JavaMVC框架面试总结(全面,实时更新)
谈一下SpringMVC的工作流程

1.用户发送请求至前端控制器DispatcherServlet
2.DispatcherServlet收到请求调用HandlerMapping处理器映射器。
3.处理器映射器找到具体的处理器,生成处理器对象及处理器拦截器(如果有则生成)一并返回给DispatcherServlet。
4.DispatcherServlet调用HandlerAdapter处理器适配器
5.HandlerAdapter经过适配调用具体的处理器(Controller,也叫后端控制器)。
6.Controller执行完成返回ModelAndView
7.HandlerAdapter将controller执行结果ModelAndView返回给DispatcherServlet
8.DispatcherServlet将ModelAndView传给ViewReslover视图解析器
9.ViewReslover解析后返回具体View
10.DispatcherServlet根据View进行渲染视图(即将模型数据填充至视图中)。
DispatcherServlet响应用户
简述SpringMVC中如何返回JSON数据
1.在项目中加入json转换的依赖,例如jackson,fastjson,gson等
2.在请求处理方法中将返回值改为具体返回的数据的类型, 例如数据的集合类List
3.在请求处理方法上使用@ResponseBody注解
谈谈你对Spring的理解
Spring 是一个开源框架,为简化企业级应用开发而生。Spring 可以是使简单的JavaBean 实现以前只有EJB 才能实现的功能。Spring 是一个 IOC 和 AOP 容器框架。
Spring 容器的主要核心是:
1.控制反转(IOC),传统的 java 开发模式中,当需要一个对象时,我们会自己使用 new 或者 getInstance 等直接或者间接调用构造方法创建一个对象。而在 spring 开发模式中,spring 容器使用了工厂模式为我们创建了所需要的对象,不需要我们自己创建了,直接调用spring 提供的对象就可以了,这是控制反转的思想。
2.依赖注入(DI),spring 使用 javaBean 对象的 set 方法或者带参数的构造方法为我们在创建所需对象时将其属性自动设置所需要的值的过程,就是依赖注入的思想。
3.面向切面编程(AOP),在面向对象编程(oop)思想中,我们将事物纵向抽成一个个的对象。而在面向切面编程中,我们将一个个的对象某些类似的方面横向抽成一个切面,对这个切面进行一些如权限控制、事物管理,记录日志等公用操作处理的过程就是面向切面编程的思想。AOP 底层是动态代理,如果是接口采用 JDK 动态代理,如果是类采用CGLIB 方式实现动态代理。
aop两种动态代理方式
1.JDK动态代理(实现式动态代理):JDK动态代理主要针对接口进行代理,如果目标对象实现了接口,那么可以直接通过接口进行代理;如果目标对象没有实现接口,那么可以通过使用CGLIB库来对目标对象进行代理。JDK动态代理的主要优点是简单易用,但只适用于实现了接口的对象。
2.CGLIB动态代理(继承式动态代理):CGLIB动态代理是一种基于继承的动态代理方式,通过在目标对象的子类中添加额外的逻辑来实现代理。CGLIB动态代理的优点是可以对任何对象进行代理,包括没有实现接口的对象。但需要注意的是,由于是基于继承的代理方式,可能会对目标对象的原有行为造成影响。
Spring循环依赖问题
什么是循环依赖?
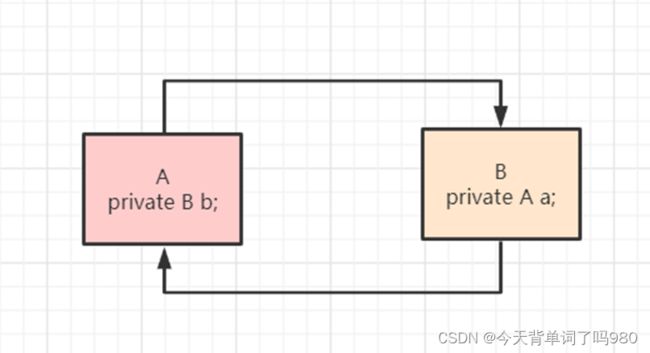
官方解释
https://docs.spring.io/spring-framework/docs/current/reference/html/core.html#beans-dependency-resolution
三级缓存
| 名称 |
对象名 |
含义 |
| 一级 缓存 |
singletonObjects |
存放已经经历了完整生命周期的Bean对象 |
| 二级 缓存 |
earlySingletonObjects |
存放早期暴露出来的Bean对象,Bean的生命周期未结束(属性还未填充完) |
| 三级 缓存 |
singletonFactories |
存放可以生成Bean的工厂 |
四个关键方法

package org.springframework.beans.factory.support;
public class DefaultSingletonBeanRegistry extends SimpleAliasRegistry implements SingletonBeanRegistry {
/**
单例对象的缓存:bean名称—bean实例,即:所谓的单例池。
表示已经经历了完整生命周期的Bean对象
第一级缓存
*/
private final Map singletonObjects = new ConcurrentHashMap<>(256);
/**
早期的单例对象的高速缓存: bean名称—bean实例。
表示 Bean的生命周期还没走完(Bean的属性还未填充)就把这个 Bean存入该缓存中也就是实例化但未初始化的 bean放入该缓存里
第二级缓存
*/
private final Map earlySingletonObjects = new HashMap<>(16);
/**
单例工厂的高速缓存:bean名称—ObjectFactory
表示存放生成 bean的工厂
第三级缓存
*/
private final Map> singletonFactories = new HashMap<>(16);
}
执行过程
1,A创建过程中需要B,于是A将自己放到三级缓里面,去实例化B
2,B实例化的时候发现需要A,于是B先查一级缓存,没有,再查二级缓存,还是没有,再查三级缓存,找到了A然后把三级缓存里面的这个A放到二级缓存里面,并删除三级缓存里面的A
3,B顺利初始化完毕,将自己放到一级缓存里面(此时B里面的A依然是创建中状态),然后回来接着创建A,此时B已经创建结束,直接从一级缓存里面拿到B,然后完成创建,并将A自己放到一级缓存里面。
总结
1,Spring创建 bean主要分为两个步骤,创建原始bean对象,接着去填充对象属性和初始化。
2,每次创建 bean之前,我们都会从缓存中查下有没有该bean,因为是单例,只能有一个。
3,当创建 A的原始对象后,并把它放到三级缓存中,接下来就该填充对象属性了,这时候发现依赖了B,接着就又去创建B,同样的流程,创建完B填充属性时又发现它依赖了A又是同样的流程,不同的是:这时候可以在三级缓存中查到刚放进去的原始对象A。
所以不需要继续创建,用它注入 B,完成 B的创建既然 B创建好了,所以 A就可以完成填充属性的步骤了,接着执行剩下的逻辑,闭环完成。
Spring解决循环依赖依靠的是Bean的"中间态"这个概念,而这个中间态指的是已经实例化但还没初始化的状态—>半成品。实例化的过程又是通过构造器创建的,如果A还没创建好出来怎么可能提前曝光,所以构造器的循环依赖无法解决。
衍生问题
1:为什么构造器注入属性无法解决循环依赖问题?
由于spring中的bean的创建过程为先实例化 再初始化(在进行对象实例化的过程中不必赋值)将实例化好的对象暴露出去,供其他对象调用,然而使用构造器注入,必须要使用构造器完成对象的初始化的操作,就会陷入死循环的状态。
2:一级缓存能不能解决循环依赖问题? 不能
在三个级别的缓存中存储的对象是有区别的 一级缓存为完全实例化且初始化的对象 二级缓存实例化但未初始化对象 如果只有一级缓存,如果是并发操作下,就有可能取到实例化但未初始化的对象,就会出现问题。
3:二级缓存能不能解决循环依赖问题?
理论上二级缓存可以解决循环依赖问题,但是需要注意,为什么需要在三级缓存中存储匿名内部类(ObjectFactory),原因在于 需要创建代理对象 eg:现有A类,需要生成代理对象 A是否需要进行实例化(需要) 在三级缓存中存放的是生成具体对象的一个匿名内部类,该类可能是代理类也可能是普通的对象,而使用三级缓存可以保证无论是否需要是代理对象,都可以保证使用的是同一个对象,而不会出现,一会儿使用普通bean 一会儿使用代理类。
Spring bean 的生命周期、注入方式和作用域
生命周期
当加入了Bean的后置处理器后,IOC容器中bean的生命周期分为七个阶段:
1.调用构造器 或者是通过工厂的方式创建Bean对象
2.给bean对象的属性注入值
3.执行Bean后置处理器中的 postProcessBeforeInitialization
4.调用初始化方法,进行初始化, 初始化方法是通过init-method来指定的.x
5.执行Bean的后置处理器中 postProcessAfterInitialization
6.使用
7.IOC容器关闭时, 销毁Bean对象
注入方式
1.通过 setter 方法注入
2.通过构造方法注入
作用域
1.Singleton
在spring IoC容器仅存在一个Bean实例,Bean以单例方式存在,bean作用域范围的默认值。
2.Prototype
每次从容器中调用Bean时,都返回一个新的实例,即每次调用getBean()时,相当于执行newXxxBean()。
3.Request
每次HTTP请求都会创建一个新的Bean,该作用域仅适用于web的Spring WebApplicationContext环境。
4.Session
同一个HTTP Session共享一个Bean,不同Session使用不同的Bean。该作用域仅适用于web的Spring WebApplicationContext环境
5.application
限定一个Bean的作用域为ServletContext的生命周期。该作用域仅适用于web的Spring WebApplicationContext环境。
Spring有事务管理吗?
声明式事务管理的定义:用在 Spring 配置文件中声明式的处理事务来代替代码式的处理事务。这样的好处是,事务管理不侵入开发的组件,具体来说,业务逻辑对象就不会意识到正在事务管理之中,事实上也应该如此,因为事务管理是属于系统层面的服务,而不是业务逻辑的一部分,如果想要改变事务管理策划的话,也只需要在定义文件中重新配置即可,这样维护起来极其方便。
1.基于 TransactionInterceptor 的声明式事务管理:两个次要的属性: transactionManager,用来指定一个事务治理器, 并将具体事务相关的操作请托给它; 其他一个是 Properties 类型的transactionAttributes 属性,该属性的每一个键值对中,键指定的是方法名,方法名可以行使通配符, 而值就是表现呼应方法的所运用的事务属性。
基于 @Transactional 的声明式事务管理:Spring 2.x 还引入了基于 Annotation 的体式格式,具体次要触及@Transactional 标注。@Transactional 可以浸染于接口、接口方法、类和类方法上。算作用于类上时,该类的一切public 方法将都具有该类型的事务属性。
2.编程式事物管理的定义:在代码中显式挪用 beginTransaction()、commit()、rollback()等事务治理相关的方法, 这就是编程式事务管理。Spring 对事物的编程式管理有基于底层 API 的编程式管理和基于 TransactionTemplate 的编程式事务管理两种方式。
spring中事务失效的具体场景?
在Spring框架中,事务失效的具体场景包括以下几种:
1.事务方法访问修饰符非public:Spring要求被代理的方法必须是public的,如果事务方法被定义为非public(如private、protected或default),则事务功能可能无法正常工作。
2.@Transactional注解的方法抛出的异常不是Spring的事务支持的异常:如果事务方法抛出的异常不是Spring事务支持的异常,事务将不会回滚。因此,需要确保在事务方法中抛出的异常是Spring事务支持的异常。
3.数据表本身不支持事务:如果应用程序操作的数据表本身不支持事务,则在该表上执行的事务操作可能无法正常工作。
4.@Transactional注解所在的类没有被Spring管理:如果使用@Transactional注解的类没有被Spring管理,事务将不会正常工作。需要确保使用@Transactional注解的类是Spring管理的Bean。
5.catch掉异常之后没有再次抛出异常:如果在事务方法中捕获异常后没有再次抛出异常,事务将不会回滚。因此,需要确保在事务方法中正确处理异常并再次抛出。
6.方法自身(this)调用问题:如果在事务方法中调用了自身(this),并且调用的方式不正确,可能导致事务失效。需要确保在事务方法中正确调用自身。
7.数据源没有配置事务管理器:如果应用程序的数据源没有配置事务管理器,事务将无法正常工作。需要确保在数据源上配置了正确的事务管理器。
8.传播类型不支持事务:Spring事务的传播类型决定了事务的行为。如果传播类型不支持所需的事务行为,可能会导致事务失效。需要确保选择正确的传播类型来支持所需的事务行为。
9.多线程调用:在多线程环境中调用事务方法时,如果没有正确处理线程安全问题,可能会导致事务失效。需要确保在多线程环境中正确处理线程安全问题。
Spring中事务失效需要根据具体情况进行分析和排查。在开发过程中,需要遵循Spring的事务管理规范,并确保正确配置和使用事务管理器,以避免出现事务失效的问题。
MyBatis中 #{}和${}的区别是什么
#{}是预编译处理,${}是字符串替换;
Mybatis在处理#{}时,会将sql中的#{}替换为?号,调用PreparedStatement的set方法来赋值;
Mybatis在处理${}时,就是把${}替换成变量的值;
使用#{}可以有效的防止SQL注入,提高系统安全性。
MyBatis如何获取自动生成的(主)键值
在
insert into names (name) values (#{name})
Mybatis 中一级缓存与二级缓存
1.MyBatis的缓存分为一级缓存和 二级缓存。
一级缓存是SqlSession级别的缓存,默认开启。
二级缓存是NameSpace级别(Mapper)的缓存,多个SqlSession可以共享,使用时需要进行配置开启。
2.缓存的查找顺序:二级缓存 => 一级缓存 => 数据库
你在工作中用过那些Mybatis的动态SQL
动态SQL是MyBatis的强大特性之一 基于功能强大的OGNL表达式。
动态SQL主要是来解决查询条件不确定的情况,在程序运行期间,根据提交的条件动态的完成查询
常用的标签:
1.
2.
3.
4.
5.
Mybatis 如何完成MySQL的批量操作
MyBatis完成MySQL的批量操作主要是通过
insert into tbl_employee(last_name,email,gender,d_id) values
(#{curr_emp.lastName},#{curr_emp.email},#{curr_emp.gender},#{curr_emp.dept.id})
mybatis和mybatisplus有什么区别
MyBatis和MyBatis Plus都是Java语言的持久层框架,它们有一些明显的区别:
1.功能特性:MyBatis是一个基于XML配置文件和SQL语句的ORM框架,提供了数据持久化的基本功能,如SQL映射、缓存管理等。而MyBatis Plus在MyBatis的基础上进行了扩展,提供了更加丰富的功能特性,如分页插件、代码生成器、注解支持等。
2.编码方式:MyBatis在进行数据持久化时需要编写大量的XML配置文件和SQL语句,需要熟悉XML和SQL的编写规范。而MyBatis Plus使用注解和API的方式进行数据持久化,使用更加便捷和简洁。
3.性能和效率:MyBatis Plus在功能扩展的同时也对性能进行了优化,提供了高效的SQL语句构建和执行功能,并支持动态SQL语句生成,从而提高了应用的性能和效率。
4.依赖性:MyBatis Plus的依赖较少,仅仅依赖于MyBatis以及MyBatis-Spring。
5.安全性:MyBatis Plus内置了SQL注入剥离器,有效预防了SQL注入攻击。
6.CRUD操作:MyBatis Plus内置了通用Mapper和通用Service,只需要少量配置即可实现单表的大部分CRUD操作。
7.主键策略:MyBatis Plus支持多达4种主键策略(包括分布式唯一ID生成器),可自由配置,完美解决主键问题。
8.分页插件:MyBatis Plus内置了分页插件,基于MyBatis的物理分页,开发者无需关心具体操作,配置好插件之后,写分页等同于普通List查询。