地址空间
地址空间
文章目录
- 地址空间
- @[toc]
- MMU(内存管理单元)
- 分段单元
- 分页段元
- 实模式与保护模式
- 页
- 页分配
- 地址分配
- slab层
- slab结构
- 高速缓存创建
- 小结
文章目录
- 地址空间
- @[toc]
- MMU(内存管理单元)
- 分段单元
- 分页段元
- 实模式与保护模式
- 页
- 页分配
- 地址分配
- slab层
- slab结构
- 高速缓存创建
- 小结
MMU(内存管理单元)
分段单元
CPU通过MMU的分段单元将逻辑地址转换为线性地址.
逻辑地址到线性地址的变换过程使用全局描述符表(GDT)和局部描述符表(LDT)
在分段单元中, 将逻辑地址分成[段标识符 : 段偏移量]
- 通过段标识符在描述符表中找到相应的段描述符. 同时将段描述符保存在 非编程寄存器 中, 以便下次找相同的段时不必在查表.
- 通过段描述符找到在分段单元中对应的段头地址.
- 最后通过段偏移量就能找到线性地址.
逻辑地址范围 > 线性地址范围 也就会出现多个逻辑地址映射在同一个线性地址上.
关于逻辑地址的作用
在一个进程中, 地址寻址是采用的是逻辑地址, 指针指向的地址也是逻辑地址, 而不是直接指向线性地址甚至物理地址. 所有的偏移量也是相对于该进程的首地址的. 因为一个进程是有它自己的页目录和页表集, 所以进程每次转成物理地址只需要在自己页中进行偏移就行了.
综上 : 逻辑地址都是相对于进程而言的
分页段元
线性地址通过MMU的分页单元, 将线性地址转为物理地址.
具体的工作流程
- 在MMU通过分页单元, 先通过TLB缓存快速的查找有没有对应的地址, 若有, 立即查表输出对应的物理地址, 若缓存没命中, 然后继续以下步骤
- 在分页单元, 通过传送过来的线性地址, 将其拆分成两段, 一段用来查找对应的页目录地址, 并将地址存放在cr3寄存器中(页目录的地址, 这是物理地址)方便下次局部命中的查找效率. 另一段用来标记在页表中的偏移量.
- 再将查找到的地址段周围的地址也一起传送到TLB中, 刷新部分缓存的地址(实现缓存的局部性)(刷新部分 : 因为TLB中有一些地址还是会经常会用, 不会刷新所有的, 不过进程切换会将TLB中的大部分缓存刷新)
- 最坏的情况是MMU页表中也没有存放要转化的线性地址, 那么只能产生一个异常, 从内存或磁盘读取相应新的物理地址刷新存放在MMU中的部分地址
线性地址范围 > 物理地址范围, 也就会出现多个线性地址映射在同一个物理地址上, 可实现数据共享.
关于分页
现代操作系统都使用分页来管理内存,分页可以让每个进程都有完整的虚拟地址空间,进程间的虚拟地址空间相互隔离以提供页层级的保护。另外分页可以让物理地址空间少于虚拟地址空间,同时可以使用磁盘存储暂时未使用的内存页,提供更多的"内存空间"。
实模式与保护模式
在实模式下, 也就还没有开启分页功能, 所以此时的线性地址就是代表真实的物理地址.这种情况是发生在内核初始化第一阶段, 而临时页全局目录实在内核静态编译时初始化的.
保护模式下, 内核启动了分页功能, 所以此时进程访问的地址需要 逻辑地址–> 线性地址 -->物理地址. 启动分页功能是发生在内核初始化的第二阶段, 建立页全局目录, 分页集.
所以在内核初始化完后, 此时才有内核态与用户态的划分
页
页分配
关于页的结构以及页的分配, 在这里写出了一些代码函数.
#include 分配连续的2的order次方的物理地址
struct page * alloc_pages(gfp_t gfp_mask, unsigned int order);
// 成功返回 物理页开始首地址; 失败返回 NULL
将物理地址转为逻辑地址. 使用alloc_page : 指向当前指定物理页的逻辑地址
struct page * alloc_page(struct page * page);
// 将页的内容清0, 也是为了让以前的数据都清空
unsigned long get_zeroed_page(unsigned int gfp_mask);
同样分配, 返回逻辑首地址, 跟alloc_pages 一样, 只是返回逻辑地址的首地址. 不过这个函数执行后要进行错误检查
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order);
// 成功, 返回逻辑地址首地址; 失败, 返回NULL
地址分配
// 字节的分配, falgs : GFP_KERNEL, 进程分配使用; GFP_ATOMIC : 中断分配使使用
struct dog * kmalloc(sizeof(struct dog), gfp_t falgs);
// 分配来连续的线性地址
void * vmalloc(unsigned long size);
几个函数的区别
malloc() 分配的页只能保证是在虚拟地址空间是连续的
kmallc() 能确保在物理地址上是连续的
vmalloc() 确保在虚拟地址空间是连续的,但是每次分配 vmalloc 都是一页一页与物理地址连接起来, 容易发生TLB抖动
slab层
slab分配器是为了空闲链表的快速分配和释放, 实现高速缓存的功能. 空闲链表是指可供使用, 已经分配好的数据块.
高速缓存被划分成slab, 每个高缓又可以由多个slab组成.
slab的基本原则
- 数据结构的频繁分配和释放
- 回收大量分配之后释放的内存碎片
- 对存放的对象进行着色, 以防止多个对象映射到相同的高速缓存行.
一个例子 :
文件 inode 索引节点, 需要经常的释放和构建, 所以内核采用将它交给slab高缓. 而 struct indoe 由inode_cachep高速缓存分配的.

slab层把不同的对象划分到缓存组中, 所以每个高缓组都存放着不同数据类型的对象, 每种对象对应一个高速缓存.
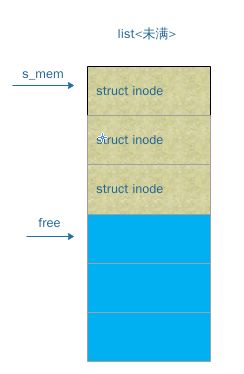
slab结构
struct slab
{
// slab 的状态 : 满, 部分满, 空
struct list_head list;
// slab 的偏移量
unsigned long colouroff;
// slab 中的第一个对象
void * s_mem;
// slab 以分配的数量
unsigned int inuse;
// 第一个空闲对象
kmem_bufctl_t free;
};
高速缓存创建
高速缓存的创建函数
// name : 缓存的名称
// size : 高速缓存中每个数据的大小
// align : slab内第一个对象的偏移
// flags : 高速缓存的行为
// ctor : 构造函数, linux中为 NULL
struct kmem_cache * kmem_cache_create(const char *name, size_t size, size_t align, unsigned long flags, void (*ctor)(void *));
struct task是由 kmem_cache_create() 函数创建的一个名为task的缓存, 里面存放的也是struct task 的结构
task_struct_cachep = kmem_cache_create("struct task",
sizeof(struct task_struct),
ARCH_MIN_TASKALIGN,
SLAB_PANIC | SLAB_NOTRACK,
NULL);
struct task 缓存不允许创建失败, 也是不可覆盖和删除的缓存.
小结
字节 : kmalloc(分配连续的物理地址), vmalloc(分配连续的虚拟地址空间, 可能会发生抖动)
页 : __get_free_pages(要做错误检查), alloc_page