Tensorflow搭建多GPU框架集成SRCNN模型,支持模型切换、数据制作、测试
近日,随着实验的深入,实验规模也越来越大,单张GPU的算力不够,同时,我又经常需要测试不同的模型,每次都搭建一个框架会很麻烦,所以我这次让框架与模型分离,以后只需要修改一点点内容就能马上上运行了
原理
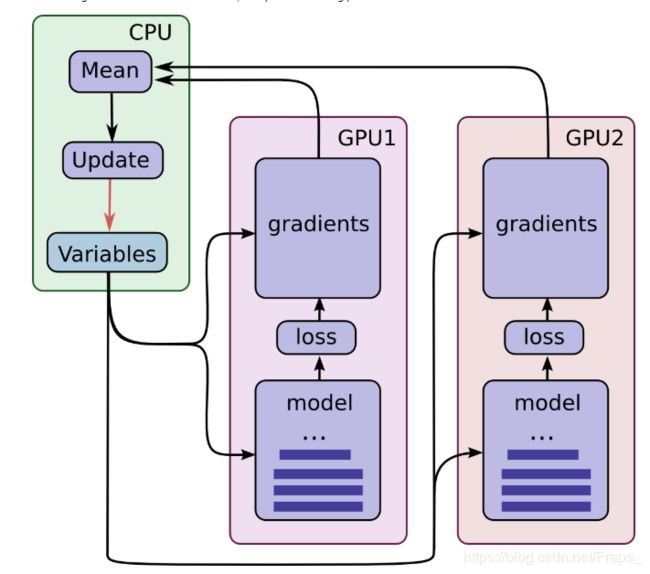
Tensorflow多GPU运算有两种模式:异步模式,同步模式。异步模式时,不同GPU各自运行反向传播算法并独立的更新数据,这种模式理论上最快但是可能无法达到较优的训练结果。在同步模式下,各个GPU完成反向传播完成后,CPU计算所有GPU梯度的平均值,最后一起更新所有的的参数,这个过程会出现GPU等待参数更新,这使得效率降低了。但是,在同一台服务器上的GPU一般型号是一样的,算力一样,浪费的时间还能接受,所以选择同步训练模式。
同步计算模式如下图:
项目文件目录如下
-----NNN-CMQ
|
–checkpoint
|
–logs
|
–Test
|
–Train
|
–generateH5.py
|
–NNN.py
|
–Train.py
|
–modelFrame.py
主干:main.py
在main.py里面设置各种超参和各种标识。
超参与标识:
parser = argparse.ArgumentParser()
parser.add_argument("--imgsize",default=30,type=int)
parser.add_argument("--output_channels",default=1,type=int)
parser.add_argument("--scale",default=3,type=int)
parser.add_argument("--resBlocks",default=2,type=int)
parser.add_argument("--featuresize",default=4,type=int)#32
parser.add_argument("--batchsize",default=32,type=int)
parser.add_argument("--savedir",default='checkpoint')
parser.add_argument("--saveID",default='2',type=int)#1
parser.add_argument("--model_name",default='WSDR_A')
parser.add_argument("--logs",default='logs')
parser.add_argument("--reGenerateH5",default=False,type=bool)
parser.add_argument("--epoch",default=50,type=int)
parser.add_argument("--isTrain",default=True,type=bool)
os.environ["CUDA_VISIBLE_DEVICES"] = "0,1"
gpus = os.getenv('CUDA_VISIBLE_DEVICES')
parser.add_argument("--gpus",default=gpus)
args = parser.parse_args()
接下来组织数据制作类、多GPU框架、测试:
#session配置参数,把不能用GPU的操作放大CPU上
config = tf.ConfigProto(allow_soft_placement=True)
with tf.Session(config=config) as sess:
#时候制作数据集,我用的是H5,以后要换成dataset
if(args.reGenerateH5):
data(args)
#调用搭建多gpu框架的类
network = modelFrame(args,sess)
if (args.isTrain == True):
network.trainMultiGpus()#训练
else:
network.resume(args.savedir)
network.test()#测试
数据集制作:GenerateH5.py
这里的py文件是一个类,用来制作H5数据。这里需要手动设置好储存数据的位置、图片的类型、
class data(object):
def __init__(self, args):
is_train = True
imgsize = 90
imgchannel = 1
scale = 3
savepath="checkpoint"
data_dir = "../SRimage/Train"
if is_train:
```
这里写训练数据的制作
```
dir = os.path.join(data_dir,"*.tif")
data = glob.glob(dir)
random.shuffle(data)
sub_input_sequence = []
sub_label_sequence = []
```
中间过程...
```
sub_input_sequence = np.asarray(sub_input_sequence)
sub_label_sequence = np.asarray(sub_label_sequence)
#置乱
permutation = np.random.permutation(len(sub_input_sequence))
shuffled_input = sub_input_sequence[permutation, :, :, :]
shuffled_label = sub_label_sequence[permutation, :, :, :]
with h5py.File(savepath+"/data_train.h5", 'w') as hf:
hf.create_dataset('train_input', data=shuffled_input)
hf.create_dataset('train_label', data=shuffled_label)
else:
```
这里写测试数据...
```
主框架:modelFrame.py
找个py文件是模型类,里面包含了多gpus搭建:
class modelFrame(object):
def __init__(self,args,sess):
#这里设置各种超参
self.args = args
self.sess = sess
self.img_size = args.imgsize
self.output_channels = args.output_channels
self.scale = args.scale
self.num_layers = args.resBlocks
self.feature_size = args.featuresize
self.batch_size = args.batchsize
self.savedir = args.savedir
self.saveID = args.saveID
self.model_name = args.model_name
self.logs = args.logs
self.epoch = args.epoch
self.isTrain = args.isTrain
self.gpus = args.gpus.split(',')
# 开始搭建多GPU框架,注意对照上文的图片理解
#先在cpu定义一些操作
with tf.device("/cpu:0"):
global_step = tf.train.get_or_create_global_step()
tower_grads = []
#定义输入
self.X = tf.placeholder(tf.float32, [None, self.img_size, self.img_size, self.output_channels],
name="images")
self.Y = tf.placeholder(tf.float32, [None, 21, 21, self.output_channels], name="labels")
opt = tf.train.AdamOptimizer(0.001)
count = 0
with tf.variable_scope(tf.get_variable_scope()):
for i in self.gpus:
with tf.device("/gpu:%c" % i): # 这里考虑到有时候后gpu会选择 2,3 或者1,3 这种奇怪的情况,所以不是递增的
with tf.name_scope("tower_%c" % i):
#没一个tower对应一张显卡,这里设置其对应的batch
_x = self.X[count * self.batch_size:(count + 1) * self.batch_size]
_y = self.Y[count * self.batch_size:(count + 1) * self.batch_size]
#调用模型类,构建网络
self.out = SRCNN(self.args, _x).getNet()
# 计算参数量
print("total-", self.get_total_params())
self.loss = tf.reduce_mean(tf.squared_difference(_y, self.out))
tf.summary.scalar("loss", self.loss)
grads = opt.compute_gradients(self.loss)
opt.apply_gradients(grads)
tower_grads.append(grads)
```
注意这里,必须放在计算梯度后,不然会报错,具体跟adm优化器有关,自己可以去测试一哈
```
tf.get_variable_scope().reuse_variables()
PSNR = tf.image.psnr(_y, self.out, max_val=1.0)
PSNR = tf.reduce_sum(PSNR)
PSNR = tf.div(PSNR, self.batch_size)
tf.summary.scalar('PSNR', PSNR)
if count == 0:
self.testNet = self.out
count =count+1
grads = self.average_gradients(tower_grads)#计算所有的gpu上的平均梯度
self.train_op = opt.apply_gradients(grads)
self.merged = tf.summary.merge_all()
logName = "%s_%s_%s_%s" % (self.model_name, self.num_layers, self.feature_size, self.saveID)
self.logs_dir = os.path.join(self.logs, logName)
if not os.path.exists(self.logs_dir):
os.makedirs(self.logs_dir)
self.train_writer = tf.summary.FileWriter(self.logs_dir, self.sess.graph)
self.saver = tf.train.Saver()
保存与恢复模型
def save(self, checkpoint_dir, step):
model_dir = "%s_%s_%s_%s" % (self.model_name, self.num_layers, self.feature_size, self.saveID)
checkpoint_dir = os.path.join(checkpoint_dir, model_dir)
if not os.path.exists(checkpoint_dir):
os.makedirs(checkpoint_dir)
self.saver.save(self.sess, os.path.join(checkpoint_dir, self.model_name), global_step=step)
def resume(self, checkpoint_dir):
print(" [*] Reading checkpoints...")
model_dir = "%s_%s_%s_%s" % (self.model_name, self.num_layers, self.feature_size, self.saveID)
checkpoint_dir = os.path.join(checkpoint_dir, model_dir)
ckpt = tf.train.get_checkpoint_state(checkpoint_dir)
if ckpt and ckpt.model_checkpoint_path:
ckpt_name = os.path.basename(ckpt.model_checkpoint_path)
self.saver.restore(self.sess, os.path.join(checkpoint_dir, ckpt_name))
print("Reading sucess!")
return True
else:
return False
计算平均梯度
def average_gradients(self, tower_grads):
average_grads = []
for grad_and_vars in zip(*tower_grads):
grads = []
for g, _ in grad_and_vars:
expend_g = tf.expand_dims(g, 0)
grads.append(expend_g)
grad = tf.concat(grads, 0)
grad = tf.reduce_mean(grad, 0)
v = grad_and_vars[0][1]
grad_and_var = (grad, v)
average_grads.append(grad_and_var)
return average_grads
获得所有的参数
def get_total_params(self):
num_params = 0
for variable in tf.trainable_variables():
shape = variable.get_shape()
num_params += reduce(mul, [dim.value for dim in shape], 1)#这里要导入两个包
return num_params
模型的预测
def predict(self):
print("Predicting...")
def test(self):
print("test!")
模型:NNN.py
这里的模型是任意的,只要实现getNet()函数,返回网路的输出,就能做到与框架无关,以后,搭建新的模型,十分简单。
class SRCNN(object):
def __init__(self,args,x):#初始化函数需要输入网络的输入
self.image_size = 33
self.label_size = 21
self.batch_size = 128
self.weights = {
'w1': tf.Variable(tf.random_normal([9, 9, 1, 64], stddev=1e-3), name='w1'),
'w2': tf.Variable(tf.random_normal([1, 1, 64, 32], stddev=1e-3), name='w2'),
'w3': tf.Variable(tf.random_normal([5, 5, 32, 1], stddev=1e-3), name='w3')
}
self.biases = {
'b1': tf.Variable(tf.zeros([64]), name='b1'),
'b2': tf.Variable(tf.zeros([32]), name='b2'),
'b3': tf.Variable(tf.zeros([1]), name='b3')
}
conv1 = tf.nn.relu(
tf.nn.conv2d(x, self.weights['w1'], strides=[1, 1, 1, 1], padding='VALID') + self.biases['b1'])
conv2 = tf.nn.relu(
tf.nn.conv2d(conv1, self.weights['w2'], strides=[1, 1, 1, 1], padding='VALID') + self.biases['b2'])
conv3 = tf.nn.conv2d(conv2, self.weights['w3'], strides=[1, 1, 1, 1], padding='VALID') + self.biases['b3']
self.out = conv3
#返回网络的输出
def getNet(self):
return self.out
所有代码
所有代码已经提交到github,需要的请下载,如果对你有帮助,请给个星星
link.