PMFS内存文件系统的文件块组织方式以及写流程
由于最近做关于PMFS文件系统的实验,实现了pmfs写文件的数据一致性,还改了PMFS的空间管理,所以想对自己近两个月所做的工作进行一个总结,以下就简单谈谈自己对于PMFS以及拓展知识的理解,如有不对之处还请指出!或者还想了解更多的可以留言讨论。
文章目录
- 介绍
- 文件块组织
- Write
介绍
先简单介绍一下,物理块号,逻辑块号,物理地址,逻辑地址以及虚拟地址之间的关系。
这里围绕PMFS文件系统来展开介绍。假设有1T大小的内存,总共有 1T/4KB个物理块,从10G的位置开始,分出128G大小的空间用于挂载PMFS文件系统,那么PMFS文件系统的起始物理地址就为10G,其起始物理块号就为10G/4KB。还有该分区也有一个固定的起始虚拟地址。
而对于PMFS分区来说总共只有128G/4KB个物理块,那么为了管理方便,PMFS文件系统在分配块时,是从0开始计数的。这就是针对PMFS分区的块号,也就是逻辑块号。块号 * 4KB 就能算出每个块的逻辑地址。所以我对逻辑块号以及逻辑地址的理解就是它只是相对于某个区域来说的,比如说,PMFS分区相对于整个内存,一个文件相对于一个内存分区。在某种特定的时候它亦能称为物理块号和物理地址。
PMFS起始虚拟地址 virt_addr 。
文件在申请块的时候,返回的是逻辑块号logical_block_number;
逻辑地址就等于逻辑块号乘以每个块的大小。logical_address = logical_block_number << 12;
而我们在执行读写操作时都必须使用虚拟地址,虚拟地址就等于逻辑地址加上该分区的起始虚拟地址 virtual_address = logical_address + virt_addr ;
这些关系困扰了我很久,也是最近才搞清楚。
文件块组织
PMFS内存文件系统是用B512树来组织文件块的。如下图所示,B512树是一种B+树,是一种多路搜索树,非叶子结点都有512个儿子。只有叶子结点是数据块,其他都是索引块。一棵树最多只有3层,叶子结点实际为一个指针指向物理块号。
在同一个文件中,每棵树最多只有三层,每个block为4KB,那么一棵树最大能存储的文件大小为:
512 * 512 * 512 * 4KB = 512G。
索引结点的存了每个儿子的逻辑地址。通过逻辑地址又找到下一级的物理块,读取其内容,再次找到下一层结点。
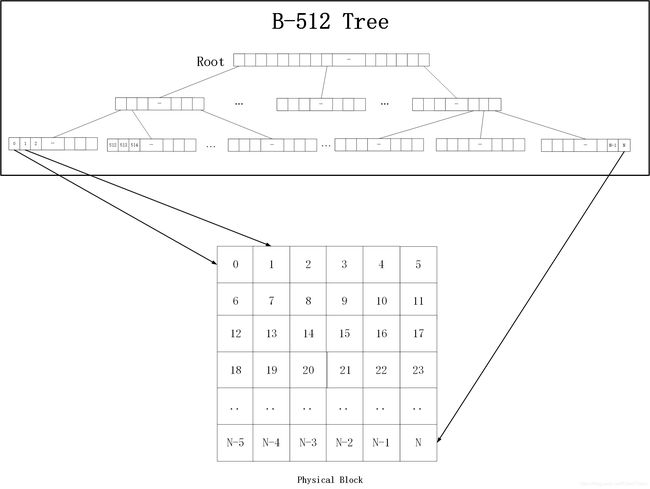
下面我将通过讲写文件代码来将补充上面没说清楚的地方。
Write
write 入口函数:
ssize_t pmfs_xip_file_write(struct file *filp, const char __user *buf,
size_t len, loff_t *ppos)
{
struct address_space *mapping = filp->f_mapping;
struct inode *inode = mapping->host;
struct super_block *sb = inode->i_sb;
pmfs_transaction_t *trans;
struct pmfs_inode *pi;
ssize_t written = 0;
loff_t pos;
u64 block;
bool new_sblk = false, new_eblk = false;
size_t count, offset, eblk_offset, ret;
unsigned long start_blk, end_blk, num_blocks, max_logentries;
bool same_block;
sb_start_write(inode->i_sb);
mutex_lock(&inode->i_mutex);
if (!access_ok(VERIFY_READ, buf, len)) {
ret = -EFAULT;
goto out;
}
pos = *ppos;
count = len;
/* We can write back this queue in page reclaim */
current->backing_dev_info = mapping->backing_dev_info;
ret = generic_write_checks(filp, &pos, &count, S_ISBLK(inode->i_mode));//检查写权限
if (ret || count == 0)
goto out_backing;
pi = pmfs_get_inode(sb, inode->i_ino);//返回pmfs_inode
offset = pos & (sb->s_blocksize - 1);//将pos赋给offset
num_blocks = ((count + offset - 1) >> sb->s_blocksize_bits) + 1;
/* offset in the actual block size block */
offset = pos & (pmfs_inode_blk_size(pi) - 1); //算出块内偏移
//通过pmfs_inode_blk_size算出该文件的粒度,4KB or 2MB or 1GB
start_blk = pos >> sb->s_blocksize_bits; //根据pos算出起始块号。这里的块是文件内的逻辑块号
end_blk = start_blk + num_blocks - 1;
block = pmfs_find_data_block(inode, start_blk);//调用__pmfs_find_data_block
//通过inode,与文件逻辑块号,在该文件的B512树中去寻找该块,获取到该块在PMFS分区的逻辑地址
//如果该块存在,即该文件已经申请了这个块,则返回该块的逻辑地址,反之返回0
/* Referring to the inode's block size, not 4K */
same_block = (((count + offset - 1) >>
pmfs_inode_blk_shift(pi)) == 0) ? 1 : 0;//判断结束位置与start_blk是否在同一个块上。
if (block && same_block) {//如果写在同一块上即执行pmfs_file_write_fast,否则跳过
ret = pmfs_file_write_fast(sb, inode, pi, buf, count, pos, //不分配新的data_block
ppos, block);
goto out_backing;
}
max_logentries = num_blocks / MAX_PTRS_PER_LENTRY + 2;
if (max_logentries > MAX_METABLOCK_LENTRIES)
max_logentries = MAX_METABLOCK_LENTRIES;
trans = pmfs_new_transaction(sb, MAX_INODE_LENTRIES + max_logentries);
if (IS_ERR(trans)) {
ret = PTR_ERR(trans);
goto out_backing;
}
pmfs_add_logentry(sb, trans, pi, MAX_DATA_PER_LENTRY, LE_DATA);
ret = file_remove_suid(filp);
if (ret) {
pmfs_abort_transaction(sb, trans);
goto out_backing;
}
inode->i_ctime = inode->i_mtime = CURRENT_TIME_SEC;
pmfs_update_time(inode, pi);
/* We avoid zeroing the alloc'd range, which is going to be overwritten
* by this system call anyway */
if (offset != 0) {
if (pmfs_find_data_block(inode, start_blk) == 0)
new_sblk = true;
}
eblk_offset = (pos + count) & (pmfs_inode_blk_size(pi) - 1);
if ((eblk_offset != 0) &&
(pmfs_find_data_block(inode, end_blk) == 0))
new_eblk = true;
/* don't zero-out the allocated blocks */
pmfs_alloc_blocks(trans, inode, start_blk, num_blocks, false);
//申请物理块,扩展文件大小。
//根据本次写入数据大小,算出需要多少块,就申请,并将申请得到的块用B512树来管理。
//调用__pmfs_alloc_blocks
/* now zero out the edge blocks which will be partially written */
pmfs_clear_edge_blk(sb, pi, new_sblk, start_blk, offset, false);
pmfs_clear_edge_blk(sb, pi, new_eblk, end_blk, eblk_offset, true);
written = __pmfs_xip_file_write(mapping, buf, count, pos, ppos);
//如果写的起始位置与结束位置不在同一块上,就执行__pmfs_xip_file_write
if (written < 0 || written != count)
pmfs_dbg_verbose("write incomplete/failed: written %ld len %ld"
" pos %llx start_blk %lx num_blocks %lx\n",
written, count, pos, start_blk, num_blocks);
pmfs_commit_transaction(sb, trans);
ret = written;
out_backing:
current->backing_dev_info = NULL;
out:
mutex_unlock(&inode->i_mutex);
sb_end_write(inode->i_sb);
return ret;
}
** __pmfs_find_data_block:**
static inline u64 __pmfs_find_data_block(struct super_block *sb,
struct pmfs_inode *pi, unsigned long blocknr)
//该函数从B512树中一层层遍历寻找blocknr,并返回其逻辑地址
{
__le64 *level_ptr;
u64 bp = 0;
u32 height, bit_shift;
unsigned int idx;
height = pi->height;
bp = le64_to_cpu(pi->root);
while (height > 0) {
level_ptr = pmfs_get_block(sb, bp);//获得bp的虚拟地址
bit_shift = (height - 1) * META_BLK_SHIFT;
idx = blocknr >> bit_shift;
bp = le64_to_cpu(level_ptr[idx]);
if (bp == 0)
return 0;
blocknr = blocknr & ((1 << bit_shift) - 1);
height--;
}
return bp;//返回逻辑地址
}
pmfs_file_write_fast:
static ssize_t pmfs_file_write_fast(struct super_block *sb, struct inode *inode,
struct pmfs_inode *pi, const char __user *buf, size_t count, loff_t pos,
loff_t *ppos, u64 block)
{
void *xmem = pmfs_get_block(sb, block);
size_t copied, ret = 0, offset;
offset = pos & (sb->s_blocksize - 1);
pmfs_xip_mem_protect(sb, xmem + offset, count, 1);
copied = count - __copy_from_user_inatomic_nocache(xmem
+ offset, buf, count);
pmfs_xip_mem_protect(sb, xmem + offset, count, 0);
pmfs_flush_edge_cachelines(pos, copied, xmem + offset);
if (likely(copied > 0)) {
pos += copied;
ret = copied;
}
if (unlikely(copied != count && copied == 0))
ret = -EFAULT;
*ppos = pos;
inode->i_ctime = inode->i_mtime = CURRENT_TIME_SEC;
if (pos > inode->i_size) {
/* make sure written data is persistent before updating
* time and size */
PERSISTENT_MARK();
i_size_write(inode, pos);
PERSISTENT_BARRIER();
pmfs_memunlock_inode(sb, pi);
pmfs_update_time_and_size(inode, pi);
pmfs_memlock_inode(sb, pi);
} else {
u64 c_m_time;
/* update c_time and m_time atomically. We don't need to make the data
* persistent because the expectation is that the close() or an explicit
* fsync will do that. */
c_m_time = (inode->i_ctime.tv_sec & 0xFFFFFFFF);
c_m_time = c_m_time | (c_m_time << 32);
pmfs_memunlock_inode(sb, pi);
pmfs_memcpy_atomic(&pi->i_ctime, &c_m_time, 8);
pmfs_memlock_inode(sb, pi);
}
pmfs_flush_buffer(pi, 1, false);
return ret;
}
__pmfs_alloc_blocks:
int __pmfs_alloc_blocks(pmfs_transaction_t *trans, struct super_block *sb,
struct pmfs_inode *pi, unsigned long file_blocknr, unsigned int num,
bool zero)
{
/*file_blocknr = 0, num = 1 */
int errval;
unsigned long max_blocks;
unsigned int height;
unsigned int data_bits = blk_type_to_shift[pi->i_blk_type];
unsigned int blk_shift, meta_bits = META_BLK_SHIFT;
unsigned long blocknr, first_blocknr, last_blocknr, total_blocks;
/* convert the 4K blocks into the actual blocks the inode is using */
blk_shift = data_bits - sb->s_blocksize_bits;
first_blocknr = file_blocknr >> blk_shift;
last_blocknr = (file_blocknr + num - 1) >> blk_shift;
pmfs_dbg_verbose("alloc_blocks height %d file_blocknr %lx num %x, "
"first blocknr 0x%lx, last_blocknr 0x%lx\n",
pi->height, file_blocknr, num, first_blocknr, last_blocknr);
height = pi->height;
blk_shift = height * meta_bits;
max_blocks = 0x1UL << blk_shift;
if (last_blocknr > max_blocks - 1) {//B-tree需要增加一层
/* B-tree height increases as a result of this allocation */
total_blocks = last_blocknr >> blk_shift;
while (total_blocks > 0) {
total_blocks = total_blocks >> meta_bits;
height++;
}
if (height > 3) {
pmfs_dbg("[%s:%d] Max file size. Cant grow the file\n",
__func__, __LINE__);
errval = -ENOSPC;
goto fail;
}
}
if (!pi->root) {//当这个文件初次写入的时候
if (height == 0) {
__le64 root;
errval = pmfs_new_data_block(sb, pi, &blocknr, zero);
if (errval) {
pmfs_dbg_verbose("[%s:%d] failed: alloc data"
" block\n", __func__, __LINE__);
goto fail;
}
root = cpu_to_le64(pmfs_get_block_off(sb, blocknr,
pi->i_blk_type));
pmfs_memunlock_inode(sb, pi);
pi->root = root;
pi->height = height;
pmfs_memlock_inode(sb, pi);
} else {
errval = pmfs_increase_btree_height(sb, pi, height);
if (errval) {
pmfs_dbg_verbose("[%s:%d] failed: inc btree"
" height\n", __func__, __LINE__);
goto fail;
}
errval = recursive_alloc_blocks(trans, sb, pi, pi->root,
pi->height, first_blocknr, last_blocknr, 1, zero);
if (errval < 0)
goto fail;
}
} else {//该文件已经写入过了
/* Go forward only if the height of the tree is non-zero. */
if (height == 0)
return 0;
if (height > pi->height) {
errval = pmfs_increase_btree_height(sb, pi, height);
if (errval) {
pmfs_dbg_verbose("Err: inc height %x:%x tot %lx"
"\n", pi->height, height, total_blocks);
goto fail;
}
}
errval = recursive_alloc_blocks(trans, sb, pi, pi->root, height,
first_blocknr, last_blocknr, 0, zero);
if (errval < 0)
goto fail;
}
return 0;
fail:
return errval;
}
以上就是关于pmfs写文件的流程,这里就走完了。关于PMFS文件系统还有一些内容,下次有时间再更新。
另外我还写了一篇关于PMFS空间管理的,大家有兴趣可以看看。 https://blog.csdn.net/FZeroTHero/article/details/96476682