《高性能MySQL》读书笔记--多版本并发控制算法
1.AUTOCOMMIT
MySQL采用默认自动提交,可以通过如下命令查看和修改:
mysql> SHOW VARIABLES LIKE 'AUTOCOMMIT';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | ON |
+---------------+-------+
1 row in set (0.00 sec)
mysql> SET AUTOCOMMIT = 1;
2.隐式锁显式锁
InnoDB在开启事务时,获取隐式锁,在事务提交或者回滚时释放锁,InnoDB根据隔离级别在需要的时候自动加锁。
但InnoDB也支持显式锁:
SELECT ... FOR UPDATE
SELECT ... LOCK IN SHARE MODE
这是在服务器层实现的,和存储引擎无关。本书建议除了禁用了AUTOCOMMIT,可以使用LOCK_TABLES之外,其他任何时候都不要显示地执行LOCK TABLES,不管使用的是什么存储引擎。
3.多版本并发控制(Multiversion Concurrency Controll MVCC)
第一点:
MVCC并不是MySql独有的,Oracle,PostgreSQL等都在使用。
MVCC并没有简单地使用行锁,而是使用“行级别锁”(row-level locking)。
MVCC的基本原理是:
MVCC的实现,通过保存数据在某个时间点的快照来实现的。这意味着一个事务无论运行多长时间,在同一个事务里能够看到数据一致的视图。根据事务开始的时间不同,同时也意味着在同一个时刻不同事务看到的相同表里的数据可能是不同的。
MVCC的基本特征:
- 每行数据都存在一个版本,每次数据更新时都更新该版本。
- 修改时Copy出当前版本随意修改,各个事务之间无干扰。
- 保存时比较版本号,如果成功(commit),则覆盖原记录;失败则放弃copy(rollback)
InnoDB存储引擎MVCC的实现策略:
在每一行数据中额外保存两个隐藏的列:当前行创建时的版本号和删除时的版本号(可能为空)。这里的版本号并不是实际的时间值,而是系统版本号。每开始 个新的事务,系统版本号都会自动递增。事务开始时刻的系统版本号会作为事务的版本号,用来和查询每行记录的版本号进行比较。
每个事务又有自己的版本号,这样事务内执行CRUD操作时,就通过版本号的比较来达到数据版本控制的目的。具体做法见下面的示意图。
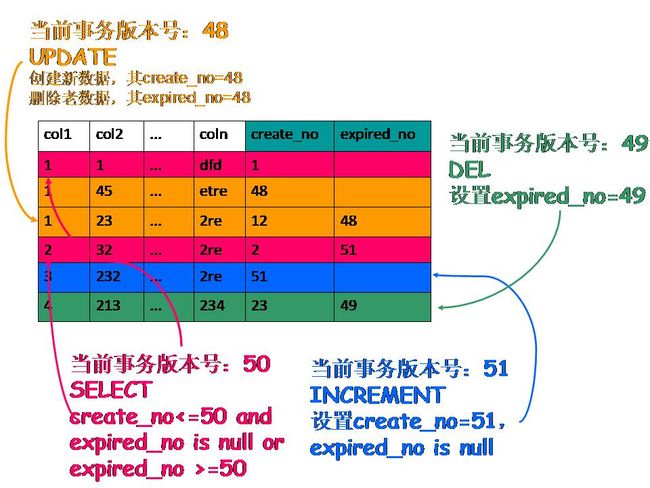
MVCC具体的操作如下:
SELECT:InnoDB会根据以下两个条件检查每行记录:
1)InnoDB只查找版本早于当前事务版本的数据行(也就是,行的系统版本号小于或等于事务的系统版本号),这样可以确保事务读取的行,只么是在事务开始前已经存在的,要么是事务自身插入或者修改过的。
2)行的删除版本要么未定义,要么大于当前事务版本号。这可以确保事务读取到的行,在事务开始之前未被删除。
INSERT:InnoDB为新插入的每一行保存当前系统版本号作为行版本号。
DELETE:InnoDB为删除的每一行保存当前系统版本号作为行删除标识。
UPDATE:InnoDB为插入一行新记录,保存当前系统版本号作为行版本号,同时保存当系统的版本号为原来的行作为删除标识。
保存这两个额外系统版本号,使大多数操作都可以不用加锁。这样设计使得计数据操作很简单,性能很好,并且也能保证只会读取到符合标准的行。不足之处是每行记录都需要额外的存储空间,需要做更多的行检查工作,以及一些额外的维护工作。
MVCC只在REPEATABLE READ和READ COMMITED两个隔离级别下工作,其它两个隔离级别和MVCC不兼容。