.h5文件的读取
**
关于hdf5文件
**
HDF(Hierarchical Data Format)指一种为存储和处理大容量科学数据设计的文件格式及相应库文件。详见其官方介绍:https://support.hdfgroup.org/HDF5/ 。
Python 中有一系列的工具可以操作和使用 HDF5 数据,这里只介绍 h5py。
一个 HDF5 文件是存储两类对象的容器,这两类对象分别为:
dataset:类似数组的数据集合;
gropp;类似目录的容器,其中可以包含一个或多个 dataset 及其它的 group。
参考链接:https://www.jianshu.com/p/de9f33cdfba0
h5文件的读取
这里以我要用的模型的h5文件为例,是AudioSet数据集的一部分,论文的作者是将tfrecord格式写成了hdf5格式,因此想要读取这样格式的文件来看看里面的内容。
# python 2
#coding=utf-8
import datetime
import os
import h5py
import numpy as np
# f = h5py.File('path/filename.h5','r') #打开h5文件
f = h5py.File('E:/2018/AudioSet/bal_train.h5','r')
f.keys() #可以查看所有的主键
print([key for key in f.keys()])
运行程序后,结果有:

可以看到主键有3部分,分别为:
video_id_list, x, y
因此可以继续查看主键里面的内容,这部分直接用print语句就能实现,接在主键程序之后,这里简单举例说明一下:
print('first, we get values of x:', f['x'][:])
print('then, we get values of y:', f['y'][:])
print(f['x'][:].shape)
print(f['y'][:].shape)
运行这一部分的代码,结果有:
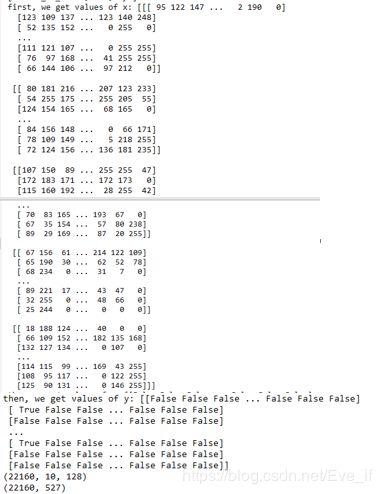
可以看到,通过print语句,得到了三个主键里面内容的大小,就我的h5文件,里面的video_id_list是一个存放了歌曲id的列表文件, x是输入的歌曲的特征文件22160是样本数目,(10,128)代表了样本是一个10×128的矩阵, y是一个标签文件,(22160,527)代表大小是22160×527,其中527是类别的数目。
可以利用io.save()函数来保存主键中的内容,。
from scipy import io
io.savemat('x.mat', {'data': f['x'][:]})
io.savemat('y.mat', {'data': f['y'][:]})
io.savemat('video_id_list.mat', {'data': f['video_id_list'][:]})
最后,给出完整的代码:
# python 2
#coding=utf-8
from scipy import io
import os
import h5py
import numpy as np
#打开h5文件
f = h5py.File('path/filename.h5','r')
#查看文件
f.keys() #可以查看所有的主键
print([key for key in f.keys()])
print('first, we get values of x:', f['x'][:])
print('then, we get values of y:', f['y'][:])
print(f['x'][:].shape)
print(f['y'][:].shape)
#保存数据
io.savemat('x.mat', {'data': f['x'][:]})
io.savemat('y.mat', {'data': f['y'][:]})
io.savemat('video_id_list.mat', {'data': f['video_id_list'][:]})