深入理解one-stage目标检测算法(下篇)
前言
本文翻译自One-shot object detection,原作者保留版权,略有删减。
数据
有很多常用的目标检测训练数据集,如Pascal VOC, COCO, KITTI。这里我们关注Pascal VOC,因为它是最常用的,并且YOLO使用了它。
VOC数据集包含图像和不同任务的标注,这里我们仅关注目标检测的标注,共有20个类别:
aeroplane bicycle bird boat bottle
bus car cat chair cow
diningtable dog horse motorbike person
pottedplant sheep sofa train tvmonitor
VOC数据集附带一个建议的训练/验证集分割,大约为50/50。由于数据集不太大,因此将50%的数据用于验证似乎有点浪费。因此,通常将训练集和验证集组合成一个大的训练集“trainval”(总共16551张图像),然后随机选取10%左右的图像用于验证。可以在2007测试集上测试模型,因为label已经给出。还有一个2012年的测试集,但label是不公开的(也有习惯于将2007年测试集包括在训练数据中,数据越多越好)。
2007+2012组合训练集有8218个带物体框标注的图像,验证集有8333个图像,2007测试集有4952个图像。这比ImageNet的130万张图片要少得多,所以最好使用迁移学习,而不是从头开始训练模型。这就是为什么我们从一个已经在ImageNet上预训练过的特征提取器开始。
标注
标注描述了图像中的内容。简而言之,标注提供了我们训练所需的目标。标注采用XML格式,每个训练图像一个。标注文件包含一个或多个带有类名称的部分:用xmin、xmax、ymin、ymax描述的边界框以及每个object的一些其他属性。如果一个物体被标为difficult,我们将忽略它,这些通常是非常小的物体,它们也被VOC竞赛的官方评估指标忽略。以下是标注文件示例,voc2007/annotations/003585.xml:
VOC2007
003585.jpg
The VOC2007 Database
PASCAL VOC2007
flickr
304100796
Huw Lambert
huw lambert
333
500
3
这个图片大小为333×500,包含两个物体:人和摩托车。没有被标注为difficult或者truncated (部分在图像外).
注意:Pascal VOC数据集坐标从1开始,而不是0,也许是采用MATLAB的格式。
我们可以画出这个图像的各个物体的边界框:

VOC2007和2012共包含如下的图像:
dataset images objects
train 8218 19910
val 8333 20148
test 4952 12032 (2007 only)
约有一半的图像仅有一个物体,其它的包含1个以上,下面是训练集统计的直方图:
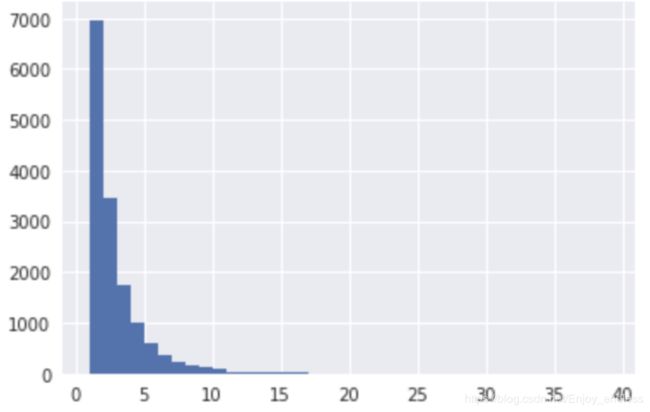
一张图片中最大物体数为39,验证集和测试集的直方图大致类似。同样地,我们给出训练集中所有物体区域大小的直方图(长和宽归一化到[0,1]):

可以看到许多物体相对较小。峰值为1.0是因为有相当多的物体大于图像(例如,只有部分可见的人),因此边界框填充整个图像。这里还有另一种方法来查看这些数据:边界框宽度与高度的关系图。图中的“坡度”显示框的高宽比。

数据扩增
由于数据集相当小,在训练时经常使用大量的数据扩增,如随机翻转、随机裁剪、颜色抖动等。值得注意的是,对图像所做的任何操作都必须对边界框同样执行!比如,如果翻转图像,还必须对应地翻转真值框的坐标。
YOLO的数据扩增流程如下:
•加载原始图像;
•通过随机增加/减去原始大小的20%来选择新的宽度和高度;
•按照新大小裁剪图像,如果新图像在一个或多个边上大于原始图像,则用零填充
•将图像resize到416×416,使其成为正方形
•随机水平翻转图像(50%的概率)
•随机改变图像的色调、饱和度和曝光(亮度)
•对应地,要通过移动和缩放边界框坐标来调整边界框,以适应前面所做的裁剪和调整大小,以及水平翻转等操作
旋转也是一种常见的数据扩增技术,但这会比较麻烦,因为我们还需要同时旋转边界框,所以通常不会这样做。
而SSD采用的数据扩增方式包括:
随机裁剪一个图像区域,使该区域中物体的最小IOU(与原始图像中物体)为0.1、0.3、0.5、0.7或0.9,IOU越小,模型就越难检测到物体
•使用“缩小”增强,将图像变小,从而构建包含小物体的训练数据,这对于模型更好地处理小物体很有用。
随机裁剪可能会导致物体的部分(或全部)落在裁剪图像之外。因此,我们只希望保留中心位于该裁剪区域某个位置的边界框,而不希望保留中心位于裁剪区域之外的框。
注意高宽比
我们的预测是在13x13的正方形网格上,输入图像也是正方形的(416x416)。但是训练数据集中图像通常不是正方形的,而且测试图像一般也不是。而且,所有的图像大小可能并不相同。下图是VOC数据集中所有图像的高宽比的可视化:
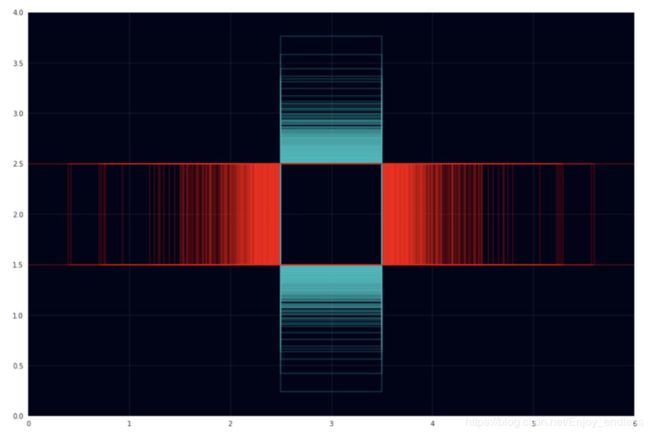
红色框是宽大于高,而青色框恰恰相反。 虽然存在一些奇怪的高宽比,但是大部分是1.333 (4:3), 1.5 (3:2), 0.75 (3:4)。有些图片甚至很宽,这里是一个极端例子:

由于网络的输入是416×416大小的正方形图像,因此我们必须将训练图像放在该正方形中。下面是几种方法:
• 直接将图像resize到416×416,这可能会挤压图像;
•将最小边调整为416,然后从图像中裁剪出416×416区域;
•将最大边调整为416,用零填充另外的短边;
上述方法都是有效的,但每个方法都有其副作用。我们直接将其高宽比更改为1:1,可能会挤压图像。如果原始图像宽大于高,则所有物体都比平常窄。如果原来的物体高大于宽,那么所有的物体都会变平。通过裁剪,虽然高宽比保持不变,但我们可能切掉图像的重要部分,使模型更难看到真实的物体,这样模型可能需要预测部分位于图像外部的边界框。而对于方法3,它可能会使物体太小而无法检测,尤其是在高宽比极端的情况下。
为什么这很重要?训练前,我们将边界框的xmin和xmax除以图像宽度,ymin和ymax除以图像高度,以归一化坐标,使它们介于0和1之间。这样做是为了使训练独立于每个图像的实际像素大小。但是输入的图像通常不是正方形的,所以x坐标除以一个与y坐标不同的数字。根据图像的尺寸和高宽比,每个图像的除数可能不同,这会影响我们如何处理边界框坐标和先验框。
方法1是最简单粗暴,尽管它会暂时破坏图像的高宽比。如果所有的图像都有相似的高宽比(在VOC中没有),或者高宽比不太极端,那么神经网络仍然可以正常工作。CNN网络似乎对于物体的“厚度”变化相当健壮(意思是物体挤压时CNN依然有效)。
对于方法2和3,在归一化边界框坐标时,我们应该记住高宽比。现在有可能边界框比输入图像大,因为我们只是对裁剪部分进行预测。而由于物体可能部分落在图像之外,边界框也可能部分落在图像之外。裁剪的缺点是我们可能会丢失图像的重要部分,这可能比稍微挤压物体更糟糕。挤压还是裁剪也会影响如何从数据集中计算先验框。使用先验框的重要因素,这些先验框的形状类似于数据集中最常见的物体形状。这在裁剪时仍然是正确的。一些先验框现在可能部分落在图像之外,但至少它们的高宽比真正代表了训练数据中的物体。对于挤压,计算出的先验框并不能真正代表真正的框,不同的高宽比会被忽略,因为每个训练图像的挤压方式略有不同。现在,先验框更像是在不同的扭曲图像求平均结果。
数据扩增也会有副作用。通过随机截取图像,然后将大小调整为416×416,这也会扰乱高宽比(更像故意的)。
总结来看,**直接对原始图像进行resize,而忽略边界框的高宽比,这是最简单有效的。这也是Yolo和SSD所采用的方式,这种方式可以看成让模型学会自适应高宽比。**如果我们在处理固定大小的输入图像,例如1280×720,那么使用裁剪可能更合适。
模型是如何训练的
前面都是预备项,接下来我们将来介绍这类目标检测模型是如何训练的。该模型使用卷积神经网络直接进行预测,然后把这些预测数字转换成边界框。数据集包含真实框,表示训练图像中实际存在哪些物体,因此要训练这种模型,我们需要设计一个损失函数,将预测框与真实框进行比较。
问题是,不同图像之间的真实框数量可能会有所不同,从零到几十个不等。这些框可能图像的不同位置,而且有些会重叠。在训练期间,我们必须将每个检测器与这些真实框中的一个相匹配,以便我们可以计算每个预测框的回归损失。
如果我们直接简单地进行匹配,例如总是将第一个真实框分配给第一个检测器,将第二个物体分配给第二个检测器,以此类推,或者通过将物体随机分配给检测器,那么每个检测器都将被训练来预测各种各样的物体:一些较大的物体,一些是极小的物体,有的会在图像的一角,有的会在相反的一角,有的会在中间,等等。这就出现前面所提到的问题:为什么仅仅在模型中添加一组回归输出就难有效。解决方案是使用带有固定大小网格的检测器,其中每个检测器只负责检测位于图像该部分的物体,并且只负责特定大小的物体。
现在,**损失函数需要知道哪个物体归属于哪个检测器,或者说在哪个网格单元中,**相反地,哪些检测器没有与它们相关联的真实框。这就是我们所说的“匹配”。
将真实框与检测器匹配
匹配的方法是各种各样的,在YOLO中,图像中的每个物体仅由一个检测器负责来预测。由于我们要找到边界框中心落在哪个网格单元中,那个单元与整个物体关联,而其它的网格单元如果预测了这个物体将被损失函数所惩罚。
VOC数据集给出的边界框标注为xmin, ymin, xmax, ymax。由于我们需要知道边界框中心,所以需要将边界框坐标转为center x, center y, width, and height。我们一般会先将边界框坐标归一化到[0, 1],这样它们独立于输入图像的大小(因为训练图像的大小并不一致)。
由于需要匹配,我们在采用一些数据扩增如随机翻转,要同时应用在图像和边界框上。
注意:对于一些数据扩增如随机裁剪和翻转,我们在每个epoch需要重新对真实框与检测器进行匹配。这个过程无法提前完成,并缓存下来,因为数据扩增是随机的,一般会改变匹配结果。
仅仅为每个物体选择网格单元是不够的。每个网格单元都有多个检测器,我们只需要其中一个检测器来查找物体,我们需要选择其先验框与物体的真实框最匹配的检测器。这通常采用IOU来衡量匹配度。这样,最小的物体被分配给检测器1(有最小的先验框),非常大的物体使用检测器5(有最大的先验框),以此类推。所以,只有那个单元中的特定检测器才可以预测这个物体。此规则使得不同的检测器更专注于处理形状和大小与先验框相似的物体(记住,物体的大小不必与先验框的大小完全相同,因为模型预测会预测相对于先验框的位置和大小偏移,先验框只是一个参考)。
因此,对于一个给定的训练图像,一些检测器将有一个与之相关的物体,而其他检测器将不会。如果训练图像中有3个物体,即有3个真实框,那么845个检测器中只有3个应该进行预测,而其他842个检测器则应该预测“无物体”(就我们的模型输出而言,得到的是置信度很低的边界框,理想情况下为0)。
从现在开始,我们用正例指代一个匹配到物体的检测器,而对于一个没有关联物体的检测器来说,则是负例,也可以说是“无对象”或背景。
由于模型的输出是13×13×125张量,因此损失函数所使用的目标张量也将是13×13×125。这个数字125来自:5个检测器,每个检测器预测类别的20个概率值+4个边界框坐标+1个置信度得分。在目标张量中,对于正例,我们会给出物体的边界框坐标和onehot编码的类别向量,而置信度为1.0(因为我们100%确定这是一个真实的物体)。对于负例,目标张量的所有值为0,边界框坐标和类向量在这里并不重要,因为它们将被损失函数所忽略,并且置信度得分为0,因为我们100%确定这里没有物体。
因此,训练的每个迭代过程,需要的是一个batch×416×416×3的图像张量和一个batch×13×13×125的目标张量,这个目标张量中元素的大多都是0,因为大多数检测器不负责预测一个物体。
匹配时还需要考虑一些其他细节。例如,当有多个物体的中心恰好落在同一个单元中时,该怎么处理?虽然实际上这可能不是一个大问题,特别是如果网格足够大时,但是我们仍然需要一种方法来处理这种情况。理论上,物体基于最佳IOU来匹配检测器,例如,物体A的边界框与检测器2的IOU最大,物体B的边界框与检测器4的IOU最大,那么我们可以将这物体与该单元中的不同检测器匹配。然而,这并不能避免有两个物体需要相同检测器这个问题。
YOLO的解决方案比较粗暴:每次随机打乱真实框,每个单元只选择第一个进入它中心的物体。因此,如果一个新的真实框与一个已经负责另一个物体的单元相匹配,那么我们就只能忽略它了。这意味着在YOLO中,每个单元至多有一个检测器被匹配到物体,而其他检测器不应该检测到任何东西(如果检测到了,就会受到惩罚)。
这只是YOLO的策略,SSD的匹配策略却不相同。SSD可以将同一个真实框与多个检测器匹配:首先选择具有最佳IOU值的检测器,然后选择那些与之IOU超过0.5的但是未被匹配过的检测器(注意检测器和先验框是绑定的,一一对应,所以说IOU指的是检测器的先验框与物体的边界框之间的重叠)。这应该使模型更容易学习,因为它不必在哪个检测器应该预测这个对象之间进行唯一选择,毕竟多个检测器可以预测这个对象。
注意:两者设计似乎是矛盾的。YOLO将一个物体只分配给一个检测器(而该单元的其他检测器则是无物体),以帮助检测器更专注。但是SSD说多个检测器可以预测同一个物体。两者实际上都可以。对于SSD,检测器专注于形状而不是大小。
损失函数
损失函数实际上是告诉模型它应该学习什么。对于目标检测,我们需要损失函数它能够使模型预测出正确的边界框,并对这些框正确分类,另一方面,模型不应该预测不存在的物体。这实际上是多任务学习。因此,损失函数由几个不同的部分组成,其中一部分是回归以预测边界框位置,另一部分用于分类。
对于任何一个检测器,有两种可能的情况:
•这个检测器没有与之相关的真实框,这是负例,它不应该检测到任何物体(即它应该预测一个置信度为0的边界框)。
•这个检测器匹配到了一个真实框,即正例,它负责检测到物体。
对于不应该检测到物体的检测器,当它们预测出置信度大于0的边界框时要惩罚它们。因为它们给出的检测是假阳性,图像中的这个位置上并没有真实物体。过多的误检会降低模型的效果。相反,如果检测器是正例,当出现下面的情况时,我们希望惩罚它:
•当坐标错误
•当置信度太低时
•分类错误
理想情况下,检测器应该预测一个与真实框完全重叠的框,类别也应该一致,并且具有较高的置信度。当置信度得分过低时,预测结果将被视为假阴性(false negative),这也意味着模型没有找到真正的物体。但是,如果置信度得分高,但坐标不准确或分类错误,则预测将被视为假阳性(false positive)。尽管模型检测出一个物体,但它是错误的。
这意味着相同的预测可以被判定为假阴性(会减低模型的召回),也可能是假阳性(降低模型的准确度)。只有当所有三个方面——坐标、置信度、类别都正确时,预测才算真阳性(true positive)。因为任何一个方面都可能出错,损失函数由几个部分组成,分别来衡量模型给出的预测的不同类型“错误性”,将这些部分相加,得到整体损失函数。
SSD、YOLO、Squezedet、Detectnet和其他one-stage目标检测模型的损失函数可能有差异,但是它们往往由相同的部分组成。
(1)没有被匹配的检测器(负例)
对于负例,损失函数仅包含置信度部分,因为没有真实框,所以没有任何坐标或类别标签来计算损失。如果这样的检测器确实找到了一个物体,它应该受到惩罚。置信度分数表示检测器是否认为有一个物体的中心在这个网格单元中。对于这样的检测器,目标张量中的真实置信度得分被设置为0,因为这里没有物体。预测得分也应该是0,或接近它。损失函数要降低预测值与目标值之间的误差。在YOLO中,这样计算:
no_object_loss[i, j, b] = no_object_scale * (0 - sigmoid(pred_conf[i, j, b]))**2
这里pred_conf[i, j, b]是网格单元 i, j上的检测器b预测的置信度. 这里使用sigmoid来将置信度的取值限制在[0,1]。可以看到,上面的loss仅仅是计算预测值与目标值之差的平方。而no_object_scale是一个超参数,一般取0.5, 这样这部分loss占整体比重不大. 由于图像中只有少量物体,所以845个检测器中的大部分仅计算这类“no object”损失。由于我们不想让模型仅仅学习到“no objects”,这部分loss不应该比那些匹配到物体的检测器的loss重要。
上述公式仅是计算一个网格单元中一个检测器的loss,实际上要将所有网格中的负例检测器的loss求和才是最终的loss。对于那些正例检测器,这项loss总是0。SqueezeDet求的是各个检测器loss的平均值(总loss除以负例检测器数量),而在YOLO中直接取loss和。
实际上,YOLO还有一个特别处理之处。如果一个检测器的预测框与所有真实框的IOU最大值大于一个阈值(比如0.6),那么忽略这个检测器的no_object_loss。换句话说,如果一个检测器被认为不应该预测一个物体,但是实际上却预测了一个不错的结果,那么最好是忽略它(或者鼓励它预测物体,也许我们应该让这个检测器与这个物体匹配)。这个trick到底会起多大作用,并无法评估(深度学习很多这样无法讲明白的trick)。
SSD没有这项loss,因为它将背景类看成一个特殊类进行处理。如果预测的是背景类,那个检测器被认为没有检测到物体。
注意:YOLO采用平方和误差(sum-squared error,SSE),而不是常见的用于回归的均方差(mean-squared error,MSE),或是用于分类的交叉熵。一个可能原因是每张图片物体数量并不同,如果取平均,那么包含10个物体的图片与包含1个物体的图片的loss的重要性一样,而采用求和,前者的重要性约是后者的10倍,这可能更公平。
(2)被匹配的检测器(正例)
前面所说的是不负责检测物体的负例检测器,接下来讲另一类检测器:它们应该检测到物体。当这类检测器没有检测到物体,或者给物体错误分类时,它们就被判定出错,有三部分loss来评估错误。
(a)置信度
首先是置信度loss:
object_loss[i, j, b] = object_scale * (1 - sigmoid(pred_conf[i, j, b]))**2
这与前面的no_object_loss很类似,只是这里的目标值是1,因为我们100%确定存在一个物体。 实际上,YOLO的处理方式更微妙:
object_loss[i, j, b] = object_scale *
(IOU(truth_coords, pred_coords) - sigmoid(pred_conf[i, j, b]))**2
预测的置信度pred_conf[i, j, b]应该能够表示预测框和真实框的IOU值,理想状态下这是1。YOLO在计算loss时不采用理想值,而是使用两个框的实际IOU值。这也讲得通:当IOU值低时,置信度会低,反之IOU值高,置信度也会高。对于no-object loss,我们一直希望预测的置信度为0,而这里我们并不是想要模型的置信度一直是100%。相反,模型应该能够学习评估预测的边界框的实际好坏,而IOU恰好可以反映这一点。
前面已经提到, SSD不预测置信度,所以这项loss也不计算。
(b)类别概率
每个检测器都会预测物体的类别,这与边界框坐标是分开的。本质上,我们为不同大小的物体训练了5个独立的分类器(同一个网格中的每个检测器的分类器是不同的)。
YOLOv1和v2按如下方式计算分类的loss:
class_loss[i, j, b] = class_scale * (true_class - softmax(pred_class))**2
这里true_class是onehot编码的目标向量(对于VOC数据集,大小为20) ,而pred_class是预测的logits向量。注意这里我们虽然使用了softmax,但是并没有计算交叉熵,反而是误差平方和loss,或者这是为了与其它loss保持一致。实际上,甚至可以不应用softmax也是可以的。
而YOLOv3和SSD采用不同的方式,它们将这个问题看成多标签分类问题。所以不采用softmax(它导致各个类别互斥),反而使用sigmoid,这样允许预测多个标签。进一步,它们采用标准的二元交叉熵计算loss。
由于SSD不预测置信度,所以它增加了一个背景类。如果检测器预测是背景,那么此检测器没有检测到物体,即忽略这个预测。实际上SSD的no-object loss就是背景类的分类loss。
(c)边界框坐标
最后一项loss是边界框坐标,也称为定位损失,其实就是简单地计算边界框的4个坐标的回归损失:
coord_loss[i, j, b] = coord_scale * ((true_x[i, j, b] - pred_x[i, j, b])**2
+ (true_y[i, j, b] - pred_y[i, j, b])**2
+ (true_w[i, j, b] - pred_w[i, j, b])**2
+ (true_h[i, j, b] - pred_h[i, j, b])**2)
其中缩放因子coord_scale是设置定位损失的权重,这个超参一般设置为5,这样该项损失相比其它更重要。这项损失是极其简单的,但是有必要知道公式中true_*和pred_*到底指什么。 在之前的部分,我们已经给出了如何得到真实的边界框坐标:
1.box_x[i, j, b] = (i + sigmoid(pred_x[i, j, b])) * 32
2.box_y[i, j, b] = (j + sigmoid(pred_y[i, j, b])) * 32
3.box_w[i, j, b] = anchor_w[b] * exp(pred_w[i, j, b]) * 32
4.box_h[i, j, b] = anchor_h[b] * exp(pred_h[i, j, b]) * 32
我们需要进行对模型的预测做一定的后处理才能得到有效的坐标值。由于模型实际上不是直接预测有效的边界框坐标,所以损失函数中的真实框也要与之对应,即我们要先将真实框的实际坐标进行逆向转换:
1.true_x[i, j, b] = ground_truth.center_x - grid[i, j].center_x
2.true_y[i, j, b] = ground_truth.center_y - grid[i, j].center_y
3.true_w[i, j, b] = log(ground_truth.width / anchor_w[b])
4.true_h[i, j, b] = log(ground_truth.height / anchor_h[b])
注意true_x和true_y是相对于网格单元格的,而true_w和true_h是相对于先验框的缩放因子。因此,在填充目标张量时,一定要先进行上述的逆向转换,否则损失函数将计算的是两个不同量的误差。
在SSD中,计算定位损失有稍微的不同,它采用的是“Smooth L1”损失:
1.difference = abs(true_x[i, j, b] - pred_x[i, j, b])
2.if difference < 1:
3. coord_loss_x[i, j, b] = 0.5 * difference**2
4.else:
5. coord_loss_x[i, j, b] = difference - 0.5
对于其它项坐标也是如此,这项loss对边界值更不敏感(曲线更平稳)。
开始训练
接下来,我们可以给出一个完整的模型训练过程,首先我们需要:
•一个包含图片以及边界框标注的数据集(如Pascal VOC);
•一个可以拥有网格检测器的模型,并采用一个匹配策略将真实框转化为目标张量;
•一个计算预测值与目标值的损失函数。
然后就可以采用SGD对模型进行训练,由于检测器对正例和负例的loss计算方式不同,需要一定的循环才可以计算出整个loss,简单的伪代码如下:
1.for i in 0 to 12:
2. for j in 0 to 12:
3. for b in 0 to 4:
4. gt = target[i, j, b] # ground-truth
5. pred = grid[i, j, b] # prediction from model
6. # is this detector responsible for an object?
7. if gt.conf == 1:
8. iou = IOU(gt.coords, pred.coords)
9. object_loss[i, j, b] = (iou - sigmoid(pred.conf[i, j, b]))**2
10. coord_loss[i, j, b] = sum((gt.coords - pred.coords)**2)
11. class_loss[i, j, b] = cross_entropy(gt.class, pred.class)
12. else:
13. no_object_loss[i, j, b] = (0 - sigmoid(pred.conf[i, j, b]))**2
最终的loss是各项loss的加权和:
1.loss = no_object_scale * sum(no_object_loss) +
2. object_scale * sum(object_loss) +
3. coord_scale * sum(coord_loss) +
4. class_scale * sum(class_loss)
但是实际上可以将上述循环过程向量化以可以在GPU上加速运算,主要思路是采用一个mask屏蔽那些不需要计算的部分:
1.# the mask is 1 for detectors that have an object, 0 otherwise
2.mask = (target.conf == 1)
3.# compute IOUs between each detector's predicted box and
4.# the corresponding ground-truth box from the target tensor
5.ious = IOU(target.coords, grid.coords)
6.# compute the loss terms for the entire grid at once:
7.object_loss = sum(mask * (ious - sigmoid(grid.conf))**2)
8.coord_loss = sum(mask * (target.coords - grid.coords)**2)
9.class_loss = sum(mask * (target.class - softmax(grid.class))**2)
10.no_object_loss = sum((1 - mask) * (0 - sigmoid(grid.conf))**2)
即使看起来目标检测的损失函数比图像分类更复杂,但是一旦你理解了每个部分的含义就比较简单了。由于YOLO,SSD以及其它的one-stage目标检测模型在计算loss时有稍微的不同,因而你有很多可选择的余地进行设计。
另外有一些值得注意的小技巧来训练模型:
•多尺度训练。一般情况下,目标检测模型用于不同大小的图片,因而也包含不同尺度的物体。一个可以让模型可以对不同大小的输入泛化的方法是每一定的迭代过程中随机选择不同的输入尺寸。比如随机从320×320到608×608之间选择的输入,而不是恒定在416x416。
•热身训练(Warm-up training)。 YOLO在早期训练阶段为每个单元中心增加一个假的真实框(先验框),采用这个额外的坐标损失来鼓励模型的预测可以匹配到检测器的先验框。
•难例挖掘(Hard negative mining)。前面已经说过大部分检测器是不负责检测任何物体的。这意味着正例数量要远少于负例。YOLO采用一个超参数no_object_scale 来处理这种情况,但是SSD采用难例挖掘:它不是计算所有负例的损失,而是只计算那些预测结果最错的部分损失(即置信度较高的负例)。
即使一旦训练后模型就能很好地工作,但是你有时候需要这些技巧让模型快速学习。
如何评价模型
为了评估一个分类模型,你可以简单的计算在测试集上预测正确的数量,并除以测试图片的总数,从而得到分类准确度。然而对于目标检测模型,你需要评估以下几个部分:
•每个检测物体的分类准确度;
•预测框与真实框的重合度(IOU)
•模型是否找到图片中的所有物体(召回,recall)。
仅采用任何一个指标是不够的。比如,如果设定IOU的阈值为50%,当一个预测框与一个真实框的IOU值大于该阈值时,被判定为真阳(TP),反之被判定为假阳(FP)。但是这并不足以评估模型的好坏,因为我们无法知道模型是否漏检了一些物体,比如存在某些模型没有预测出的真实框(假阴,FN)。

为了将以上几种不同因素转化为一个单一指标,通常我们计算mAP(mean average precision)。mAP值越高,模型越好。计算mAP的方法随数据集略有差异。
计算mAP
对于Pascal VOC数据集,首先我们要单独计算各个类别的AP(average precision),然后取平均值得到最终的mAP,所以mAP是平均的平均。对于precision,它是真阳数除以检测的总数:
1.precision = TP / (TP + FP)
在这个场景中,假阳值是检测器预测了一个在图像中并不存在的物体。这一般发生在预测框与图像中的真实框差异很大(IOU值低于阈值),或者预测的类别是错误的。
注意:这里我们并关心到底是哪个检测器给出的预测。在评估模型时我们并不会像训练过程那样将特定的检测器分配给某个物体,而是仅仅将预测框与真实框进行比较,以确定到底检测出了多少物体。
另外一个与 precision一起计算的指标是recall(true positive rate or the sensitivity):
1.recall = TP / (TP + FN)
recall和precision的唯一区别是分母不同,前者是真阳数加假阴数,即所有真实物体的总数。对于假阴,就是检测器没有找到一个真实的物体,或者给出的置信度较低。
举例来说,precision衡量的在预测为猫的物体中,到底有多少是真的猫,这里FP就是那些预测为猫但实际上却不是猫的数量。而recall衡量的是模型找到了图像中所有真实猫的多少个,FN是指的遗漏检测的猫的数量。比如,模型预测出了3只猫,但是实际上其中一个是狗,另外一个不存在物体,那么precision就等于1/3=0.33(三个预测中仅有一个是对的)。如果图像中存在4只猫,那么recall就是1/4=0.25,因为仅检测出了一只猫。如果图像中存在一只狗,那么对于狗这类,precision和recall都是0,因为狗的TP为0。
这里是计算TP和FP的伪代码:
1.sort the predictions by confidence score (high to low)
2.for each prediction:
3. true_boxes = get the annotations with same class as the prediction
4. and that are not marked as "difficult"
5. find IOUs between true_boxes and prediction
6. choose ground-truth box with biggest IOU overlap
7. if biggest IOU > threshold (which is 0.5 for Pascal VOC):
8. if we do not already have a detection for this ground-truth box:
9. TP += 1
10. else:
11. FP += 1
12. else:
13. FP += 1
如果某个预测框的分类正确,且与真实框的IOU值大于50%,那么就认为是TP,反之则是FP。如果存在两个及以上的预测与某个真实框的IOU大于50%,那么我们必须选择其中的一个认为是正确的预测,其它的将被当做FP。我们希望模型仅对每个物体预测一个框,这里我们通常会选择那个置信度最高的预测框。
由于对同个物体进行多次预测是受到惩罚的,所以最好先进行NMS以尽可能地去除重复的预测。最好也要扔掉那些置信度较低的预测(如低于0.3),否则它们会被当成FP。YOLO模型给出845个预测,而SSD给出1917个预测,这远远多于真实物体,因为大部分图像只含有1到3个物体。
目前为止,我们并没有计算FN,实际上并不需要。因为计算recall公式的分母是TP+FN,这实际上等于图像中真实物体的数量(我们所关注的特定类)。
现在我们计算出了precision和recall,但是单个precision和recall无法说明模型的效果。所以我们将计算一系列的precision和recall对,然后画出precision-recall曲线。对每个类,我们都会做出这样的曲线。而某个类的AP值就是曲线下的面积。
precision-recall曲线
如下是狗这个类的precision-recall曲线:
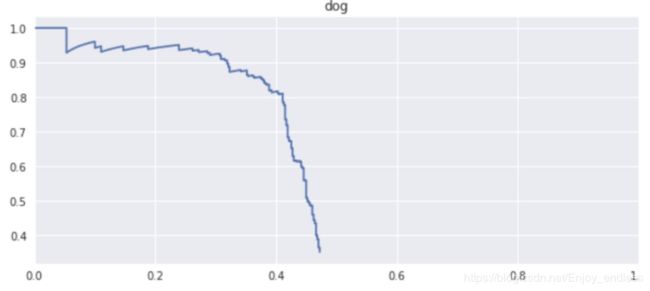
其中x坐标是recall,从0(没有检测到物体)到1(发现了所有物体),而y坐标是precision。这里precision看成是recall的函数,所以曲线的面积实际上就是这类物体的平均precision,因此叫做 “mean average precision”:我们想知道不同recall下的precision的平均值。
如何解释这条曲线?precision-recall曲线通常是通过设定不同的阈值来计算precision和recall对。对于一个二分类器来说,高于阈值就被判定为正例。在目标检测领域,我们会不断改变阈值(对应预测框的置信度)来得到不同的precision和recall。首先,我们计算第一个预测值(最大阈值)的precision和recall,然后计算第一个和第二个预测值(稍微降低阈值)的precision和recall,接着是前三个预测值的precision和recall(阈值更低),直到我们计算所有预测值下(阈值最低)的precision和recall。每对precision和recall对应就是曲线的一个点,x值为recall而y值是precision。在较大阈值处,recall是较低的,因为只包含很少预测结果,所以会有非常多的FN。你可以看到在曲线的最左侧,precision为100%,因为我们只包含了非常肯定的预测框。但是recall是极低的,因为漏掉了很多物体。随着阈值降低,将包含更多物体,recall增加。但precision上下波动,但由于FP会越来越多,它往往会变得更低。在最低阈值处,recall是最大的,因为现在包含了模型的所有预测。
可以看到,模型预测值的FP和FN之间始终存在折中。使用precision-recall曲线可以衡量这种折中,并找到一个较好的置信度阈值。选择高阈值意味着我们保留较少的预测,因此将减少FP(减少了错误),但我们也会有更多的FN(错过了更多的物体)。阈值越低,包含的预测越多,但它们通常质量较低。
理想情况下,各个recall下的precision都很高。计算出所有recall下的precision的平均值,可以给出模型在检测此特定类物体的总体效果。一旦我们获得了所有不同阈值下的precision和recall,就可以通过计算该曲线下的面积来得到AP。对于Pascal VOC数据集,实际上有两种不同的方法:2007版本使用近似方法; 2012版本更精确(使用积分)但分数一般更低。最终的mAP仅仅是20个类的AP平均值。当然,mAP越高越好。但这并不意味着mAP就是最重要的, YOLO的mAP一般低于其它模型,但速度却更快,特别是在移动设备上使用时,我们希望使用在速度和准确度之间具有较好折衷的模型。