java8新特性(二):StreamAPI
-
-
- 了解Stream
- 什么是Stream
- Stream 的操作三个步骤
- 1.创建流
- 2.Stream的中间操作
- 3.Stream的终止操作
- 并行流与串行流
- 了解Fork/Join 框架
- Fork/Join 框架与传统线程池的区别
-
了解Stream
Java8中有两大最为重要的改变。第一个是Lambda 表达式;另外一个则是Stream API(java.util.stream.*)。
Stream 是Java8 中处理集合的关键抽象概念,它可以指定你希望对集合进行的操作,可以执行非常复杂的查找、过滤和映射数据等操作。使用Stream API 对集合数据进行操作,就类似于使用SQL 执行的数据库查询。也可以使用Stream API 来并行执行操作。简而言之,Stream API 提供了一种高效且易于使用的处理数据的方式。
什么是Stream
是数据渠道,用于操作数据源(集合、数组等)所生成的元素序列。“集合讲的是数据,流讲的是计算!”
注意:
①Stream 自己不会存储元素。
②Stream 不会改变源对象。相反,他们会返回一个持有结果的新Stream。
③Stream 操作是延迟执行的。这意味着他们会等到需要结果的时候才执行。
Stream 的操作三个步骤
1.创建Stream
一个数据源(如:集合、数组),获取一个流
2.中间操作
一个中间操作链,对数据源的数据进行处理
3.终止操作(终端操作)
一个终止操作,执行中间操作链,并产生结果

1.创建流
- 集合
Java8 中的 Collection 接口被扩展,提供了两个获取流的方法:
- 1.default Stream stream() : 返回一个顺序流
- 2.default Stream parallelStream() : 返回一个并行流
数组
Java8 中的 Arrays 的静态方法 stream() 可以获取数组流:- static Stream stream(T[] array): 返回一个流
- 重载形式,能够处理对应基本类型的数组:
- public static IntStream stream(int[] array)
- public static LongStream stream(long[] array)
- public static DoubleStream stream(double[] array)
由值创建流
可以使用静态方法 Stream.of(), 通过显示值创建一个流。它可以接收任意数量的参数。- public static Stream of(T… values) : 返回一个流
由函数创建流:创建无限流
- 迭代:
public static Stream iterate(final T seed, final UnaryOperator f) - 生成:
public static Stream generate(Supplier s)
示例代码:
- 迭代:
public class Employee implements Comparable<Employee>{
private String name;
private Integer age;
private Double salary;
private Status status;
public enum Status{
FREE(0,"空闲"),
BUSY(1,"忙碌"),
WAIT(2,"等待");
Status(int num, String value) {
}
}
.....................................
}
public class TestStreamAPI01 {
/**
* @Description: 创建流
* @date: 2018/8/14
* @param:
* @return:
*/
@Test
public void test1 (){
//1·可以通过Collection系列集合提供的Stream()或者parallelStream()
List list = new ArrayList<>();
Stream stream1 = list.stream();
//2·通过Arrays中的静态方法stream()获取数组流
Employee[] emps = new Employee[30];
Stream stream2 = Arrays.stream(emps);
//3·通过Stream类中的静态方法of()
Stream stream3 = Stream.of(12, 23, 232);
//4·创建无限流
//①迭代
Stream stream4 = Stream.iterate(0, x -> x + 2);
stream4.limit(10).forEach(System.out::println);
//②生成
Stream stream5 = Stream.generate(() -> new Random().nextDouble());
stream5.limit(20).forEach(System.out::println);
}
} 2.Stream的中间操作
多个中间操作可以连接起来形成一个流水线,除非流水线上触发终止操作,否则中间操作不会执行任何的处理!
而在终止操作时一次性全部处理,称为“惰性求值”。
- 筛选与切片
| 方法 | 描述 |
|---|---|
| filter(Predicatep) | 接收Lambda ,从流中排除某些元素。 |
| distinct() | 筛选,通过流所生成元素的hashCode() 和equals() 去除重复元素 |
| limit(long maxSize) | 截断流,使其元素不超过给定数量。 |
| skip(long n) | 跳过元素,返回一个扔掉了前n 个元素的流。若流中元素不足n 个,则返回一个空流。与limit(n) 互补 |
- 映射
| 方法 | 描述 |
|---|---|
| map(Functionf) | 接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。 |
| mapToDouble(ToDoubleFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的DoubleStream。 |
| mapToInt(ToIntFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的IntStream。 |
| mapToLong(ToLongFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的LongStream。 |
| flatMap(Function f) | 接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流 |
- 排序
| 方法 | 描述 |
|---|---|
| sorted() | 产生一个新流,其中按自然顺序排序 |
| sorted(Comparatorcomp) | 产生一个新流,其中按比较器顺序排序 |
代码:
/**
* @Description:
* 一·Stream的三个操作步骤:
* 1·创建Stream
* 2·中间操作
* 3·终止操作(终端操作)
* 注意:
* ①Stream 自己不会存储元素。
* ②Stream 不会改变源对象。相反,他们会返回一个持有结果的新Stream。
* ③Stream 操作是延迟执行的。这意味着他们会等到需要结果的时候才执行。
* @author: Bryce
* @date: 2018/8/14
* @version: 1.0
*/
public class TestStreamAPI02 {
List employees = Arrays.asList(
new Employee("张三",22,3434.0),
new Employee("李四", 21, 43534.0),
new Employee("王二",23,3422.3),
new Employee("牛五", 19, 5012.23),
new Employee("田七",18,4645.98),
new Employee("田七",28,4645.98),
new Employee("田七",19,4645.98),
new Employee("田七",21,4645.98)
);
//中间操作
/**
* 筛选和切片
* filter-接受Lambda,从流中排除某些元素
* limit-截断流,使其元素不超过给定数量
* skip(n)-跳过元素,返回一个扔掉了前n个元素的流.若流中元素不足n个,
* 则返回一个空流.与limit(n)互补.
* distinct-筛选,通过流所产生元素的hashcode和equals去除重复元素
*/
/**内部迭代(使用 Collection 接口需要用户去做迭
代,称为外部迭代。相反, Stream API 使用内部
迭代——它帮你把迭代做了)
*/
/**
* @Description: filter
* @date: 2018/8/14
* @param:
* @return:
*/
@Test
public void test1 (){
Stream stream = employees.stream()
.filter((e) -> {
System.out.println("过滤!");
return e.getAge() < 20;});
stream.forEach(System.out::println);
}
/**
* @Description: limit
* @date: 2018/8/14
* @param:
* @return:
*/
@Test
public void test2 (){
employees.stream()
.filter((e) -> {
System.out.println("过滤!");
return e.getSalary() > 4000.0;})
.limit(2)
.forEach(System.out::println);
}
/**
* @Description: skip
* @date: 2018/8/14
* @param:
* @return:
*/
@Test
public void test3 (){
employees.stream()
.filter((e) -> {
System.out.println("过滤!");
return e.getSalary() > 4000.0;})
.skip(2)
.forEach(System.out::println);
}
/**
* @Description: distinct
* @date: 2018/8/14
* @param:
* @return:
*/
@Test
public void test4 (){
employees.stream()
.filter((e) -> {
System.out.println("过滤!");
return e.getSalary() > 4000.0;})
.skip(2)
.distinct()
.forEach(System.out::println);
}
/**
* 映射
* map-接收Lambda,该函数会被应用到每个元素上,并将其映射成一个新的元素。
* flatMap-接收Lambda,将流中的每个值都换成另一个流,然后把所有流连接成一个流
*/
/**
* @Description: map
* @date: 2018/8/14
* @param:
* @return:
*/
@Test
public void test5 (){
List list = Arrays.asList("aa", "bb", "cc", "dd");
list.stream().map(String::toUpperCase)
.forEach(System.out::println);
System.out.println(">>>>>>>>>>>>>>>>>>>>>");
employees.stream()
.map(Employee::getName)
.distinct()
.forEach(System.out::println);
}
/**
* @Description: flatMap
* @date: 2018/8/14
* @param:
* @return:
*/
@Test
public void test6 (){
List list = Arrays.asList("aa", "bb", "cc", "dd");
list.stream()
.flatMap((str)->{
List li = new ArrayList<>();
for (char c : str.toCharArray()) {
li.add(c);
}
return li.stream();
}).distinct()
.forEach(System.out::println);
}
//排序
/**
* sorted()-产生一个新流,其中按自然顺序排序
* sorted(Comparator comp)-产生一个新流,其中按比较器顺序排序
*/
/**
* @Description:
* @date: 2018/8/14
* @param:
* @return:
*/
@Test
public void test7 (){
employees.stream().sorted((x,y)->x.getAge()-y.getAge()==0?x.getName().compareTo(y.getName()):x.getAge()-y.getAge())
.forEach(System.out::println);
System.out.println(">>>>>>>>>>>");
employees.stream().sorted()
.forEach(System.out::println);
}
}
3.Stream的终止操作
终端操作会从流的流水线生成结果。其结果可以是任何不是流的值,例如:List、Integer,甚至是void 。
- 查找与匹配
| 方法 | 描述 |
|---|---|
| allMatch(Predicate p) | 检查是否匹配所有元素 |
| anyMatch(Predicate p) | 检查是否至少匹配一个元素 |
| noneMatch(Predicatep) | 检查是否没有匹配所有元素 |
| findFirst() | 返回第一个元素 |
| findAny() | 返回当前流中的任意元素 |
| count() | 返回流中元素总数 |
| max(Comparatorc) | 返回流中最大值 |
| min(Comparatorc) | 返回流中最小值 |
| forEach(Consumerc) | 内部迭代(使用Collection 接口需要用户去做迭代,称为外部迭代。相反,Stream API 使用内部迭代——它帮你把迭代做了) |
- 规约
| 方法 | 描述 |
|---|---|
| reduce(T iden, BinaryOperator b) | 可以将流中元素反复结合起来,得到一个值。返回T |
| reduce(BinaryOperator b) | 可以将流中元素反复结合起来,得到一个值。返回Optional |
备注:map 和reduce 的连接通常称为map-reduce 模式,因Google 用它来进行网络搜索而出名。
- 收集
| 方法 | 描述 |
|---|---|
| collect(Collector c) | 将流转换为其他形式。接收一个Collector接口的实现,用于给Stream中元素做汇总的方法 |
Collector 接口中方法的实现决定了如何对流执行收集操作(如收集到List、Set、Map)。但是Collectors 实用类提供了很多静态方法,可以方便地创建常见收集器实例,具体方法与实例如下表:


示例代码:
/**
* @Description: 终止操作
*终端操作会从流的流水线生成结果。其结果可以是任何不是流的
值,例如: List、 Integer,甚至是 void 。
* @author: Bryce
* @date: 2018/8/14
* @version: 1.0
*/
public class TestStreamAPI03 {
List employees = Arrays.asList(
new Employee("张三",37,3434.0, Employee.Status.BUSY),
new Employee("李四", 21, 43534.0,Employee.Status.FREE),
new Employee("王二",52,3422.3, Employee.Status.WAIT),
new Employee("牛五", 19, 5012.23, Employee.Status.FREE),
new Employee("田七",60,4645.98, Employee.Status.FREE)
);
/**查找与匹配:
* allMatch(Predicate p) 检查是否匹配所有元素
anyMatch(Predicate p) 检查是否至少匹配一个元素
noneMatch(Predicate p) 检查是否没有匹配所有元素
findFirst() 返回第一个元素
findAny() 返回当前流中的任意元素
count() 返回流中元素总数
max(Comparator c) 返回流中最大值
min(Comparator c) 返回流中最小值
forEach(Consumer c) 内部迭代
*/
@Test
public void test1 () {
boolean allMatch = employees.stream().
allMatch(employee -> employee.getStatus().equals(Employee.Status.BUSY));
System.out.println(allMatch);
boolean anyMatch = employees.stream().
anyMatch(employee -> employee.getStatus().equals(Employee.Status.BUSY));
System.out.println(anyMatch);
boolean noneMatch = employees.stream().
noneMatch(employee -> employee.getStatus().equals(Employee.Status.BUSY));
System.out.println(noneMatch);
Optional optional = employees.stream()
.sorted(Comparator.comparingDouble(Employee::getSalary))
.findFirst();
System.out.println(optional.get());
Optional employeeOptional = employees.stream().filter(employee -> employee.getStatus().equals(Employee.Status.FREE))
.findAny();
System.out.println(employeeOptional.get());
long count = employees.stream().filter(employee -> employee.getStatus().equals(Employee.Status.FREE))
.count();
System.out.println(count);
Optional max = employees.
stream()
.map(Employee::getSalary).max(Double::compareTo);
System.out.println(max.get());
}
/**
* 规约:
* reduce(T iden, BinaryOperator b) 可以将流中元素反复结合起来,得到一个值返回 T
reduce(BinaryOperator b) 可以将流中元素反复结合起来,得到一个值。
返回 Optional
*/
@Test
public void test2 (){
List list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
Integer sum = list.stream().reduce(0, Integer::sum);
System.out.println(sum);
Integer max = list.stream().reduce(0, Integer::max);
System.out.println(max);
Optional reduce = list.stream()
.reduce(Integer::max);
System.out.println(reduce.get());
}
/**
* 收集:
* collect(Collector c) 将流转换为其他形式。接收一个 Collector接口的
* 实现,用于给Stream中元素做汇总的方法,
* Collector 接口中方法的实现决定了如何对流执行收集操作(如收集到 List、 Set、 Map)。
* Collectors 实用类提供了很多静态方法,可以方便地创建常见收集器实例
*/
@Test
public void test3() {
//转换为list
List list = employees.stream()
.map(Employee::getAge)
.collect(Collectors.toList());
System.out.println(list);
System.out.println(">>>>>>>>>>>>");
//转换为hashSet
HashSet hashSet = employees.stream()
.map(Employee::getName)
.collect(Collectors.toCollection(HashSet::new));
hashSet.forEach(System.out::println);
}
/**
* @Description: 多级分组
* @date: 2018/8/14
* @param:
* @return:
*/
@Test
public void test4 (){
Map>> map = employees.stream()
.collect(Collectors.groupingBy(Employee::getStatus, Collectors.groupingBy((e) -> {
if (e.getAge() <= 35) {
return "青年";
} else if (e.getAge() <= 50) {
return "中年";
} else {
return "老年";
}
})));
System.out.println(map);
}
@Test
public void test7(){
Map> map = employees.stream().collect(Collectors.partitioningBy((e) -> e.getSalary() >= 5000));
System.out.println(map);
}
@Test
public void test8(){
String str = employees.stream()
.map(Employee::getName)
.collect(Collectors.joining("," , "----", "----"));
System.out.println(str);
}
@Test
public void test9(){
Optional sum = employees.stream()
.map(Employee::getSalary)
.collect(Collectors.reducing(Double::sum));
System.out.println(sum.get());
}
}
并行流与串行流
并行流就是把一个内容分成多个数据块,并用不同的线程分别处理每个数据块的流。
Java 8 中将并行进行了优化,我们可以很容易的对数据进行并行操作。Stream API 可以声明性地通过parallel() 与sequential() 在并行流与顺序流之间进行切换。
了解Fork/Join 框架
Fork/Join 框架:就是在必要的情况下,将一个大任务,进行拆分(fork)成若干个小任务(拆到不可再拆时),再将一个个的小任务运算的结果进行join 汇总.
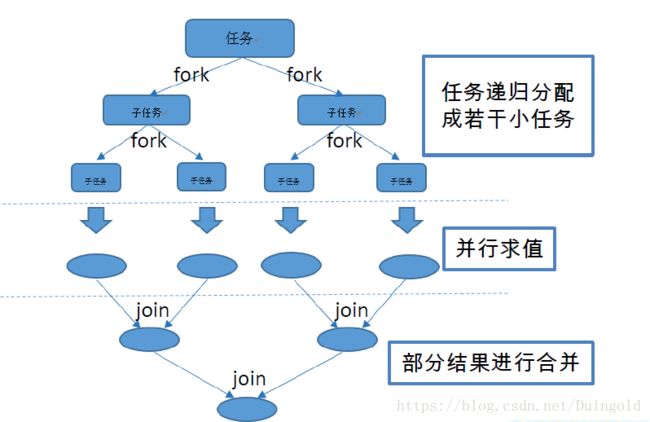
Fork/Join 框架与传统线程池的区别
采用“工作窃取”模式(work-stealing):
当执行新的任务时它可以将其拆分分成更小的任务执行,并将小任务加到线程队列中,然后再从一个随机线程的队列中偷一个并把它放在自己的队列中。
相对于一般的线程池实现,fork/join框架的优势体现在对其中包含的任务的处理方式上.在一般的线程池中,如果一个线程正在执行的任务由于某些原因无法继续运行,那么该线程会处于等待状态.而在fork/join框架实现中,如果某个子问题由于等待另外一个子问题的完成而无法继续运行.那么处理该子问题的线程会主动寻找其他尚未运行的子问题来执行.这种方式减少了线程的等待时间,提高了性能.
代码示例:
public class ForkJoinCalculate extends RecursiveTask<Long>{
/**
*
*/
private static final long serialVersionUID = 13475679780L;
private long start;
private long end;
private static final long THRESHOLD = 10000L; //临界值
public ForkJoinCalculate(long start, long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
long length = end - start;
if(length <= THRESHOLD){
long sum = 0;
for (long i = start; i <= end; i++) {
sum += i;
}
return sum;
}else{
long middle = (start + end) / 2;
ForkJoinCalculate left = new ForkJoinCalculate(start, middle);
left.fork(); //拆分,并将该子任务压入线程队列
ForkJoinCalculate right = new ForkJoinCalculate(middle+1, end);
right.fork();
return left.join() + right.join();
}
}
}public class TestForkJoin {
@Test
public void test1(){
long start = System.currentTimeMillis();
ForkJoinPool pool = new ForkJoinPool();
ForkJoinTask task = new ForkJoinCalculate(0L, 10000000000L);
long sum = pool.invoke(task);
System.out.println(sum);
long end = System.currentTimeMillis();
System.out.println("耗费的时间为: " + (end - start));
}
@Test
public void test2(){
long start = System.currentTimeMillis();
long sum = 0L;
for (long i = 0L; i <= 10000000000L; i++) {
sum += i;
}
System.out.println(sum);
long end = System.currentTimeMillis();
System.out.println("耗费的时间为: " + (end - start));
}
@Test
public void test3(){
long start = System.currentTimeMillis();
Long sum = LongStream.rangeClosed(0L, 10000000000L)
.parallel()
.sum();
System.out.println(sum);
long end = System.currentTimeMillis();
System.out.println("耗费的时间为: " + (end - start));
}
}
java8新特性(一):Lambda表达式
java8新特性(三):新时间日期API