Python学习第十一天
疑惑:有很多人不知道是不是也分不清什么是单核?什么是多核?什么是时间片?进程?线程?
那么在讲进程和线程前我先举个例子更好理解这些概念。
单核例子:比如你是一个厨师(计算机)在一个厨房(CPU)里需要同时做3个菜(进程)、每个菜需要准备不同的调料以及协作(线程),那么这个厨师需要不断地切换时间(时间片)来达到同时在一个时间将三个菜做完。
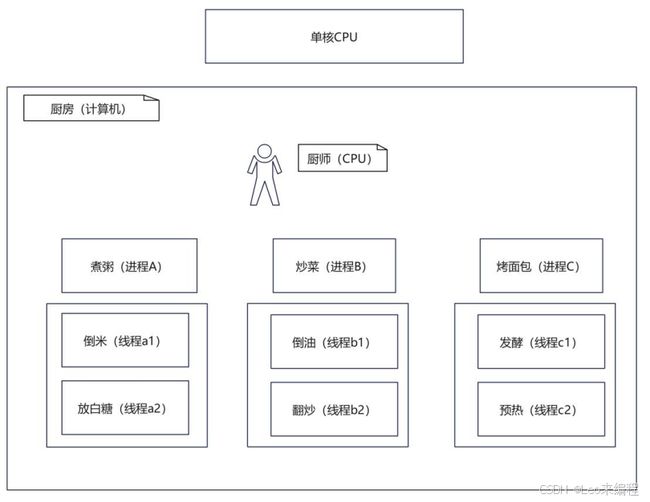
多核的话其实对应的例子就是多个厨师,这样的例子太多了因为万物皆对象、比如生活中的老师在批改作业、比如公司的牛马在牛马槽上班...等
单核对比多核CPU
| 特性 | 单核CPU(一个厨师) | 多核CPU(多个厨师) |
|---|---|---|
| 任务执行方式 | 多个任务交替执行(并发) | 多个任务可以同时执行(并行) |
| 时间片 | 每个任务分配固定的时间 | 每个任务仍然可以分配固定的时间 |
| 任务调度 | 一个厨师决定如何切换任务 | 多个厨师可以独立分配和切换任务 |
| 线程 | 子任务需要交替执行 | 子任务可以并行执行 |
| 效率 | 适合轻量级任务,效率较低 | 适合重量级任务,效率较高 |
并发与并行
并发:多个任务交替执行,看起来像是同时进行(同时进行的发生的,单核即可完成)。
高并发:多个任务交替执行,看起来像是同时进行(大数据量同时进行发生的)。
并行:多个任务真正同时执行,通常需要多核处理器。
进程
概念
官网概念:multiprocessing是一个支持使用与threading模块类似的API来产生进程的包。multiprocessing包同时提供了本地和远程并发操作,通过使用子进程而非线程有效地绕过了全局解释器锁。因此,multiprocessing模块允许程序员充分利用给定机器上的多个处理器。它在POSIX和Windows上均可运行。
特点:
-
独立内存:进程之间内存不共享,通信需要通过
multiprocessing模块提供的机制(如Queue、Pipe等)。 -
重量级:进程的创建和切换开销较大。
-
绕过GIL:由于每个进程有独立的Python解释器,因此可以充分利用多核CPU的性能。
适用场景:
-
CPU密集型任务(如计算、数据处理)。
-
需要隔离任务的场景。
使用
Python提供了multiprocessing模块来创建和管理进程。
1、Process类:用于创建单个进程。
-
每个
Process对象代表一个独立的进程。 -
需要手动启动(
start())和等待进程完成(join())。 -
适合需要精细控制进程的场景,比如需要进程间通信或复杂任务调度。
参数说明:
Process(group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None)
| 参数 | 类型 | 说明 |
|---|---|---|
group |
None |
保留参数,用于未来扩展。目前必须为None。 |
target |
可调用对象 | 进程启动时要执行的目标函数(如函数、方法)。 |
name |
字符串 | 进程的名称。如果不指定,Python会自动生成一个唯一的名称。 |
args |
元组 | 传递给目标函数target的位置参数。 |
kwargs |
字典 | 传递给目标函数target的关键字参数。 |
daemon |
布尔值 | 如果为True,则进程为守护进程(主进程退出时自动退出);默认为False。 |
2、Pool类:用于创建进程池,管理多个进程。
from multprocessing import Pool
with Pool(线程数) as p:
p.map(对应方法, 传递的参数)
-
自动管理一组进程(进程池),默认数量为CPU核心数。
-
提供高级接口(如
map()、apply())来分配任务。 -
适合批量处理大量独立任务,比如并行计算或数据处理。
参数说明:
Pool(processes=None, initializer=None, initargs=(), maxtasksperchild=None)
| 参数 | 类型 | 说明 |
|---|---|---|
processes |
整数 | 指定进程池中的进程数量。默认值为None,表示使用CPU的核心数。 |
initializer |
可调用对象 | 每个工作进程启动时调用的初始化函数。 |
initargs |
元组 | 传递给initializer函数的参数。 |
maxtasksperchild |
整数 | 每个工作进程在退出并替换为新进程之前可以完成的任务数。默认值为None,表示进程不会退出。 |
context |
multiprocessing.context |
指定进程池的上下文(如启动方法)。默认值为None,表示使用默认上下文。 |
from multiprocessing import Pool,Process
import os
# 使用 pool 来创建进程池 help(Pool) Pool(processes=None, initializer=None, initargs=(), maxtasksperchild=None)
def f(x):
return x*x
# 测试使用process help(Process) Process(group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None)
def f1(name):
print(name)
print('module name:', __name__)
print('parent process:', os.getppid())
print('process id:', os.getpid())
if __name__ == '__main__':
with Pool(5) as p:
print(p.map(f, [1, 2, 3]))
p = Process(target=f1, args=('bob',))
p.start()
p.join()3、Queue类:创建一个共享的进程队列,是多进程的安全队列,可以通过Queue实现多进程之间的数据传递。
-
当需要多生产者、多消费者的通信机制时。
-
当需要共享数据的场景时。
参数说明:
使用Process创建与Process的参数一致
from multiprocessing import Process,Queue
def put_queue(queue):
for i in [1,'2', {'name':'python'},'test']:
queue.put(i)
def take(queue):
while True:
value = queue.get()
print(f"从队列中获取到了{value}")
if __name__ == '__main__':
q = Queue()
# 这个args注意了 别少了q后面的逗号
p_put = Process(target=put_queue, args=(q,))
p_get = Process(target=take, args=(q,))
p_put.start()
p_get.start()
p_put.join()
# 强制关闭该进程对象 不使用的话 当前线程一直会启动 因为是while True
p_get.terminate()4、Pipe类:提供多进程之间的通信。
-
当需要两个进程之间的双向通信时。
-
当通信场景较简单时。
参数说明:
使用Process创建与Process的参数一致,并且与Queue方法不一致以外使用一致
from multiprocessing import Process,Pipe
def put_pipe(pipe):
for i in [1,'2', {'name':'python'},'test']:
# 注意了 这儿是管道
pipe[1].send(i)
def take(pipe):
while True:
# 注意了 这儿是管道
value = pipe[0].recv()
print(f"从队列中获取到了{value}")
if __name__ == '__main__':
p = Pipe()
# 这个args注意了 别少了q后面的逗号
p_put = Process(target=put_pipe, args=(p,))
p_get = Process(target=take, args=(p,))
p_put.start()
p_get.start()
p_put.join()
# 强制关闭该进程对象 不使用的话 当前线程一直会启动 因为是while True
p_get.terminate()对比
| 特性 | Process类 |
Pool类 |
Queue |
Pipe |
|---|---|---|---|---|
| 用途 | 创建和管理单个进程。 | 创建和管理进程池,适用于并行执行多个任务。 | 进程间通信,支持多生产者、多消费者。 | 进程间通信,支持两个进程之间的双向通信。 |
| 创建方式 | 显式创建Process对象,调用start()启动进程。 |
使用Pool对象,通过map()、apply()等方法提交任务。 |
创建Queue对象,通过put()和get()方法通信。 |
创建Pipe对象,返回两个连接对象(双向通信)。 |
| 进程数量 | 手动创建和管理多个Process对象。 |
自动管理固定数量的进程(默认是CPU核心数)。 | 无限制,但需要手动管理进程。 | 无限制,但需要手动管理进程。 |
| 任务分配 | 需要手动分配任务到每个进程。 | 自动分配任务到进程池中的空闲进程。 | 需要手动分配任务到队列。 | 需要手动分配任务到管道。 |
| 适用场景 | 需要精细控制每个进程的任务和生命周期。 | 适合批量处理大量任务,任务之间相互独立。 | 适合多生产者、多消费者的场景。 | 适合两个进程之间的双向通信。 |
| 代码复杂度 | 较高,需要手动管理进程的创建、启动和同步。 | 较低,Pool封装了进程管理和任务分配的逻辑。 |
中等,需要手动管理队列的读写。 | 中等,需要手动管理管道的读写。 |
| 任务类型 | 适合执行单个复杂任务或需要交互的任务。 | 适合执行大量独立的小任务。 | 适合需要共享数据的场景。 | 适合需要双向通信的场景。 |
| 返回值处理 | 需要通过Queue或Pipe手动获取返回值。 |
自动收集任务返回值(如map()返回结果列表)。 |
通过get()方法获取返回值。 |
通过recv()方法获取返回值。 |
| 进程间通信 | 需要手动实现(如Queue、Pipe等)。 |
由Pool内部处理,用户无需关心。 |
提供进程间通信机制。 | 提供进程间通信机制。 |
| 灵活性 | 高,可以完全控制进程的行为。 | 较低,受限于Pool的固定模式。 |
高,适合复杂的通信场景。 | 高,适合双向通信场景。 |
| 资源开销 | 较高,每个进程需要单独创建和管理。 | 较低,进程池复用固定数量的进程。 | 中等,队列需要额外的内存和同步机制。 | 较低,管道是轻量级的通信机制。 |
锁
进程锁:锁就是在中防止访问资源冲突。
# 加锁
import multiprocessing,time
list1 = ['A','B','','','']
index = 2
lock = multiprocessing.Lock()
def func(value):
# 定义全局标量index
global index
lock.acquire() # 加锁
list1[index] = value # t1: [a,b,c,'','']
time.sleep(0.2)
index += 1
print(list1,id(list1)) # 子进程
lock.release() # 解锁
if __name__ == '__main__':
t1 = multiprocessing.Process(target=func,args=("C",))
t2 = multiprocessing.Process(target=func,args=("D",))
t1.start()
t2.start()
t1.join()
t2.join()
print(list1,id(list1)) #主进程线程
概念
线程是操作系统调度的最小单位,属于同一个进程的多个线程共享进程的内存空间和资源。
使用
from threading import Thread
Thread(group=None, target=None, name=None, args=(), kwargs=None, *, daemon=None)
参数说明:
| 参数 | 类型 | 说明 |
|---|---|---|
group |
None |
保留参数,用于未来扩展。目前必须为None。 |
target |
可调用对象 | 线程启动时要执行的目标函数(如函数、方法)。 |
name |
字符串 | 线程的名称。如果不指定,Python会自动生成一个唯一的名称。 |
args |
元组 | 传递给目标函数target的位置参数。 |
kwargs |
字典 | 传递给目标函数target的关键字参数。 |
daemon |
布尔值 | 如果为True,则线程为守护线程(主线程退出时自动退出);默认为False。 |
from threading import Thread
# help(Thread) Thread(group=None, target=None, name=None, args=(), kwargs=None, *, daemon=None)
def worker(name, age):
print("{} is {} years old".format(name,age))
# 创建线程
t = Thread(
target=worker, # 目标函数
name="MyThread", # 线程名称
args=("Python", 18), # 位置参数
kwargs={}, # 关键字参数(这里为空)
daemon=False # 非守护线程
)
# 启动线程
t.start()
# 等待线程完成
t.join()方法
thread常用方法
| 方法名 | 说明 | 示例 |
|---|---|---|
start() |
启动线程,调用目标函数target。 |
t.start() |
join(timeout=None) |
等待线程完成。可以指定超时时间timeout(单位为秒)。 |
t.join() 或 t.join(timeout=2) |
is_alive() |
返回线程是否仍在运行。 | if t.is_alive(): print("Thread is running") |
name |
获取或设置线程的名称。 | t.name = "MyThread" 或 print(t.name) |
ident |
返回线程的标识符(如果线程未启动,则为None)。 |
print(t.ident) |
daemon |
获取或设置线程是否为守护线程。 | t.daemon = True 或 print(t.daemon) |
run() |
线程执行的目标方法。通常不需要直接调用,由start()自动调用。 |
可以重写run()方法以实现自定义线程行为。 |
getName() |
获取线程的名称(已弃用,建议直接使用name属性)。 |
print(t.getName()) |
setName(name) |
设置线程的名称(已弃用,建议直接使用name属性)。 |
t.setName("MyThread") |
isDaemon() |
返回线程是否为守护线程(已弃用,建议直接使用daemon属性)。 |
print(t.isDaemon()) |
setDaemon(daemonic) |
设置线程是否为守护线程(已弃用,建议直接使用daemon属性)。 |
t.setDaemon(True) |
import threading
def music(name,num):
for i in range(num):
print("听{}歌{}次".format(name,i+1))
def movie(name,num):
for i in range(num):
print("看{}电影{}次".format(name,i+1))
t1 = threading.Thread(target=music,args=("邓紫棋秘密",5),name="python",daemon=True)
t2 = threading.Thread(target=movie,args=("‘哪吒2之魔童降世’",5),name="java",daemon=True)
# 测试守护线程
t1.daemon = True
# setDaemon这个方法不推荐使用了 使用直接设置属性即可
t2.daemon = False
# t1线程启动
t1.start()
# t1线程是否存活
print(t1.is_alive())
# t2线程启动
t2.start()
# 主线程调用了t1的join方法,会阻塞主线程,等待该线程执行完毕
t1.join()
# 主线程调用了t2的join方法
t2.join()
print("是否我先输出")
t1.name = "python thread"
print("t1的名字:",t1.name)
# 使用name属性即可 不要使用getname 了
print(t2.name)
# 使用ident属性即可
print(t1.ident)状态
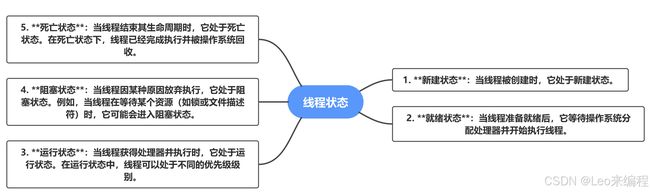
全局锁
在Python中,全局锁通常指的是全局解释器锁(Global Interpreter Lock, GIL)。GIL是Python解释器中的一个机制,用于确保同一时间只有一个线程执行Python字节码。尽管GIL的存在简化了CPython的实现并提高了单线程性能,但它也限制了多线程程序的并行性能,尤其是在CPU密集型任务中。
-
GIL是Python解释器(特别是CPython)中的一个互斥锁(Mutex)。
-
它确保同一时间只有一个线程执行Python字节码,即使是在多核CPU上。
-
GIL的存在主要是因为CPython的内存管理不是线程安全的。
GIL锁极大的影响了CPU的多核性质,使得多线程几乎相当于单线程(了解即可)
同步
线程锁:作用于线程上的锁保证原子性、数据一致性。
threading.Lock
线程锁/同步锁/互斥锁
上锁:acquire()
解锁:release()
import threading
import time
list1 = ['A','B','','','']
index = 2
lock = threading.Lock()
def func(value):
global index
lock.acquire() # 加锁
list1[index] = value # t1: [a,b,c,'','']
time.sleep(0.2)
index += 1
lock.release() # 解锁
t1 = threading.Thread(target=func,args=("C",))
t2 = threading.Thread(target=func,args=("D",))
t1.start()
t2.start()
t1.join()
t2.join()
print(list1)锁在使用过程中可能会造成死锁:
Lock对象在线程中对同一个原子操作,只有一次机会使用acquire对其加锁。如果多次加锁,线程会进入死锁模式,无法正常使用。
解决方式:换锁Rlock,允许对同一个原子操作重复acquire。
我先做记录 后续在更新下这部分内容,有的还在作图 会重新更新理解 这部分比较难理解。