storm详解
组成
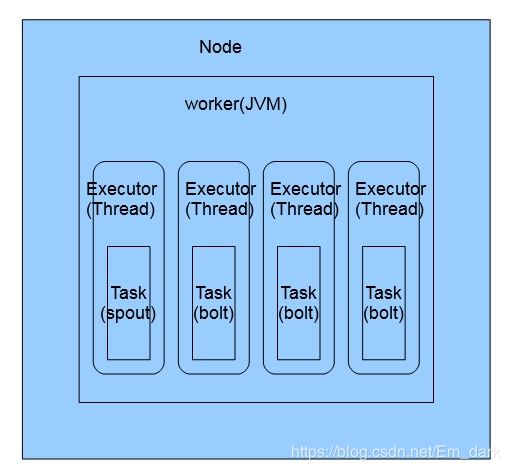
Storm分布式计算结构
topology(拓扑)
stream(数据流)
spout(数据流的生成者)
bolt(运算)
Storm topology会一直运行下去,除非进程被杀死或被取消部署
stream
核心数据结构是tuple.
tuple是包含了一个或者多个键值对的列表.
stream是无限制的tuple组成的序列
spout
spout代表了Storm topology的数据入口,
充当采集器的角色,将数据转化成一个个tuple,并将tuple 作为数据流发射
bolt
可以理解为函数,可以将一个或多个数据流作为输入,实施运算后,选择性输出一个或多个数据流,bolt可以订阅多个由spout或者其他bolt发射的数据流, 常用的功能是过滤,连接,聚合,计算,数据库读写.
并发机制
Nodes(服务器)
指配置在storm集群中的服务器,执行topology的一部分运算,一个集群可以有一个或多个node
workers(jvm虚拟机)
指一个node上相互独立运行的jvm进程,每个Node可以配置一个或多个worker,一个topology可以分到一个或多个worker上运行
Executeor(线程)
指一个worker的jvm进程中运行的java线程,多个task可以指派给同一个executor来执行,默认每个excutor一个task
task (blot/spout实例)
task 是spout 和blot 的实例,他们的nexttuple()和execute()方法会被exector线程调用执行
增加并行度
增加work
Config config=new Config();
config.setNumworkers(2);
配置executor和task
默认每个组件建立一个task,storm API提供了控制方法,允许设定每个task对应的executor 个数和每个excutor执行的task数
//指定excutor的数量
build.setSpout(SENTENCE_SPOUT_ID,spout,2);
//指定2个线程执行4个Tasks 每个线程2个Task
build.setBlot(SPLIT_BOLT_ID,splitBolt,2).setNumTasks(4)
数据流分组
shuffle grouping (随机分组)
随机分发tuple 给bolt的不同task 每个bolt接受到相同的tuple
fields grouping (字段分组)
按照指定字段分组,比如一个数据流根据"word" j进行分组所有具有相同"word"字段值的tuple会路由到同一个bolt的task中
all grouping (全复制分组)
所有的tuple 复制后分发给所有的bolt,每个订阅数据流的task都会受到tuple的拷贝
globle grouping (全局分组)
将所有tuples路由到唯一一个task上 默认按照task_id最小的来 (因为所有tuples都发在一个jvm来了,所以要注意性能问题)
None grouping (不分组)
与随机分组相同,
direct grouping (指向性分组)
数据源调用 emitdirect()来判断由哪个组件接受 只能在声明了指向性的数据流上使用
locol or shuffle grouping (本地或随机分组)
与随机分组类似,但是会将tuple 分发给同一个worker内的bolt task(如果有) (本地分发可以减少网络传输,从而提高topology性能)
注意:避免在bolt里面储存数据,当bolt异常或重启时,数据会丢失,定时对存储信息进行持久化比较好
保障机制
spout可靠性
spout发出的tuple是原始主干,接下来的是tuple数,blot每次收到一个tuple都需要向上游确认应答ack如果这个tuple树的每个bolt都进行了确认spout会调用ack()来标记这个消息已经完全处理了,任何一个报错或超时spout都会调用fail()
//发送要加上msgid
colleter.emit(new Values("valu1","vlue2"),msgId)
bolt可靠性
1.需要锚定一个tuple,需要锚定读入的tuple
建立读入tuple和衍生tuple的关系
collector.emit(tuple,new Values(word));//绑定关系
this.collector.ack(tuple);//进行回应
this.collector.fail(tuple);//失败了也要进行回应
2.消息处理成功或者失败分别给出明确的应答或报错
ConcurrentHashMap pending;//spout声明一下
this.pending = new ConcurrentHashMap();//open()方法中初始化
UUID msgid = UUID.randomUUID();
this.pending.put(msgid,new Values(sentence[index]));
this.collector.emit(new Values(sentence[index]),msgid);//发射的时候带上msgid
//确认了就移除
@Override
public void ack(Object msgId) {
this.pending.remove(msgId);
}
//失败了就重新发送
@Override
public void fail(Object msgId) {
this.pending.remove(this.pending.get(msgId),msgId);
}
//bolt 里处理成功需要ack()
this.outputCollector.ack(tuple);
部署
在linux安装
安装java
安装zookeeper,storm需要3.3.X版本及以上的
安装storm Storm官网下载 然后解压
运行storm守护进程
nohup ./storm nimbus >/dev/null 2>&1 & #启动nimbus
nohup ./storm drpc >/dev/null 2>&1 & #启动drpc
nohup ./storm supervisor >/dev/null 2>&1 & #启动supervisor
nohup ./storm ui >/dev/null 2>&1 & #启动ui
配置storm
storm 的配置由yaml格式组成
在/conf目录下有个storm.yaml
必须得配置项
storm.zookeeper.serviers
此项列出了zookeeper集群的主机名称,默认Localhost
nimbus.host
指定集群中的nimbus节点,woker需要知道集群的主节点在哪里,以便用于下载topology的jar和配置项
supervisor.slots.ports
配置控制每个supervisor运行多少个worker如果集群有三个supervisor节点,
每个节点配置3个监听端口整个集群就有3*3=9个woker插槽,默认使用6700~6703端口每个supervisor节点有4个worker插槽
storm.local.dir
nimbus和supervisor都会储存一些短暂的状态信息,jar或者worker需要的配置文件,这个目录必须存在.不要用/tmp(重启清空) 可以自己制定为/storm/local
可选配置
这里有一份默认的1.0.6版默认配置文件,详细可以点击查看
有一些常用参数需要重新定义的
nimbus.childopts:(default:"-Xms1024m") #这项JVM配置会添加在启动nimbus守护进程的java命令中
ui.childopts:(default:"-Xms1024m")
supervisor.childopts:(default:"-Xms1024m")
worker.childopts:(default:"-Xms1024m")
ui.port:(default:"8080")
topology.message.timeout.secs:(default:"30") #这项设定了tuple树需要应答最大时间的秒数限制,超过
#这个时间认为已经执行失败,太小可能会导致tuple从新发送
topology.max.spout.pending:(default:"null") #默认为null的时候,spout产生了tuple,就会立即发送,
可能会导致下游开始过载,从而导致消息处理超时,如果设为100,storm 会暂停发送tuple知道发送出去的
tuple小于100,起到对spout限速的作用,和上面的timeout是调节topology性能最终要的两个参数
配置host的时候,使用IP,比DNS更好.
管理命令
storm jar topology_jar topology_class [args..]
jar 命令用来想集群提交jar 他会以指定参数运行topology_class中的Main()方法,同时上传topology_jar文件到
nimbus分发到整个集群 topology类中main()方法需要调用stormsubmitter.submitTopplogy()方法,如果有同名的
topology jar命令会失败,通常通过命令行参数形式制定topology名称,这样可以在提交时重命名
storm kill topology_name[-w wait_time]
用来杀掉关闭已经部署了的topology
storm deactivate topology_name
停止特定的topology的spout发送tuple
storm activate topology_name
恢复特定的topology的spout发送tuple
storm rebalance topology_name
重新平均分配任务,不需要关闭或者重新提交现有topology
storm rebalance wordcount-topology -w 15 -n 5 -e sentence-spout=4 -e split-bolt=8
等待15秒后重新平衡wordcount-topology 指定5个worker
设置sentence-spout 使用4个线程 split-bolt使用8个线程
为了方便调试,在本地和集群之间切换推荐使用一个if/else判断语句,如果带参则是集群,不带参就是本地的模式
推荐了解一下puppet 一个自动化的IT框架,帮助管理员大规模的网络设施资源,使用灵活的显示声明.