Compressed Video Action Recognition论文笔记
Compressed Video Action Recognition论文笔记
这是一篇2018年的CVPR论文。做了关键内容的记录。对于细节要去论文中认真找。
摘要:训练一个稳定的视频表示比学习深度图像表示更加具有挑战性。由于原始视频的尺寸巨大,时间信息大量冗余,那些真正有用的信号通常被大量的无关数据淹没,通过视频压缩可以将信息量减少多达两个数量级。我们提出直接在神经网络上训练压缩的视频。这种表示的特征有更高的信息密度,训练起来更加简单。在动作识别的任务上,我们的方法优于UCF-101,HMDB-51和Charades数据集上的所有其他方法。
介绍:视频占据了百分之七十的互联网流量并且还在上升。大多数手机能能够捕捉到高分辨率的视频,而且真实世界的数据很多都是源于视频的,基于视频的计算机视觉是视觉领域的前沿,因为它捕获了静止图像无法传达的大量信息。 视频带来更多情感,让我们在一定程度上预测未来,提供时间背景并给予我们更好的空间意识。 不幸的是,目前很少有这些信息被利用。
最先进的用于视频分析的深度学习模型很基础,大部分人分析视频是设计卷积神经网络根据视频帧逐帧进行解析。得到的结果并不比手工制作的特征好,那么为什么没有直接应用在视频上的深度学习网络呢?我们认为有两个原因:首先因为一小时的720p的视频可以从222GB压缩到1GB,也就是说视频充满了无聊和重复,淹没了我们真正关注的信号。大量的冗余使CNN难以提取到有用的信息,并且还使训练变慢。其次,仅仅用RGB图像去学习时间结构是困难的。虽然大量的文献想把序列化的图像当做视频去处理,无论是使用2D CNN,3D CNN还是递归神经网络(RNN),但是只取得了很少的进步。使用预先计算的光学流程几乎总能提高性能。

为了解决这些问题,我们利用视频存储和传输中的压缩后的表示,而不是在RGB帧上运行(图1)。 这些压缩技术(如MPEG-4,H.264等)利用连续帧通常是相似的。 它仅保留几帧,并根据完整图像中的偏移(称为运动矢量和残差)重建其他帧。 我们的模型由多个CNN组成,这些CNN除了处理少量完整图像外,还直接对运动矢量,残差进行操作。这样的好处在于压缩视频可以消除多达两个数量级的信息,使有用的信息突出,其次视频压缩中的运动矢量为我们提供了单独的RGB图像所没有的运动信息。此外,运动矢量信号已经排除了空间变化,比如说穿不同的衣服,不同的光照强度,不同的人执行相同的动作,会表现出相同的运动信号。这将改善泛化能力。
主要的探究点有两个。一是把MP4视频格式中I-frame和P-frame的逐帧依赖方式给打破了,这样跟有利于网络的训练。另一个是探究多特征融合,特征上利用积累的Motion、Residual和I-frame 可以在UCF-101上达到90.8%的精度,远超I3D 84.5%的精度;再利用上光流可以达到94.9%,也优于I3D的 93.4%。在动作识别数据集UCF-101 [34],HMDB51 [18]和Charades [32]上,我们的方法显着优于传统RGB图像训练的所有其他方法。 我们的方法简单快速,无需使用RNN,复杂的融合或3D卷积。 它比现有的3D CNN模型Res3D [40]快4.6倍,比ResNet-152快12倍[12]。 当与标准时态流网络的分数结合使用时,我们的模型在所有这些数据集上都优于最先进的方法。
过去几年中深度学习为视频理解带来了重大的改进,但改进主要是对深度图像的表示。时间结构的建模仍然相对简单,大多数算法对视频帧进行下采样,执行平均池化等操作并进行预测,无论是CNN,RNN,时间CNN还是其他的特征融合技术,这些特征融合技术并不一定优于最简单的平均池化,而且还会引入额外的计算开销。
高效的视频存储和传输的需求导致了高效的视频压缩算法的出现。视频业所算法利用连续帧之间的相似性来有效的存储视频段中的一帧,而且只存储差异。大多数现代化的编码将视频分为I帧,P帧和B帧(双向帧)三个部分,I-frames就是正常的原始图片,压缩后不变;P-frames以上一帧为基础,记录本帧的变化值,和B帧(双向帧。)P-frames分两个部分,一个部分是motion vector,就是指的是作参考的帧到t时刻的target frame的像素区块(block of pixels)的移动,用![]() 表示,这个motion vector表示的是粗略的移动,因此source frame(参考帧)加上motion vector之后并不能得到和target frame完全一样的结果,和target frame真实值之间的差距,称为residual difference(残差),用
表示,这个motion vector表示的是粗略的移动,因此source frame(参考帧)加上motion vector之后并不能得到和target frame完全一样的结果,和target frame真实值之间的差距,称为residual difference(残差),用![]() 标记。这里给出了从建P帧的递推关系。
标记。这里给出了从建P帧的递推关系。

对于所有像素i,其中I(t)表示时间t处的RGB图像。运动矢量和残差通过离散余弦变换(DCT)和熵编码。
视频压缩中,每帧代表一幅静止的图像。而在实际压缩时,会采取各种算法减少数据的容量,其中IPB就是最常见的。 I 帧表示关键帧,H.264中称作帧内编码帧,你可以理解为这一帧画面的完整保留;解码时只需要本帧数据就可以完成(因为包含完整画面)。P帧表示的是这一帧跟之前的一个关键帧(或P帧)的差别,解码时需要用之前缓存的画面叠加上本帧定义的差别,生成最终画面。(也就是差别帧,P帧没有完整画面数据,只有与前一帧的画面差别的数据)。B帧是双向差别帧,也就是B帧记录的是本帧与前后帧的差别(具体比较复杂,有4种情况,但我这样说简单些,有兴趣去搜H.264标准的编码环节),换言之,要解码B帧,不仅要取得之前的缓存画面,还要解码之后的画面,通过前后画面的与本帧数据的叠加取得最终的画面。B帧压缩率高,但是解码时CPU会比较累~。
图二可视化了运动矢量估计和残差。
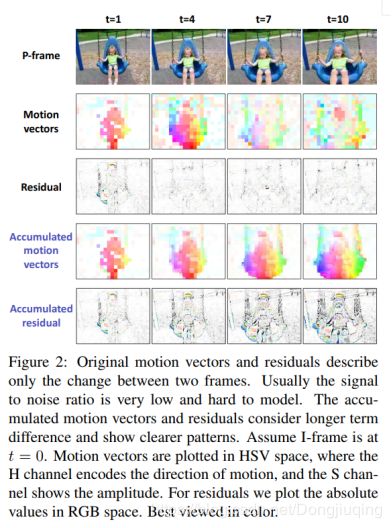

原始运动矢量和残差只描述两个帧之间的变化。通常信噪比很低,难以建模。 累计的运动矢量和残差会考虑较长期的差异并显示更清晰的图案。在HSV空间中绘制运动矢量,H通道编码运动方向,S通道表示振幅。对于残差,我们在RGB空间中绘制真实帧预测帧灰度值差的绝对值。右图为HSV颜色空间图。HSV是一种将RGB色彩空间中的点在倒圆锥体中的表示方法。HSV即色相(Hue)、饱和度(Saturation)、明度(Value),又称HSB(B即Brightness)。色相是色彩的基本属性,就是平常说的颜色的名称,如红色、黄色等。饱和度(S)是指色彩的纯度,越高色彩越纯,低则逐渐变灰,取0-100%的数值。明度(V),取0-max(计算机中HSV取值范围和存储的长度有关)。HSV颜色空间可以用一个圆锥空间模型来描述。圆锥的顶点处,V=0,H和S无定义,代表黑色。圆锥的顶面中心处V=max,S=0,H无定义,代表白色。RGB颜色空间中,三种颜色分量的取值与所生成的颜色之间的联系并不直观。而HSV颜色空间,更类似于人类感觉颜色的方式,封装了关于颜色的信息:“这是什么颜色?深浅如何?明暗如何?
我们重点讨论如何用压缩表示,去掉重复的信息后用于行为识别。
Modeling Compressed Representations压缩表示建模
我们的目标是设计一个计算机视觉系统,可以直接对压缩视频进行操作。
将I帧视频直接输入深层网络很简单,因为这些是正常的图像,以前有很多工作做的都是将视频帧送入神经网络,不做重点解释,图二可视化了运动矢量,看起来是类似于光流的图像,我们知道,光流已经被证明对行为识别是有效的(之前有许多利用光流搞行为识别的论文),因此我们想要利用P帧,想知道有没有效果。图二的第三行显示了预测镇与真实之间的差距,我们称之为残差,它大致给出了一个运动的边界,既然是图片,那么CNN同样非常适合这种图像的处理,输入图像、运动矢量和残差,相应的CNN的输出会有不同的特征。为了融合这几种特征,我们在中间层和最后一层尝试了各种融合方法。如平均池化、最大池化、卷积池化、双线性池化,但效果一般。
因此作者思考为什么效果一般呢?下面是结论,运动矢量和残差并不包含P帧的全部信息。P帧取决于参考帧(即 I 帧),也取决于其他P帧,这条链一直延续到前一个I帧,独立的让CNN观察每个P帧则违反了P帧之间的依赖性。(估计是在说丢失了依赖性则不能得到有用的信息,因为每一个P帧都是基于上一帧的变化图像),但我们知道P帧类似于光流图像,因此想要利用P帧这些图像,作者设计了一种新颖而简单的回溯技术back-tracing technique,对P帧解耦合。(解耦合即解除p帧之间的相互依赖性)
解耦模型:

为了打破P帧之间的依赖性,我们将所有的运动矢量追溯到参考帧I帧,并在这个过程中累计残差,这样每个P帧就只依赖于I帧而不依赖于其他P帧。
t帧的位置i的像素,用代表前一帧的参考位置(referenced location),对于k
![]()
在第t帧的累计运动矢量和残差分别计算如下:通过简单的前馈算法,当编码视频时积累的运动矢量和残差可以被有效的计算。

每一个P帧现在有了一个不同的依赖关系。

图4中的P帧只依赖于I帧,并且可以并行处理。

提出网络模型:图五展示了所提出的模型的图解:模型的输入是I帧,接着是T个P帧。我们输入的每一个I帧将t设为0,并用CNN建模。


I帧的特征按常规步骤进行打分,P帧的特征需要融合运动矢量特征和残差特征的信息。比如最大池化、卷积池化、平均池化等融合方法。 我们发现了一个简单的分数总和就能达到最佳效果, 这为我们提供了一个易于训练和灵活推理的模型。
结论:本文提出了一种直接用压缩视频训练的深度网络,作者受到的启发源于观察:我们可以从多个途径直接获得压缩好的视频,比如手机相机,或者大部分视频都是以压缩的方式直接获得的,也就是说获得解压缩的视频是不方便的。而且证明了用压缩视频不是一种缺点而是有点,毕竟压缩并不意味着影响人类理解视频相关内容,其次就是增加了相关性和降低维数使得计算更加有效。