机器学习-周志华 学习笔记4
3.4线性判别分析(Linear Discriminant Analysis,简称LDA)
LDA的思想:给定训练样例集,设法将样例投影到一条直线上,使得同类样例的投影点尽可能接近,异类样例的投影点尽可能远离;在对新样本进行分类时,将其投影到同样的这条直线上,再根据投影点的位置来确定新样本的类别。图3.3给出一个二维示意图:

欲使同类样例的投影点尽可能接近,可以让同类样例投影点的协方差尽可能小,而欲使异类样例的投影点尽可能远离,可以让类中新之间的距离尽可能大,同时考虑二者可得欲最大化的目标,即为二者比值最大。具体计算参见机器学习-周志华P61.
3.5多分类学习
一般基于一些基本策略,利用二分类学习器来解决多分类问题,考虑N个类别C1,C2,…,CN,多分类学习的基本思路是“拆解法”,即将多分类任务拆为若干个二分类任务求解。本节主要介绍拆分策略。
最经典的拆分策略有三种:“一对一”(One vs.One,简称OvO)、“一对其余”(One vs. Rest,简称OvR)和多对多(Many vs. Many,简称MvM)。
给定数据集D={(x1,y1),(x2,y2),…,(xm,ym)},yi∈{C1,C2,…,CN}。OvO将这N个类别两两配对,产生N(N-1)/2个分类任务,最终得到N(N-1)/2个分类结果,最终结果投票产生。图3.4给出一个示意图。
OvR则是每次将一个类的样例作为正例、所有其他类的样例作为反例来训练N个分类器。在测试时若仅有一个分类器预测为正类,则对应的类别标记作为最终分类结果,如图3.4所示。若有多个分类器预测为正类,则通常考虑各分类器的预测置信度,选择置信度最大的类别标记作为分类结果。
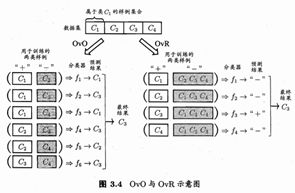
OvO的存储开销和测试时间开销通常比OvR更大。但在训练时,OvR的每个分类器均使用权不训练样例,而OvO的每个分类器仅用两个类的样例,因此在类别很多时,OvO的训练时间开销通常比OvR更小。至于预测性能,则取决于具体的数据分布,在多数情形下两者差不多。
MvM是每次将若干个类作为正类,其他类做为反类。MvM的正反类构造必须有特殊的设计,不能随意选取,这里介绍最常用的MvM技术:“纠错输入码”(Error Correcting Output Codes,简称ECOC)。
ECOC是将编码的思想引入类别拆分,并尽可能在解码过程中具有容错性。工作过程主要分为两步:
编码:对N个类别做M次划分,每次划分将一部分类别划分为正类,一部分划分为反类,从而形成一个二分类训练集;这样一共产生M个训练集,可以训练出M个分类器。
解码:M个分类器分别对测试样本进行预测,这些预测标记组成一个编码。蒋政预测编码与每个类别各自的编码进行比较,返回其中距离最小的类别作为最终结果预测。
类别划分通过“编码矩阵”(coding matrix)指定。编码矩阵常见的主要有二元码,三元码。前者将每个类别分别指定为正类和反类,后者在正、反类之外,还可指定“停用类”。图3.5给出了示意图。

在图3.5(a)中,若基于欧氏距离,预测结果将是C3。
之所以称为“纠错输出码”是因为在测试阶段,ECOC编码对分类器的错误有一定的容忍和修正能力。一般来说,同一个学习任务,ECOC编码越长,纠错能力越强。然而,编码越长,意味着所需训练的分类器越多,计算、存储开销都会增大;另一方面,对有限类别数,可能的组合数目是有限的,码长超过一定范围后就失去了意义。
3.6类别不平衡问题
类别不平衡(class-imbalance)就是指分类任务中不同类别的训练样例数目差别很大的情况。
从线性分类器的角度讨论便于理解。在我们用 对新样本x进行分类时,事实上是在用预测出的y值与一个阈值进行比较,几率y/(1-y),则是反映了正例可能性与反例可能性之比值,阈值设置为0.5表明分类器认为真实正、反例可能性相同,即分类器决策规则为:若y/(1-y) > 1则预测为正例。
然而当训练集中正反例数目不相同时,令m+表示正例数目,m-表示反例数目,此时
若![]() 则预测为正例,实际执行时由于按照
则预测为正例,实际执行时由于按照![]() 执行,所以需要令
执行,所以需要令![]()
,这就是类别不平衡学习的一个基本策略—“再缩放”(rescaling)。
再缩放的思想简单,但是实际操作并不简单,主要因为“训练集是真实样本总体的的无偏采样”这个假设往往并不成立,也就是说,我们未必能有效地基于训练集观测几率来推断真实几率。现在技术大体上有三种做法:“欠采样”(undersampling):即去除一些反例使得正反例数目接近再学习,第二类是“过采样”(oversampling),即增加一些正例使得正反例数目接近再学习;第三类是直接基于原始训练集进行学习,但在用训练好的分类器进行预测时,将 ![]() 嵌入决策过程中,称为“阈值移动”(threshold-moving)。
嵌入决策过程中,称为“阈值移动”(threshold-moving)。