COCO数据集上的实验
1.MMdetection上的实验
1.1 cascade_rcnn_x101
CUDA_VISIBLE_DEVICES=3 python ./tools/test.py ./configs/cascade_rcnn_x101_64x4d_fpn_1x.py ./checkpoints/cascade_rcnn_x101_64x4d_fpn_2x_20181218-5add321e.pth --out RESULT_cascade_101_fpn_2.pkl --json_out RESULT_cascade_101_fpn_2.json --eval bbox
1.2 cascade_rcnn_HRnet
CUDA_VISIBLE_DEVICES=3 python ./tools/test.py ./configs/hrnet/cascade_rcnn_hrnetv2p_w48_20e.py ./checkpoints/cascade_rcnn_hrnetv2p_w48_20e_20190810-f40ed8e1.pth --out RESULT_cascade_hrnet.pkl --json_out RESULT_cascade_hrnet.json --eval bbox
1.3 cascade_mask_rcnn_x101
CUDA_VISIBLE_DEVICES=4 python ./tools/test.py ./configs/cascade_mask_rcnn_x101_64x4d_fpn_1x.py ./checkpoints/cascade_mask_rcnn_x101_64x4d_fpn_20e_20181218-630773a7.pth --out RESULT_cascade_mask_x101.pkl --json_out RESULT_cascade_mask_x101.json --eval bbox
1.4 cascade_mask_rcnn_101
CUDA_VISIBLE_DEVICES=4 python ./tools/test.py ./configs/cascade_mask_rcnn_x101_64x4d_fpn_1x.py ./checkpoints/cascade_mask_rcnn_hrnetv2p_w48_20e_20190810-d04a1415.pth --out RESULT_cascade_mask_x101.pkl --json_out RESULT_cascade_mask_x101.json --eval bbox
测试集为5000个样本的小测试集
训练集和训练集上的结果
| 序号 | AP/AR | 说明 | 训练集 | 测试集 | hrnet |
|---|---|---|---|---|---|
| 1 | Average Precision (AP) | @[ IoU=0.50:0.95 area= all maxDets=100 ] | 0.607 | 0.447 | 0.446 |
| 2 | Average Precision (AP) | @[ IoU=0.50 area= all maxDets=100 ] | 0.799 | 0.631 | 0.627 |
| 3 | Average Precision (AP) | @[ IoU=0.75 area= all maxDets=100 ] | 0.682 | 0.490 | 0.487 |
| 4 | Average Precision (AP) | @[ IoU=0.50:0.95 area= small maxDets=100 ] | 0.424 | 0.258 | 0.263 |
| 5 | Average Precision (AP) | @[ IoU=0.50:0.95 area=medium maxDets=100 ] | 0.666 | 0.483 | 0.481 |
| 6 | Average Precision (AP) | @[ IoU=0.50:0.95 area= large maxDets=100 ] | 0.729 | 0.588 | 0.585 |
| 7 | Average Recall (AR) | @[ IoU=0.50:0.95 area= all maxDets= 1 ] | 0.427 | 0.352 | 0.352 |
| 8 | Average Recall (AR) | @[ IoU=0.50:0.95 area= all maxDets= 10 ] | 0.673 | 0.544 | 0.553 |
| 9 | Average Recall (AR) | @[ IoU=0.50:0.95 area= all maxDets=100 ] | 0.698 | 0.567 | 0.577 |
| 10 | Average Recall (AR) | @[ IoU=0.50:0.95 area= small maxDets=100 ] | 0.513 | 0.348 | 0.373 |
| 11 | Average Recall (AR) | @[ IoU=0.50:0.95 area=medium maxDets=100 ] | 0.756 | 0.605 | 0.553 |
| 12 | Average Recall (AR) | @[ IoU=0.50:0.95 area= large maxDets=100 ] | 0.838 | 0.726 | 0.553(?) |
- 总体上,训练集的AP能够高达0.607,而验证集上只能达到0.447,这说明还有很大的提升空间。
- 观察AP50, 对应VOC的指标,训练集上能够达到0.799,VOC目前见到的SOTA能达到约0.85,还有提升空间,而测试集上为0.631,还有大量提升空间。
- 从IOU = 0.50到IOU = 0.75,AP降低了较多,说明还存在不少定位不准的bbox,与gt的IOU没有那么高。
- 观察4, 5, 6,训练集上的表现都要明显优于测试集。过拟合?两个方法在大中小物体上的表现几乎一致,hrnet在小物体上要略高一点点。
- 观察7,8,9,recall的下降都差不多,两个方法的recal几乎没有区别。两个方法的AP也十分接近,是否说明了
- 观察10,11,12,小物体的recal也较低。
1.实验
写了一些程序来分析检测器的效果。
检测器:cascade_rcnn_x101
1. 在原图(val)上画出GT和Det。
1’. 根据类别不同在原图(val)上画出GT和Det
1实现:根据test.py输出的result.json就可以画出来Det。GT同理,用annotation就可以。
1’实现:按照类别分门别类就行了。


相当多的图片都标的挺准的,就像上面两张图片那样。但也发现了一些现象,可能是导致指标不好的原因

000000091500.jpg
就比如说上面图中的椅子,筛选后如下图:
1,我们可以观察到椅子露出的部分越多,score越大。score是由卷积核(模板)和feature map做点积得到,与模板越接近则confidence越大。可以猜测:整体的feature是由部分的feature进行类似于线性相加得到的,进而整体的score是由部分的feature线性相加得到的。
2,我们观察到右边人的椅子有一个confidence较高的框,框出了椅子的整体,CNN具有一定的脑补能力,能够推测出物体的全貌进而框出整个物体,而GT只标注了部分。
推测原因:
- 判断椅子主要用的是context信息,context信息是场景信息,在网络的加深过程中逐渐汇集到物体的中心附近,这样卷积核就能够根据汇集的信息来判断出该位置是椅子。场景信息 + 物体自身的部分信息 -> 整体bbox。
3,对于一个椅子,有多个框与之对应。
推测原因:
- . 一个物体会在不同尺度的特征图上留下特征,所以会在多尺度上给出bbox。统一尺度相近的bbox可以通过NMS的进行筛选,但是不同尺度的bbox就不能这么做了。因为IOU不够大,筛不掉。 小尺度的物体在小分辨率特征图上存在,大尺度物体在小分辨率特征图上存在,那么出现多个框也不足为奇了。IDEA,让尺度更加分明,比如说SNIP的训练方法,
- 由于GT中有部分椅子,也有出现整体椅子,因此网络需要同时学习到两种类型图像的判断,这就会出现混淆,一些卷积核预测了部分,而另一些预测了整体,导致多个框出现,还没法用NMS筛选。

4, 在COCO数据集中有一个标签是iscrowd,如果是TRUE的话,那么bbox标注的是一群物体。但是检测器并不能分辨这种情况。
5,如果观察苹果类别和胡萝卜类别的话,就可以发现这种情况,有些红色、橘黄色的小色块被标注为了苹果或者胡萝卜。观察胡萝卜还可以发现基本上这种误识别的色块都是由于在餐盘上。可推测:餐盘 + 橘黄色色块 -> 胡萝卜,网络学习到的特征还不够鲁棒。IDEA:这个咋想啊?
3. 绘制每类物体不同area的PR曲线
思路:
1.将cocoapi的cocoeval.py移到项目内,在accumulate函数中添加代码,将image id、tps、fps存储下来:
E_id = np.concatenate(
[np.ones(len(e['dtScores'][0:maxDet]))*e['image_id'] for e in E])
E_id = E_id[inds]
content = {}
content['imgid_ids'] = E_id.astype(np.float).tolist()
content['tps'] = tps.tolist()
content['fps'] = fps.tolist()
SAVE_TPS_IMGID[str((k, a, m))] = content
存储在SAVE_TPS_IMGID中,SAVE_TPS_IMGID有3个索引
k:类别,category
a:area,all、small、medium、big
m:max det,1,10,100
其中,fps为10个元素的列表,索引为t,代表iou阈值。
2. 使用draw_PR_SMB画出图来,默认maxdet=100。
图例:
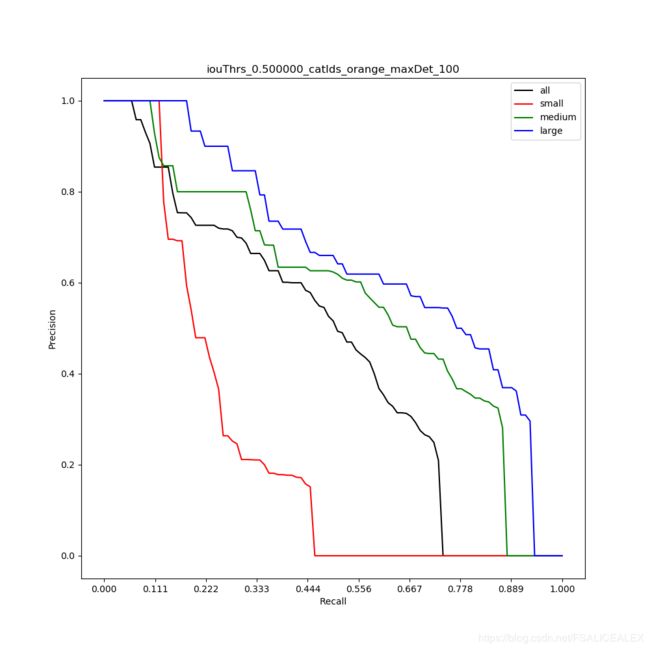
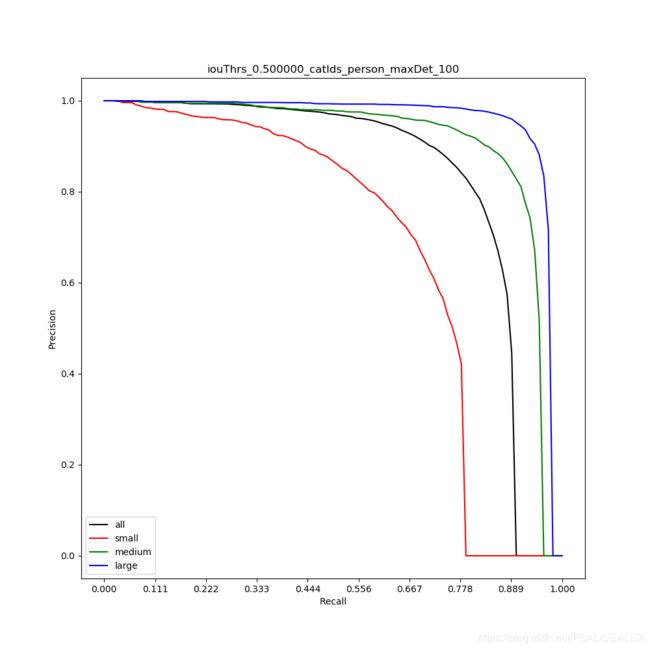
大体趋势就是这个样子,随着recall的增加,precision陡然下降。
假如fp和tp是均匀分布的话,那么precision是呈线性下降。orange的PR曲线就是这种趋势,说明存在着很多高score的bbox没有回归到位(更可能是数据集没有GT与之对应,比方说一堆橘子,但是有iscrowd)。
但一般而言还是像person(下面那张)一样,Precision以指数的趋势下降。这说明fp随着score的增加而指数级增长,离GT较远的Det的score会显著下降。这说明检测器能够将特征集中在特定位置上。
对比小中大的PR曲线可以得知,小物体的召回率不足,而且Precision衰减的更快,这是由于小物体特征聚集的位置更小,不像大物体那么分散。大物体的特征会被网络聚集到一个特定的地方,然后卷积核进行卷积得到回归和分类的结果,但是这个特定的地方并不一定是物体中心。(idea,观察是否是物体的中心点回归,还是头部啦,车轮子啦,椅子腿啦的Anchor回归。)
3. 调查precision和precision数量之间的关系
实现:
- 使用3中的SAVE_TPS_IMGID,使用TPS_Analysis.py。对每一类,计算每张图片的FP和TP,装进列表里。之后计算每张图片的precision(TP / (FP + TP))和proposal数量(TP + FP),观察proposal数量和precision的关系。Proposal = 10,对应有M个图片有10个proposal,将这M个图片的precision平均,得到该proposal数量的平均精度。
- 绘制平均净度曲线
- 将各个类别得到的曲线进行进一步平均,得到总体的precision-proposal曲线。
观察:
从每个类别上很难看出趋势,但是平均后就能看出来了: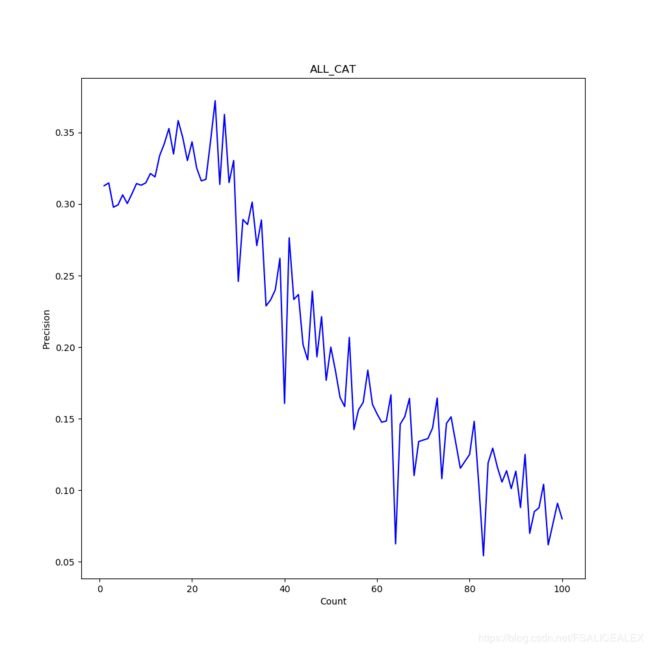
当一张图片中proposal数量越多的时候,precision会越低。proposal多的情况一般发生在图片出现多个物体的时候,比方说一盘胡萝卜,一堆苹果,一群人,这时候大多出现的是小物体,而且很可能GT没有标注那么多,也就是造成了precision的降低。
4. 去除部分图片观察ap的变化
- 利用3中的方法,将count > 10,ratio(某一类的precision)< (0.3, 0.2, 0.1)的图片挑出来,形成R01C20.json等包含image_id的文件。
- 将coco的annotation_val2017中对应的图片删除掉,使用COCO_EXP的reasoning_annotations。
- 将result file中对应图片的bbox去除。(之前还试过添加ignore标签来越过检查,后来发现直接去除图片就行了。)
- 观察ap的变化
以下为ap的变化:
R01:某类proposal的TP / (FP + TP) < 10 且 数量 > 10,共293张
R02:共524张
R03:共814张
| 序号 | AP/AR | 说明 | org | R01 | R02 | R03 |
|---|---|---|---|---|---|---|
| 1 | Average Precision (AP) | @[ IoU=0.50:0.95 area= all maxDets=100 ] | 0.447 | 0.460 | 0.469 | 0.481 |
| 2 | Average Precision (AP) | @[ IoU=0.50 area= all maxDets=100 ] | 0.631 | 0.647 | 0.656 | 0.666 |
| 3 | Average Precision (AP) | @[ IoU=0.75 area= all maxDets=100 ] | 0.490 | 0.502 | 0.512 | 0.528 |
| 4 | Average Precision (AP) | @[ IoU=0.50:0.95 area= small maxDets=100 ] | 0.258 | 0.273 | 0.281 | 0.295 |
| 5 | Average Precision (AP) | @[ IoU=0.50:0.95 area=medium maxDets=100 ] | 0.483 | 0.494 | 0.493 | 0.500 |
| 6 | Average Precision (AP) | @[ IoU=0.50:0.95 area= large maxDets=100 ] | 0.588 | 0.596 | 0.599 | 0.603 |
| 7 | Average Recall (AR) | @[ IoU=0.50:0.95 area= all maxDets= 1 ] | 0.352 | 0.361 | 0.373 | 0.390 |
| 8 | Average Recall (AR) | @[ IoU=0.50:0.95 area= all maxDets= 10 ] | 0.544 | 0.556 | 0.570 | 0.586 |
| 9 | Average Recall (AR) | @[ IoU=0.50:0.95 area= all maxDets=100 ] | 0.567 | 0.577 | 0.587 | 0.599 |
| 10 | Average Recall (AR) | @[ IoU=0.50:0.95 area= small maxDets=100 ] | 0.348 | 0.358 | 0.369 | 0.382 |
| 11 | Average Recall (AR) | @[ IoU=0.50:0.95 area=medium maxDets=100 ] | 0.605 | 0.611 | 0.606 | 0.609 |
| 12 | Average Recall (AR) | @[ IoU=0.50:0.95 area= large maxDets=100 ] | 0.726 | 0.732 | 0.734 | 0.735 |
idea:按照场景数目不同进行训练
4. 两个模型的比较
| 序号 | AP/AR | 说明 | Cascade | HTC |
|---|---|---|---|---|
| 1 | Average Precision (AP) | @[ IoU=0.50:0.95 area= all maxDets=100 ] | 0.447 | 0.506 |
| 2 | Average Precision (AP) | @[ IoU=0.50 area= all maxDets=100 ] | 0.631 | 0.701 |
| 3 | Average Precision (AP) | @[ IoU=0.75 area= all maxDets=100 ] | 0.490 | 0.551 |
| 4 | Average Precision (AP) | @[ IoU=0.50:0.95 area= small maxDets=100 ] | 0.258 | 0.328 |
| 5 | Average Precision (AP) | @[ IoU=0.50:0.95 area=medium maxDets=100 ] | 0.483 | 0.547 |
| 6 | Average Precision (AP) | @[ IoU=0.50:0.95 area= large maxDets=100 ] | 0.588 | 0.664 |
| 7 | Average Recall (AR) | @[ IoU=0.50:0.95 area= all maxDets= 1 ] | 0.352 | 0.384 |
| 8 | Average Recall (AR) | @[ IoU=0.50:0.95 area= all maxDets= 10 ] | 0.544 | 0.620 |
| 9 | Average Recall (AR) | @[ IoU=0.50:0.95 area= all maxDets=100 ] | 0.567 | 0.654 |
| 10 | Average Recall (AR) | @[ IoU=0.50:0.95 area= small maxDets=100 ] | 0.348 | 0.480 |
| 11 | Average Recall (AR) | @[ IoU=0.50:0.95 area=medium maxDets=100 ] | 0.605 | 0.699 |
| 12 | Average Recall (AR) | @[ IoU=0.50:0.95 area= large maxDets=100 ] | 0.726 | 0.810 |
4. 绘制出没有匹配到的gt
目的:查看小物体recall低的原因。
网络使用的是map=0.506的HTC检测网络。首先是小物体
红色的是GT。粉色(洋红)的是DT(area)
apple:

000000030213.jpg、74209、139099
有大量的proposa,但是没有匹配上。
还有一种情况,就是苹果堆:303566
总体上来看,网络能够具有较高的recall,但是对于密集小目标仍然难以处理,coco数据集中也存在着很多图片,标注的物体很难识别。
backpack
很多标注本来就很难。
banana
主要还是有很多物体(香蕉堆、香蕉块),也能识别和定位,但是有GT的物体没有匹配上。
bird:令人惊讶的效果好,但是依然有没有被检测出来的。

主要是因为鸟之间的间距足够开吧。
也出现过检测框只框住鸟头的情况。可能是因为鸟的特征最后集中在了鸟头。
5. RetinaNet
CUDA_VISIBLE_DEVICES=4 python ./tools/test.py ./configs/retinanet_x101_64x4d_fpn_1x.py ./checkpoints/RetinaNet/retinanet_x101_64x4d_fpn_2x_20181218-5e88d045.pth --out ./results/RESULT_retinanet_x101.pkl --json_out RESULT_retinanet_x101.json --eval bbox
| 序号 | AP/AR | 说明 | Cascade | RetinaNet |
|---|---|---|---|---|
| 1 | Average Precision (AP) | @[ IoU=0.50:0.95 area= all maxDets=100 ] | 0.447 | 0.396 |
| 2 | Average Precision (AP) | @[ IoU=0.50 area= all maxDets=100 ] | 0.631 | 0.603 |
| 3 | Average Precision (AP) | @[ IoU=0.75 area= all maxDets=100 ] | 0.490 | 0.423 |
| 4 | Average Precision (AP) | @[ IoU=0.50:0.95 area= small maxDets=100 ] | 0.258 | 0.216 |
| 5 | Average Precision (AP) | @[ IoU=0.50:0.95 area=medium maxDets=100 ] | 0.483 | 0.435 |
| 6 | Average Precision (AP) | @[ IoU=0.50:0.95 area= large maxDets=100 ] | 0.588 | 0.535 |
| 7 | Average Recall (AR) | @[ IoU=0.50:0.95 area= all maxDets= 1 ] | 0.352 | 0.329 |
| 8 | Average Recall (AR) | @[ IoU=0.50:0.95 area= all maxDets= 10 ] | 0.544 | 0.516 |
| 9 | Average Recall (AR) | @[ IoU=0.50:0.95 area= all maxDets=100 ] | 0.567 | 0.545 |
| 10 | Average Recall (AR) | @[ IoU=0.50:0.95 area= small maxDets=100 ] | 0.348 | 0.350 |
| 11 | Average Recall (AR) | @[ IoU=0.50:0.95 area=medium maxDets=100 ] | 0.605 | 0.587 |
| 12 | Average Recall (AR) | @[ IoU=0.50:0.95 area= large maxDets=100 ] | 0.726 | 0.706 |
6. 对比RetinaNet和HTC的AP、AR-IOUthr曲线
- 随着IOUthr升高。AP、AR的下降趋势与倒数函数接近。IOU=0.5相当于两个bbox的重叠面积至少达到了2/3。设 I O U t h r = p IOUthr=p IOUthr=p,两个bbox中较大一个 B b B_b Bb的面积为 k k k倍另一个( B s B_s Bs)的面积。则重合面积至少要占到 B s B_s Bs的 1 + k 1 + 1 p \frac{1+k}{1+\frac{1}{p}} 1+p11+k,是倒数函数。可以猜想,检测器的DT在不同重合率(重合面积/DT的面积)上的分布基本上是均匀的。IOU的要求比较严苛,当IOU=0.75时,需要最少0.86的重合面积。
- 对比大中小的AR和AP,显然,随着物体的尺寸减小,AR,PR均减小,与IOUthr无关。
- 对比两个网络的AP-IOUthr曲线, RetinaNet的曲线整体低于HTC的曲线。
- 对比两个网络的AR-IOUthr曲线, 和2中一致,RetinaNet整体低于HTC,与尺寸无关。小物体的Recall在IOUthr=0.5时分别为0.4和0.52,从recall上可以提升。
- 如果从比率上来看的话,那么小物体的Recall和Precision下降的最快。但是事实上从图中可以看出小物体的PR,Recall下降是呈线性的,至少没有出现预料的指数下降。
所以,最好的HTC和较差的RetinaNet在Precision,AR上的规律基本是一致的。只要能够在源头上提高AR和AP就可以了。小物体的AR、AP更低,这说明小物体的定位能力还是不准。
6. 对比RetinaNet和HTC的AP、AR-IOUthr曲线(IOUthr ∈ \in ∈[0.05, 0.95])
将IOUthr的范围改变,查看AR,PR曲线,结论与之前基本相似。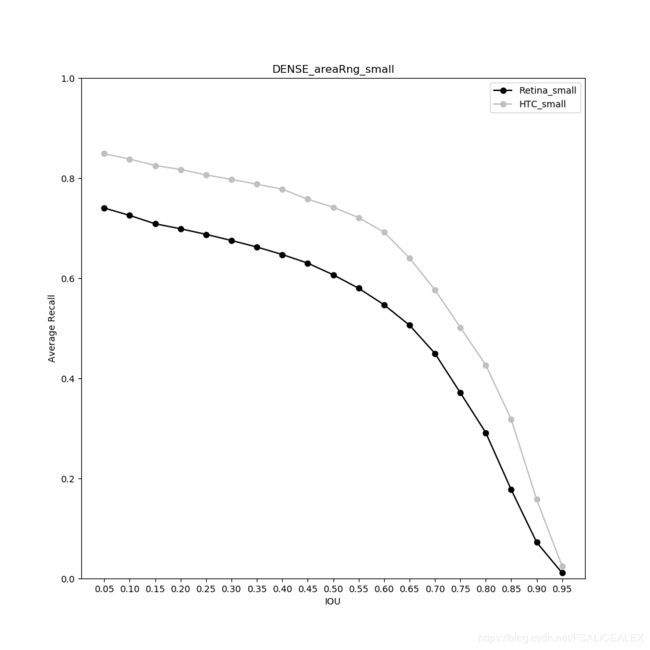
上面这个是小物体的AR曲线。召回率可以有一定的提升,Retina的可以从0.6提升到大约0.73,0.73对应IOUthr=0.05,只有1/10的重合面积,即使如此,平均上依然有1/4的物体没有被检测器识别到。这说明很可能不是检测器检测到了物体而没有给出好的bbox,而是检测器根本没有检测到物体。从另一方面,对比IOUthr=0.35时候的RetinaNet(最少重叠0.5)和HTC在IOUthr=0.65(最少重叠0.79)的Recall,可以发现差不多,所以的确存在着定位不准的问题,而且在小物体上更为明显,如果我们能够让定位更准,至少能够让RetinaNet达到HTC的水准。
大中物体的AR没有很大的差别,如下两张图:
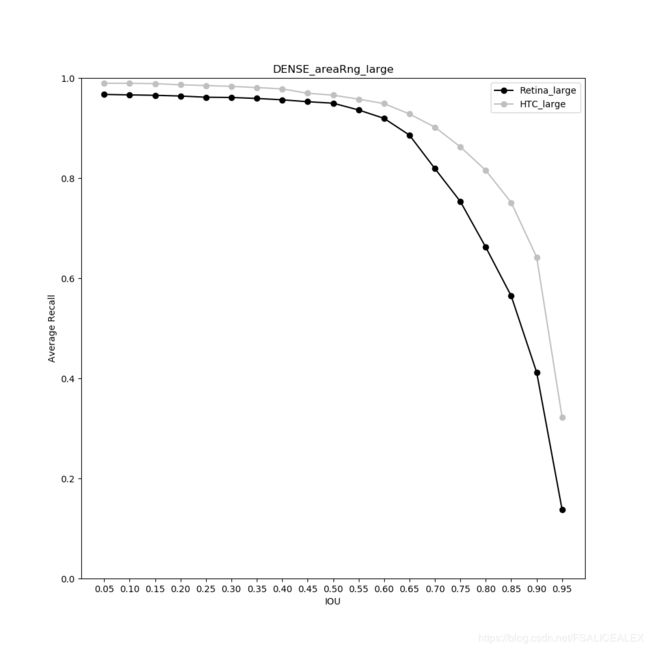

如果观察IOUthr=0.5基本上差不多,但可以看出来,当IOUthr增加的时候,RetinaNet的AR下降的更快,这说明RetinaNet在定位的准确度上有所欠缺,而大 中 物体是能够检测到的。
筛选出RetinaNet、HTC的含有unmatched物体的图片。并进行统计,有下表:
UNM代表没有匹配,M代表匹配,数字表示包含未匹配物体的图片的数量。一张图片中可能出现多个未匹配物体,图片会出现重复计数。
| 序号 | 说明 | Small | Medium | Big | Total |
|---|---|---|---|---|---|
| 1 | Retina UNM | 2428 | 889 | 187 | 3504 |
| 2 | Dense Retina UNM | 1409 | 333 | 63 | 1805 |
| 3 | HTC UNM | 1874 | 614 | 177 | 2665 |
| 4 | Retina UNM, HTC M | 769 | 450 | 102 | 1323 |
| 5 | HTC UNM, Retina M | 215 | 175 | 94 | 484 |
| 6 | Dense Retina UNM, HTC M | 351 | 147 | 33 | 531 |
| 7 | HTC UNM, Dense Retina M | 816 | 428 | 147 | 1391 |
| 8 | HTC UNM, Retina UNM | 1659 | 439 | 83 | 2181 |
| 9 | HTC UNM, Dense Retina UNM | 1058 | 186 | 30 | 1272 |
Dense Retina为将IOU阈值设置为0.05的ReainNet,如果该阈值还没有匹配的话,就说明根本没有匹配上了。
- 在大物体上,两个网络都有一定数量没有匹配上,对比4, 5可知,两个网络没有匹配的种类也不太相同。
- 观察 4, 5,可以知道有大量的小物体是两个网络都没有匹配上的,7更证明了这个事实,并且中小物体也是如此,可以认为这些两个网络都没匹配到的物体是极难匹配的物体,是不可避免的,或者是由于COCO本身的标注,或者是出现crowd的情况。
- 观察与Dense Retina有关的项。对比2,3,Dense Retina在小物体上可以做的更好,只要将Precision提升,就很好了,中、大型物体由于IOU过小不具有先考价值。
总之:RetinaNet依然存在定位不准的情况,另一方面还存在着检测不到的情况。改进前者
用faster rcnn的