190604 面试总结
一、python 线程机制
多线程对共同数据操作,必须上锁保持同步。同步阻塞。
使用场景:同时监听多个任务。Python多线程有没有用,有,你去爬图片站的时候,用单进程单线程这种方式,进程很容易阻塞在获取数据socket函数上,多线程可以缓解这种情况。比方说多线程网络传输,多线程往不同的目录写文件,等等
多线程其实是单线程,全局解释器锁(GIL)global interpreter lock,Python代码的执行由Python虚拟机(解释器)来控制,同时只有一个线程在执行,在多线程环境中,Python虚拟机按照以下方式执行。 1.设置GIL。 2.切换到一个线程去执行。 3.运行。 4.把线程设置为睡眠状态。 5.解锁GIL。 6.再次重复以上步骤。比方我有一个4核的CPU,那么这样一来,在单位时间内每个核只能跑一个线程,然后时间片轮转切换。但是Python不一样,它不管你有几个核,单位时间多个核只能跑一个线程,然后时间片轮转。执行一段时间后让出,多线程在Python中只能交替执,100核只能用到1个核例如,下面的代码4核cpu只会用一个核,大概占用25%的cpu使用率,如果改成多进程,cpu会占满。
计算密集型:消耗cpu,任务越多,花在任务切换的时间就越多,CPU执行任务的效率就越低,所以,要最高效地利用CPU,计算密集型任务同时进行的数量应当等于CPU的核心数。
IO密集型可以使用多线程,io是接口,可以开启多线程让cpu同时等待。CPU消耗很少,任务的大部分时间都在等待IO操作完成。(这里多线程并不是多个线程完全同步同时进行,而是按一定指令量或者存在阻塞时不断交替切换线程之不断执行的)
IO密集型任务执行期间,99%的时间都花在IO上,花在CPU上的时间很少,因此,用运行速度极快的C语言替换用Python这样运行速度极低的脚本语言,完全无法提升运行效率。对于IO密集型任务,最合适的语言就是开发效率最高(代码量最少)的语言,脚本语言是首选,C语言最差。
结论:
1. 如果任务是IO密集型的,可以用多线程(这里多线程并不是多个线程完全同步同时进行,而是按一定指令量或者存在阻塞时不断交替切换线程之不断执行的)----因为Cpython解释存在全局加锁(GIL),只允许在同一时刻,只能有一个线程进入解释器---也就是同一时刻只能使用一个CPU----------目前有一个不完美的解决办法就是创建多个进程。
2。是计算密集型的,就不合适用多线程,解决办法有:1.不完美方法---创建多个进程;2.协程+进程;3最完成解决办法是用C语言解决(间接调用C语言实现这一部分代码)。
二、线程、进程、协程的理解,什么时候用多线程
进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。每一个进程都有它自己的地址空间,一般情况下,包括文本区域(text region)、数据区域(data region)和堆栈(stack region)。
线程,有时被称为轻量级进程(Lightweight Process,LWP),是程序执行流的最小单元。一个标准的线程由线程ID,当前指令指针(PC),寄存器集合和堆栈组 成。
协程,一个程序可以包含多个协程,可以对比与一个进程包含多个线程,因而下面我们来比较协程和线程。我们知道多个线程相对独立,有自己的上下文,切换受系统控制;而协程也相对独立,有自己的上下文,但是其切换由自己控制,由当前协程切换到其他协程由当前协程来控制。
线程和协程优缺点:线程上下文切换开销大,协程开销成本极低。
线程是靠系统控制切换,协程是自己控制。
三、python堆栈、队列
1.堆栈空间分配
①栈(操作系统):由操作系统自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
②堆(操作系统): 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收,分配方式倒是类似于链表。
2.堆栈缓存方式
①栈使用的是一级缓存, 他们通常都是被调用时处于存储空间中,调用完毕立即释放。
②堆则是存放在二级缓存中,生命周期由虚拟机的垃圾回收算法来决定(并不是一旦成为孤儿对象就能被回收)。所以调用这些对象的速度要相对来得低一些。
3.堆栈数据结构区别
①堆(数据结构):堆可以被看成是一棵树,如:堆排序。
②栈(数据结构):一种先进后出的数据结构。
四、队列:
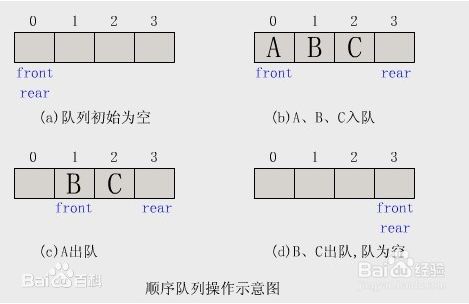
①队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头。
②队列中没有元素时,称为空队列。
③建立顺序队列结构必须为其静态分配或动态申请一片连续的存储空间,并设置两个指针进行管理。一个是队头指针front,它指向队头元素;另一个是队尾指针rear,它指向下一个入队元素的存储位置。
堆、栈、队列之间的区别是?
①堆是在程序运行时,而不是在程序编译时,申请某个大小的内存空间。即动态分配内存,对其访问和对一般内存的访问没有区别。
②栈就是一个桶,后放进去的先拿出来,它下面本来有的东西要等它出来之后才能出来。(后进先出)
③队列只能在队头做删除操作,在队尾做插入操作.而栈只能在栈顶做插入和删除操作。(先进先出)
④队列采用的FIFO(first in first out),新元素(等待进入队列的元素)总是被插入到链表的尾部,而读取的时候总是从链表的头部开始读取。每次读取一个元素,释放一个元素。所谓的动态创建,动态释放。因而也不存在溢出等问题。由于链表由结构体间接而成,遍历也方便。(先进先出)
五、django优化、数据库优化
1.一次性取出你所需要的数据
单一动作,需要多次连接数据库里的时候,最好一次性取出所有需要的数据,减少连接数据库的次数。此类需求推荐使用QuerySet.select_related()和prefetch_related()
相反,别取出你不需要的东西,模板templateds里往往只需要实体的某几个字段而不是全部,这时使用queryset.values()和values_list()对你有用,他们只取出你需要的字段,返回字典dict和列表list类型的东西,在模板里面够用就可以,这可以减少内存损耗,提高性能。
使用queryset.count()代替len(queryset),虽然这两个处理出来的结果是一样的,但是前者性能优秀很多。同理判断记录存在的时候,queryset.exists()比if queryset实在强的太多了。
当然一样的结果,当缓存里面已经存在的时候,就别再滥用count(),exitst(),all()函数了。
2.减少数据库连接的次数
使用queryset.update()和delete(),这两个函数是可以批量处理多条记录的,使他们事半功倍;如果可以,被一条条数据去update delete处理,对于一次性取出来的关联记录,获取外键的时候,直接取关联表的属性,而不是取关联属性,如entry.blog.id优于enrty.blog_id
等等。。
六、数据结构和算法
七、sort()、sorted()
list.sort() #对列表本身进行排序
result = sorted(list) #对列表进行排序
dict = sorted(dict) #对字典key排序
八、python内存分配机制、垃圾回收机制
九、django什么时候用Q、F
F:
作用:操作数据表中的某列值,F()允许Django在未实际链接数据的情况下具有对数据库字段的值的引用,不用获取对象放在内存中再对字段进行操作,直接执行原生产sql语句操作。
obj = Order.objects.get(orderid='12')
obj.amount = F('amount') + 1
obj.save()#生成的sql语句为:
UPDATE `core_order` SET ..., `amount` = `core_order`.`amount` + 1 WHERE `core_order`.`orderid` = '12' # 和预计的一样Q:
作用:对对象进行复杂查询,并支持&(and),|(or),~(not)操作符。
如果查询使用中带有关键字查询,Q对象一定要放在前面
Asset.objects.get(
Q(pub_date=date(2005, 5, 2)) | Q(pub_date=date(2005, 5, 6)),
question__startswith='Who')
十、lamdba函数 for
1、f = lamdba x,y,z:x+y+z #前面是参数,后面是结果
print(f(1,2,3))
2、list(filter(lambda x:x>30, [34, 23, 54, 23, 12]))3、list(map(lamdba x:x*2,[34, 23, 54, 23,12]))
4、list(map(lambda x, y : [x, y], [1, 3, 5, 7, 9], [2, 4, 6, 8, 10]))
5、list(filter(lambda n : not(n%3), range(1, 100)))
推导式:[ i for i in range(1, 100) if not(i%3)]
十一、head、patch
head与get类似,获取资源的部分信息。
patch与put类似,patch是部分更新。
十二、udp\tcp
udp和tcp的区别:
前者面向连接,后者不需要连接。
前者可靠,后者不可靠。
前者传输效率低,后者传输效率高,高速实时。
前者一对一,后者多对一。
十三、链表和数组的区别(理论即可)
链表是一种上一个元素的引用指向下一个元素的存储结构,链表通过指针来连接元素与元素;
链表是线性表的一种,所谓的线性表包含顺序线性表和链表,顺序线性表是用数组实现的,在内存中有顺序排列,通过改变数组大小实现。而链表不是用顺序实现的,用指针实现,在内存中不连续。意思就是说,链表就是将一系列不连续的内存联系起来,将那种碎片内存进行合理的利用,解决空间的问题。
所以,链表允许插入和删除表上任意位置上的节点,但是不允许随机存取。链表有很多种不同的类型:单向链表、双向链表及循环链表。
单项链表:

单向链表包含两个域,一个是信息域,一个是指针域。也就是单向链表的节点被分成两部分,一部分是保存或显示关于节点的信息,第二部分存储下一个节点的地址,而最后一个节点则指向一个空值。
双向链表:

从上图可以很清晰的看出,每个节点有2个链接,一个是指向前一个节点(当此链接为第一个链接时,指向的是空值或空列表),另一个则指向后一个节点(当此链接为最后一个链接时,指向的是空值或空列表)。意思就是说双向链表有2个指针,一个是指向前一个节点的指针,另一个则指向后一个节点的指针。
循环链表:

循环链表就是首节点和末节点被连接在一起。循环链表中第一个节点之前就是最后一个节点,反之亦然。
区别:
不同:链表是链式的存储结构;数组是顺序的存储结构。
链表通过指针来连接元素与元素,数组则是把所有元素按次序依次存储。
链表的插入删除元素相对数组较为简单,不需要移动元素,且较为容易实现长度扩充,但是寻找某个元素较为困难;
数组寻找某个元素较为简单,但插入与删除比较复杂,由于最大长度需要再编程一开始时指定,故当达到最大长度时,扩充长度不如链表方便。
相同:两种结构均可实现数据的顺序存储,构造出来的模型呈线性结构。
十四、__repr__ __str__区别
十五、python强类型语言
十七、django大型开源项目
十八、limit
十九、下标为什么不取到最后一位