类的调用方法异常。
【解决方法】定义的解释器需要将官方指引的jar包更换成当前环境下所需要的相关jar包,如截图:
![]()
-
Spark解释器错误
【报错信息】运行带“;”符号时,出现org.apache.spark.sql.AnalysisException: cannot recognize input near 'test_zepplin' ';' '
【原因分析】在spark的note模式下,不支持带“;”
【解决方法】将执行sql语句中分号结束符号去掉,重新执行即可
由于时间关系,目前仅实现验证了工作中常用的数据源。在部署过程中参考了官方文档信息。希望此文能给有需要的人,起到一个抛砖引玉的作用。不足之处还望见谅。