Python正则表达式概述
1 re模块操作
在Python中需要通过正则表达式对字符串进行匹配的时候,可以使用一个模块,名字为re
1.1 re模块的使用过程
#coding=utf-8
# 导入re模块
import re
# 使用match方法进行匹配操作
result = re.match(正则表达式,要匹配的字符串)
# 如果上一步匹配到数据的话,可以使用group方法来提取数据
result.group()1.2 re模块示例(匹配以hua_nuan开头的语句)
2. re模块示例(匹配以hua_nuan开头的语句)
#coding=utf-8
import re
result = re.match("hua_nuan","hua_nuan")
result.group()运行结果为:
hua_nuan1.3 说明
- re.match() 能够匹配出以xxx开头的字符串
2 匹配单个字符
在上一小节中,了解到通过re模块能够完成使用正则表达式来匹配字符串
本小节,将要讲解正则表达式的单字符匹配
| 字符 | 功能 |
|---|---|
| . | 匹配任意1个字符(除了\n) |
| [ ] | 匹配[ ]中列举的字符 |
| \d | 匹配数字,即0-9 |
| \D | 匹配非数字,即不是数字 |
| \s | 匹配空白,即 空格,tab键 |
| \S | 匹配非空白 |
| \w | 匹配单词字符,即a-z、A-Z、0-9、_ |
| \W | 匹配非单词字符,即 "/w"的补集,等价于 [^a-zA-Z0-9_] |
注意:小写字母与大写字母hubu
示例1:[ ]
#coding=utf-8
import re
# 如果hello的首字符小写,那么正则表达式需要小写的h
ret = re.match("h","hello Python")
print(ret.group())
# 如果hello的首字符大写,那么正则表达式需要大写的H
ret = re.match("H","Hello Python")
print(ret.group())
# 大小写h都可以的情况
ret = re.match("[hH]","hello Python")
print(ret.group())
ret = re.match("[hH]","Hello Python")
print(ret.group())
ret = re.match("[hH]ello Python","Hello Python")
print(ret.group())
#ret = re.match("hello","Hello",re.I)
#print(ret.group()) #忽略大小写ignore-----Hello
# 匹配0到9第一种写法
ret = re.match("[0123456789]Hello Python","7Hello Python")
print(ret.group())
# 匹配0到9第二种写法
ret = re.match("[0-9]Hello Python","7Hello Python")
print(ret.group())
ret = re.match("[0-35-9]Hello Python","7Hello Python")
print(ret.group())
# 下面这个正则不能够匹配到数字4,因此ret为None
ret = re.match("[0-35-9]Hello Python","4Hello Python")
# print(ret.group())运行结果:
h
H
h
H
Hello Python
7Hello Python
7Hello Python
7Hello Python示例2:\d
#coding=utf-8
import re
# 普通的匹配方式
ret = re.match("嫦娥1号","嫦娥1号发射成功")
print(ret.group())
ret = re.match("嫦娥2号","嫦娥2号发射成功")
print(ret.group())
ret = re.match("嫦娥3号","嫦娥3号发射成功")
print(ret.group())
# 使用\d进行匹配
ret = re.match("嫦娥\d号","嫦娥1号发射成功")
print(ret.group())
ret = re.match("嫦娥\d号","嫦娥2号发射成功")
print(ret.group())
ret = re.match("嫦娥\d号","嫦娥3号发射成功")
print(ret.group())运行结果:
嫦娥1号
嫦娥2号
嫦娥3号
嫦娥1号
嫦娥2号
嫦娥3号
3 匹配多个字符
匹配多个字符的相关格式
| 字符 | 功能 |
|---|---|
| * | 匹配前一个字符出现0次或者无限次,即可有可无 |
| + | 匹配前一个字符出现1次或者无限次,即至少有1次 |
| ? | 匹配前一个字符出现1次或者0次,即要么有1次,要么没有 |
| {m} | 匹配前一个字符出现m次 |
| {m,n} | 匹配前一个字符出现从m到n次 |
##{m,} 加上逗号,一个字符出现m到无限次
示例1:*
需求:匹配出,一个字符串第一个字母为大小字符,后面都是小写字母并且这些小写字母可有可无
#coding=utf-8
import re
ret = re.match("[A-Z][a-z]*","M")
print(ret.group())
ret = re.match("[A-Z][a-z]*","MnnM")
print(ret.group())
ret = re.match("[A-Z][a-z]*","Aabcdef")
print(ret.group())
"""
ret = re.match("[A-Z][a-z]*","Aabcdef") #Aabcdef
表示:[A-Z]([a-z][a-z][a-z][a-z][a-z][a-z][a-z][a-z].....)
"""运行结果:
M
Mnn
Aabcdef示例2:+
需求:匹配出,变量名是否有效
+ 匹配前一个字符出现1次或者无限次,即至少有1次 ####表示匹配前面的规则至少 1 次,可以多次匹配
#coding=utf-8
import re
names = ["name1", "_name", "2_name", "__name__"]
for name in names:
ret = re.match("[a-zA-Z_]+[\w]*",name)
if ret:
print("变量名 %s 符合要求" % ret.group())
else:
print("变量名 %s 非法" % name)运行结果:
变量名 name1 符合要求
变量名 _name 符合要求
变量名 2_name 非法
变量名 __name__ 符合要求示例3:?
需求:匹配出,0到99之间的数字
#coding=utf-8
import re
ret = re.match("[1-9]?[0-9]","7")
print(ret.group())
ret = re.match("[1-9]?\d","33")
print(ret.group())
ret = re.match("[1-9]?\d","09")
print(ret.group())运行结果:
7
33
0 # 这个结果并不是想要的,利用$才能解决? 匹配前一个字符出现1次或者0次,要么有1次,要么没有。ret = re.match("[1-9]?\d","789")即[1-9]?可没有 ,和\d组成)
示例4:{m}
需求:匹配出,8到20位的密码,可以是大小写英文字母、数字、下划线
#coding=utf-8
import re
ret = re.match("[a-zA-Z0-9_]{6}","12a3g45678")
print(ret.group())
ret = re.match("[a-zA-Z0-9_]{8,20}","1ad12f23s34455ff66")
print(ret.group())
运行结果:
12a3g4
1ad12f23s34455ff664 匹配开头结尾
| 字符 | 功能 |
|---|---|
| ^ | 匹配字符串开头 |
| $ | 匹配字符串结尾 (到此处结尾,后面没有内容,有内容报错) |
示例1:$
需求:匹配163.com的邮箱地址
#coding=utf-8
import re
email_list = ["[email protected]", "[email protected]", "[email protected]"]
for email in email_list:
ret = re.match("[\w]{4,20}@163\.com", email)
if ret:
print("%s 是符合规定的邮件地址,匹配后的结果是:%s" % (email, ret.group()))
else:
print("%s 不符合要求" % email)
运行结果:
[email protected] 是符合规定的邮件地址,匹配后的结果是:[email protected]
[email protected] 是符合规定的邮件地址,匹配后的结果是:[email protected]
[email protected] 不符合要求
完善后
email_list = ["[email protected]", "[email protected]", "[email protected]"]
for email in email_list:
ret = re.match("[\w]{4,20}@163\.com$", email)
if ret:
print("%s 是符合规定的邮件地址,匹配后的结果是:%s" % (email, ret.group()))
else:
print("%s 不符合要求" % email)
运行结果:
[email protected] 是符合规定的邮件地址,匹配后的结果是:[email protected]
[email protected] 不符合要求
[email protected] 不符合要求5 匹配分组
| 字符 | 功能 |
|---|---|
| | | 匹配左右任意一个表达式 |
| (ab) | 将括号中字符作为一个分组 |
\num |
引用分组num匹配到的字符串 |
(?P |
分组起别名 |
| (?P=name) | 引用别名为name分组匹配到的字符串 |
示例1:|
需求:匹配出0-100之间的数字
#coding=utf-8
import re
ret = re.match("[1-9]?\d","8")
print(ret.group()) # 8
ret = re.match("[1-9]?\d","78")
print(ret.group()) # 78
# 不正确的情况
ret = re.match("[1-9]?\d","08")
print(ret.group()) # 0
# 修正之后的
ret = re.match("[1-9]?\d$","08")
if ret:
print(ret.group())
else:
print("不在0-100之间")
# 添加|
ret = re.match("[1-9]?\d$|100","8")
print(ret.group()) # 8
ret = re.match("[1-9]?\d$|100","78")
print(ret.group()) # 78
ret = re.match("[1-9]?\d$|100","08")
# print(ret.group()) # 不是0-100之间
ret = re.match("[1-9]?\d$|100","100")
print(ret.group()) # 100
示例2:( )
需求:匹配出163、126、qq邮箱
#coding=utf-8
import re
ret = re.match("\w{4,20}@163\.com", "[email protected]")
print(ret.group()) # [email protected]
ret = re.match("\w{4,20}@(163|126|qq)\.com", "[email protected]")
print(ret.group()) # [email protected]
ret = re.match("\w{4,20}@(163|126|qq)\.com", "[email protected]")
print(ret.group()) # [email protected]
ret = re.match("\w{4,20}@(163|126|qq)\.com", "[email protected]")
if ret:
print(ret.group())
else:
print("不是163、126、qq邮箱") # 不是163、126、qq邮箱
不是以4、7结尾的手机号码(11位)
import re
tels = ["13100001234", "18912344321", "10086", "18800007777"]
for tel in tels:
ret = re.match("1\d{9}[0-35-68-9]", tel)
if ret:
print(ret.group())
else:
print("%s 不是想要的手机号" % tel)
提取区号和电话号码
>>> ret = re.match("([^-]*)-(\d+)","010-12345678")
>>> ret.group()
'010-12345678'
>>> ret.group(1)
'010'
>>> ret.group(2)
'12345678'
示例3:\
需求:匹配出hh
#coding=utf-8
import re
# 能够完成对正确的字符串的匹配
ret = re.match("<[a-zA-Z]*>\w*", "hh")
print(ret.group())
# 如果遇到非正常的html格式字符串,匹配出错
ret = re.match("<[a-zA-Z]*>\w*", "hh")
print(ret.group())
# 正确的理解思路:如果在第一对<>中是什么,按理说在后面的那对<>中就应该是什么
# 通过引用分组中匹配到的数据即可,但是要注意是元字符串,即类似 r""这种格式
ret = re.match(r"<([a-zA-Z]*)>\w*", "hh")
print(ret.group())
# 因为2对<>中的数据不一致,所以没有匹配出来
test_label = "hh"
ret = re.match(r"<([a-zA-Z]*)>\w*", test_label)
if ret:
print(ret.group())
else:
print("%s 这是一对不正确的标签" % test_label)
运行结果:
hh
hh
hh
hh 这是一对不正确的标签
示例4:\number
需求:匹配出www.itcast.cn
#coding=utf-8
import re
labels = ["www.itcast.cn
", "www.itcast.cn"]
for label in labels:
ret = re.match(r"<(\w*)><(\w*)>.*", label)
if ret:
print("%s 是符合要求的标签" % ret.group())
else:
print("%s 不符合要求" % label)
运行结果:
www.itcast.cn
是符合要求的标签
www.itcast.cn 不符合要求
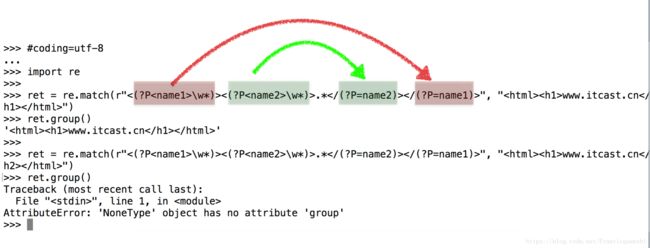
示例5:(?P) (?P=name)
需求:匹配出www.itcast.cn
#coding=utf-8
import re
ret = re.match(r"<(?P\w*)><(?P\w*)>.*", "www.itcast.cn
")
ret.group()
ret = re.match(r"<(?P\w*)><(?P\w*)>.*", "www.itcast.cn")
ret.group()
注意:(?P) 和(?P=name)中的字母p大写
运行结果:
6 re模块的高级用法
6.1 search
需求:匹配出文章阅读的次数
#coding=utf-8
import re
ret = re.search(r"\d+", "阅读次数为 9999")
ret.group()
运行结果:
'9999'
6.2 findall
需求:统计出python、c、c++相应文章阅读的次数
#coding=utf-8
import re
ret = re.findall(r"\d+", "python = 9999, c = 7890, c++ = 12345")
print(ret)
运行结果:
['9999', '7890', '12345']
6.3 sub 将匹配到的数据进行替换
需求:将匹配到的阅读次数加1
方法1:
#coding=utf-8
import re
ret = re.sub(r"\d+", '998', "python = 997")
print(ret)
运行结果:
python = 998
方法2:
#coding=utf-8
import re
def add(temp):
strNum = temp.group()
num = int(strNum) + 1
return str(num)
ret = re.sub(r"\d+", add, "python = 997")
print(ret)
ret = re.sub(r"\d+", add, "python = 99")
print(ret)
运行结果:
python = 998
python = 100
6.4 练习
从下面的字符串中取出文本
岗位职责:
完成推荐算法、数据统计、接口、后台等服务器端相关工作
必备要求:
良好的自我驱动力和职业素养,工作积极主动、结果导向
技术要求:
1、一年以上 Python 开发经验,掌握面向对象分析和设计,了解设计模式
2、掌握HTTP协议,熟悉MVC、MVVM等概念以及相关WEB开发框架
3、掌握关系数据库开发设计,掌握 SQL,熟练使用 MySQL/PostgreSQL 中的一种
4、掌握NoSQL、MQ,熟练使用对应技术解决方案
5、熟悉 Javascript/CSS/HTML5,JQuery、React、Vue.js
加分项:
大数据,数理统计,机器学习,sklearn,高性能,大并发。
参考答案:
re.sub(r"<[^>]*>| |\n", "", test_str)
6.5 split 根据匹配进行切割字符串,并返回一个列表
需求:切割字符串“info:xiaoZhang 33 shandong”
#coding=utf-8
import re
ret = re.split(r":| ","info:xiaoZhang 33 shandong")
print(ret)
运行结果:
['info', 'xiaoZhang', '33', 'shandong']
7 python贪婪和非贪婪
Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;
非贪婪则相反,总是尝试匹配尽可能少的字符。
在"*","?","+","{m,n}"后面加上?,使贪婪变成非贪婪。
>>> s="This is a number 234-235-22-423"
>>> r=re.match(".+(\d+-\d+-\d+-\d+)",s)
>>> r.group(1)
'4-235-22-423'
>>> r=re.match(".+?(\d+-\d+-\d+-\d+)",s)
>>> r.group(1)
'234-235-22-423'
>>>
正则表达式模式中使用到通配字,那它在从左到右的顺序求值时,会尽量“抓取”满足匹配最长字符串,在我们上面的例子里面,“.+”会从字符串的启始处抓取满足模式的最长字符,其中包括我们想得到的第一个整型字段的中的大部分,“\d+”只需一位字符就可以匹配,所以它匹配了数字“4”,而“.+”则匹配了从字符串起始到这个第一位数字4之前的所有字符。
解决方式:非贪婪操作符“?”,这个操作符可以用在"*","+","?"的后面,要求正则匹配的越少越好。
>>> re.match(r"aa(\d+)","aa2343ddd").group(1)
'2343'
>>> re.match(r"aa(\d+?)","aa2343ddd").group(1)
'2'
>>> re.match(r"aa(\d+)ddd","aa2343ddd").group(1)
'2343'
>>> re.match(r"aa(\d+?)ddd","aa2343ddd").group(1)
'2343'
>>>
练一练
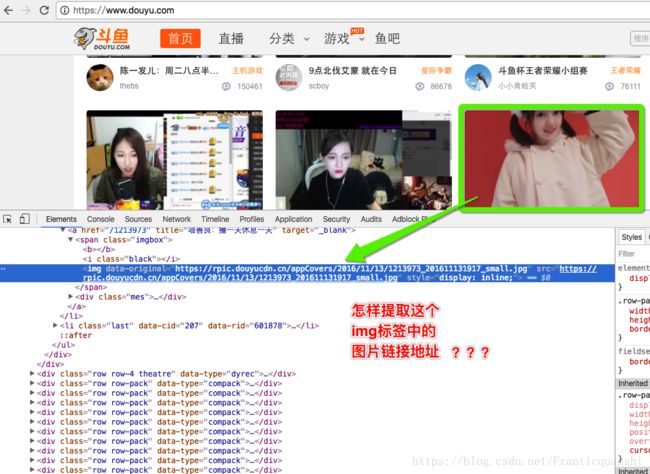
字符串为:

请提取url地址
参考答案
re.search(r"https://.*?\.jpg", test_str)
8 r的作用
>>> mm = "c:\\a\\b\\c"
>>> mm
'c:\\a\\b\\c'
>>> print(mm)
c:\a\b\c
>>> re.match("c:\\\\",mm).group()
'c:\\'
>>> ret = re.match("c:\\\\",mm).group()
>>> print(ret)
c:\
>>> ret = re.match("c:\\\\a",mm).group()
>>> print(ret)
c:\a
>>> ret = re.match(r"c:\\a",mm).group()
>>> print(ret)
c:\a
>>> ret = re.match(r"c:\a",mm).group()
Traceback (most recent call last):
File "", line 1, in
AttributeError: 'NoneType' object has no attribute 'group'
>>>
说明
Python中字符串前面加上 r 表示原生字符串,
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。
Python里的原生字符串很好地解决了这个问题,有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
>>> ret = re.match(r"c:\\a",mm).group()
>>> print(ret)
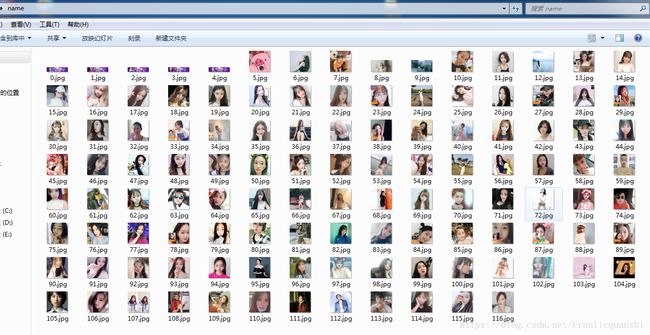
c:\a9 实战演练(抓取斗鱼网页美女照片)
打开网站,将网页源代码复制到文件1.txt中,运行以下代码即可:.
#1.单协程操作
import re
import gevent
import urllib.request
from gevent import monkey
monkey.patch_all()
def down_loader(img_name,img_url):
req = urllib.request.urlopen(img_url)
img = req.read()
with open("/home/python/Desktop/name/"+img_name,"wb") as q:
q.write(img)
def main():
with open("/home/python/Desktop/1.txt","rb") as f:
content = f.read().decode("utf-8")
# print(content)
rets = re.findall(r"https://.*?\.jpg",content)
# print(rets)
for i in range(len(rets)):
g=gevent.spawn(down_loader,str("%d"%i)+".jpg",rets[i])
g.join()
if __name__ == '__main__':
main()#2.多协程操作
import re
import gevent
import urllib.request
from gevent import monkey
monkey.patch_all()
def down_loader(img_name,img_url):
req = urllib.request.urlopen(img_url)
img = req.read()
with open("/home/python/Desktop/name/"+img_name,"wb") as q:
q.write(img)
def main():
img_list_spawn = []
with open("/home/python/Desktop/1.txt","rb") as f:
content = f.read().decode("utf-8")
# print(content)
rets = re.findall(r"https://.*?\.jpg",content)
# print(rets)
i = 1
for img_url in rets:
img_list_spawn.append(gevent.spawn(down_loader,str(i)+".jpg",img_url))
i += 1
gevent.joinall(img_list_spawn)
if __name__ == '__main__':
main()效果: