Study Notes: OpenMP gramma and notes
1/ OpenMP 只是编译器的拓展,用#pragma directive(编译制导指令)来标注。如果不能并行,编译器只会忽略,串行地执行代码而不会报错。这样的作用是,可以比较方便地平行某段代码而不用大改。
2/ MIMD 和 SIMD最大的区别是,MIMD意思就是用到multi-core而SIMD则是同一个core。
3/使用OpenMP需要在GCC的compiler上加上-fopenmp且如果需要使用内置运行变量需要包含头文件
4/
OpenMP的所有编译制导指令是以#pragma omp开头(注意只是开头,后面还需要指令或者命令组成一个制导指令),之后想新添指令或命令是可以单独出现的。
OpenMP的指令格式是:
#pragmaomp parallel [for | sections] [子句[子句]…]
parallel是用来打开并行域的。Parallel之后需要使用大括号{}把并行域圈起来。指定线程数可以使用num_threads(x)子句。
但是如果仅仅打开了并行域却不分担任务则是浪费了并行计算的价值,所以,需要任务分担语句。任务分担语句有for和sections。其中for语句是只适用于循环,当循环不存在循环依赖时,使用for语句进行任务分担可以把一定范围内的循环次数分给某一个线程,另外for语句有其专门的schedule子句,用来指定不同的策略去分配循环次数给某一个线程:static(事先可以估计的每个线程会有多少个),dynamic(先执行完就先分配,size决定的每次分配的迭代数),guided(递减分配,size指定到多少不再递减),runtime(看情况决定使用上面的任意一种)。
Static是系统默认的for任务分配的调度模式。当static不指定size(每个线程要承担的迭代数)的时候,默认size就是(迭代次数总数/线程数总数),如果不是整数,让前面编号的线程多担待。

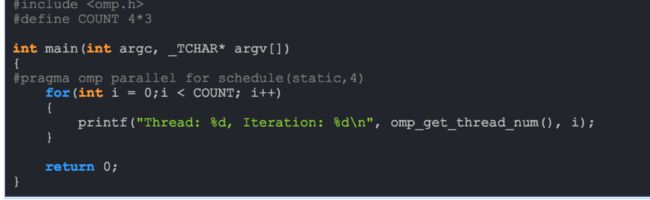
无论是哪一个线程先启动,team内的ID为0的线程,总是会执行0,1,2,3对应的迭代,team内ID为1的线程,总是会执行4,5,6,7对应的迭代,team内ID为2的线程,总是会执行8,9,10,11的线程。
下面说说另外一个任务分担语句:sections
sections和for ordered一样,都是必须在开始说明sections(ordered)然后在里面说明section(ordered)
不同于for的任务分配是计算机自动手配,sections的任务分配是手工的。使用规则如下:
#pragma omp parallel sections{
#pragma omp section{
。。。
}
#pragma omp section{
。。。
}
}
这个例子很好:

sections保证每一个section由不同的thread去运行。但sections之间是串行的。注意的是这种方式需要保证各个section里的代码执行时间相差不大,否则某个section执行时间比其他section过长就造成了其它线程空闲等待的情况。用for语句来分担任务时工作量由系统自动划分,只要每次循环间没有时间上的差异,那么分摊是比较均匀的,使用section来划分线程是一种手工划分工作量的方式,最终负载均衡的好坏得依赖于程序员。
另外,子句有两大作用:① 同步(防止竞争)② 规划数据
同步的方法主要有两种:
(1)利用线程锁
线程锁有三种:critical锁 、 原子atomic锁和lock()互斥锁
i 各个线程逐个进入到critical保护的区域内,任何时刻只有一个线程在执行临界区代码。Critical块是不可嵌套的,但parallel域是可以的,所以不只有master线程可以创建新的线程。
The memory update (read, update, and write) portionoccurs without thread context being switched.
#pragma omp critical(global_name)
critical 可以是一段代码,但是atomic只能是一个语句。
ii 原子锁:利用原子性,要么不执行,要么执行完,确保某一个能转换成机器语言的语句的原子性来保证变量对于所有线程的一致性。
the entire statement occurs without thread context beingswitched.
iii 互斥锁
程序员必须自己保证在调用相应锁操作之后释放相应的锁,否则就可能造成多线程程序的死锁。
互斥锁就是利用API 同步:
void omp_init_lock(omp_lock *) 初始化互斥器
void omp_destroy_lock(omp_lock *) 销毁互斥器
void omp_set_lock(omp_lock *) 获得互斥器
void omp_unset_lock(omp_lock *) 释放互斥器
bool omp_test_lock(omp_lock *) 试图获得互斥器,如果获得成功返回true,否则返回false
使用方法就是先初始化,然后获得,释放。获得与释放之间就相当于critical 部分。

(2)使用路障、(single/master)或者ordered块
路障:
在OpenMP中同步障碍锁(barrier)。线程遇到路障时必须等待,直到并行区域内的所有线程都到达了同一点,才能继续执行下面的代码。在每一个并行域和任务分担域的结束处都会有一个隐含的同步路障,执行此并行域/任务分担域的线程组在执行完毕本区域代码之前,都需要同步并行域的所有线程。也就是说在parallel、for、sections(注意是sections而不是section)和single构造的最后,会有一个隐式的路障。
需要显式插入barrier的时候需要使用:
#pragma omp barrier
但相反的,也有不想使用路障(没必要)为了加速的时候,则可以使用nowait子句去除隐式路障。
如:#pragma omp for nowait
ordered vs critical:
ordered是用在循环的,和schedule一样。Ordered的目的是确保循环体内某段被包含的代码按照循环变量的递增的顺序被执行(所以,同时就确保了每次只有一个线程进入ordered体),但critical不同,只是确定每次只有一个线程进入临界区,但不确保顺序。如果要在循环体内使用#pragma omp ordered 那么循环体的for必须是:#pragmaomp parallel for ordered
single vs master:
用于指定一段代码由主线程执行。master制导指令和single制导指令类似,区别在于,master制导指令包含的代码段只由主线程执行,而single制导指令包含的代码段可由任一线程执行,并且master制导指令在结束处没有隐式同步,也不能指定nowait从句。
而单线程执行single制导指令指定所包含的代码只由一个线程执行,别的线程跳过这段代码。如果没有nowait从句,所有线程在single制导指令结束处隐式同步点同步。如果single制导指令有nowait从句,则别的线程直接向下执行,不在隐式同步点等待;single制导指令用在一段只被单个线程执行的代码段之前,表示后面的代码段将被单线程执行.


说说子句的另外一个作用:规划数据
数据有以下几种规划:
1 共享(shared)
共享变量就是存放在共享内存上的内容,在多线程的环境下,读写共享内存都是需要使用同步锁的,否则竞争会使得内容不确定。另外,比较建议以及常用的处理方法是:把共享变量变为私有变量去读写。如果在并行域内不加锁保护就直接对共享变量进行写操作,存在数据竞争问题,会导致不可预测的异常结果。如果共享数据作为private、firstprivate、lastprivate、threadprivate、reduction子句的参数进入并行域后,就变成线程私有了,不需要加锁保护了。
2 并行域中每个线程私有(private)
需要注意的是,for循环内的循环变量是每个线程私有的,同时在循环体内的变量也是每个线程私有的。即使在并行域外有同名的共享变量,共享变量在并行域内不起任何作用,并且并行域内不会操作到外面的共享变量。*出现在reduction子句中的变量不能出现在private子句中。

for循环前的变量k和循环区域内的变量k其实是两个不同的变量。用private子句声明的私有变量的初始值在并行域的入口处是未定义的,它并不会继承同名共享变量的值。
那么怎么才能继承共享变量的值然后成为私有变量呢?
使用firstprivate子句。
注意,使用仅仅firstprivate的时候,原共享变量的值不变。因为改变的还是复制过来的私有变量。
当然,如果需要把最后的私有变量值更新到同名的共享变量的话,就要再加一个lastprivate。如图:


3 全局的每个线程私有(threadprivate)
private变量在退出并行域后则失效,而threadprivate线程专有变量可以在前后多个并行域之间保持连续性。(copyin 用来将主线程中threadprivate变量的值复制到执行并行域的各个线程的threadprivate变量中,便于所有线程访问主线程中的变量值。and copyprivate 将一个线程私有变量的值广播到执行同一并行域的其他线程。copyprivate子句可以关联single构造,在single构造的barrier到达之前就完成了广播工作。)
4. 归约操作(reduction)
每个线程将创建参数条目的一个私有拷贝,在并行域或任务分担域的结束处,将用私有拷贝的值通过指定的运行符运算,原始的参数条目被运算结果的值更新。列出了可以用于reduction子句的一些操作符以及对应私有拷贝变量缺省的初始值,私有拷贝变量的实际初始值依赖于reduction变量的数据类型:+(0)、-(0)、*(1)、&(~0)、|(0)、^(0)、&&(1)、||(0)。
