第6章 对象群体的组织
Java集合框架介绍
一、Java集合框架
1.对外接口:表示集合的抽象数据类型
2.接口的实现类:实现集合接口的Java类,是可重用的数据结构
3.对集合运算的算法:执行运算的方法,例:在集合上进行查找和排序
二、集合框架接口
1.声明了对各种集合类型执行的一般操作
2.基本结构如图:
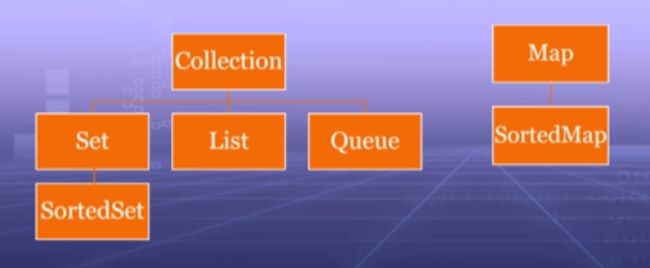
主要接口及常用的实现类
一、Collection接口
1.声明了一组操作成批对象的抽象方法
2.实现它的类:AbstractCollection类,是一个抽象类,如果要实现相关功能要使用它的子类
3.Collection接口及其子接口的实现类:
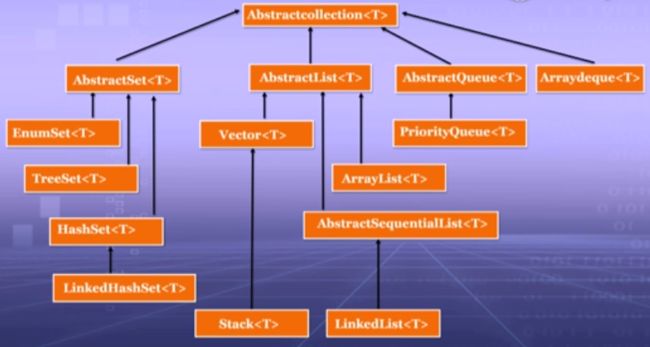
4.Collection接口常用方法:
(1)查询方法:
int size():返回集合对象中包含的元素个数
boolean isEmpty():判断集合对象中是否还包含元素,如果没有任何元素,返回true
boolean contain(Objectobj):判断对象是否在集合中
booleancontainsAll(Collection c):判断方法的接收者对象是否包含集合中所有的元素
(2)修改方法:
boolean add(Object obj):向集合中增加对象
booleanaddAll(Collection c):将参数集合中的所有元素增加到接收者集合中
boolean remove:从集合中删除对象
booleanremoveAll(Collection c):将参数集合中所有的元素从接收者集合中删除
booleanretainAll(Collection c):在接收者集合中保留参数集合中的所有元素,其他元素都删除
二、Set接口
1.对equals和hashCode操作有了更强的约定,如果两个Set对象包含同样的元素,二者便是相等的,禁止出现重复元素
2.实现Set接口的类:哈希集合(HashSet)及树集合(TreeSet)。其它:AbstractSet、ConcurrentSkipListSet、CopyOnWriteArraySet、EnumSet、JobStateReasons、LinkedHashSet
三、SortedSet接口
1.一种特殊的Set
2.其中元素是升序排序的,增加了与次序相关的操作
3.通常用于存放词汇表这样的内容
4.实现它的类:ConcurrentSkipListSet、TreeSet
四、List接口
1.可包含重复元素
2.元素是有顺序的,每个元素都有一个index值(从0开始),表明元素在列表中位置
3.实现List接口的类:Vector、ArrayList:一种类似数组的形式进行储存,因此它的随机访问速度极快、LinkedList:内部实现是链表,适合于在链表中间需要频繁进行插入和删除操作、Stack。其它:AbstractList、AbstractSequentialList、AttributeList、CopyOnWriteArrayList、RoleList、RoleUnresolvedList
五、Queue接口
1.除了Collection的基本操作,队列接口另外还有插入、移除和查看操作
2.FIFO:先进先出
3.实现Queue接口的类:LinkedList(同时也实现List接口)、PriorityQueue:按元素值排序的队列。其它:AbstractQueue、ArrayBlockingQueue、ArrayDeque、ConcurrentLinkedQueue、DelayQueue、LinkedBlockingDeque、LinkedBlockingQueue、PriorityBlockingQueue、SynchronousQueue
六、Map接口
1.用于维护键/值对(key/value pairs)
2.不能有重复的关键字,每个关键字最多能够映射到一个值
3.声明时可以带有两个参数,即Map
4.实现Map接口的类:HashMap、TreeMap。其它:AbstractMap、Attributes、AuthProvider、ConcurrentHashMap、ConcurrentSkipListMap、EnumMap、Hashtable、IdentityHashMap、LinkedHashMap、PrinterStateReasons、Properties、Provider、RenderingHints、SimpleBindings、TabularDataSupport、UIDefaults、WeakHashMap
5.Map接口及其子接口和实现类:

七、SortedMap接口
1.Map的子接口
2.一种特殊的Map,其中的关键字是升序排序的
3.通常用于词典和电话目录等
4.声明时可以带有两个参数,即SortedMap
5.实现SortedMap接口的类:TreeMap、ConcurrentSkipListMap(支持并发)
常用算法
一、对集合运算的算法
1.大多数算法都是用于操作List对象
2.有两个(min和max)可用于任意集合对象
二、排序算法
1.List元素按照某种次序关系升序排序
2.有两种形式:
(1)简单形式只是将元素按照自然次序排序,或者集合实现了Comparable接口
(2)第二种形式需要一个附加的Comparator对象作为参数,用于规定比较规则,可用于实现反序或特殊次序排序
3.算法性能:
(1)快:时间复杂度nlog(n)
(2)稳定
三、洗牌算法shuffle
1.以随机方式重排List元素,任何次序出现的机率都是相等的
2.在实现偶然性游戏的时候,这个算法很有用,例如洗牌
四、常规数据处理算法
1.reverse:将一个List中的元素反向排列
2.fill:用指定的值覆写List中的每一个元素,这个操作在重新初始化List时有用
3.copy:接受两个参数,目标List和源List,将源中的元素复制到目标,覆写其中的内容。目标List必须至少与源一样长,如果更长,则多余的部分内容不受影响
五、二分查找算法binarySearch
1.使用二分法在一个有序的List中查找指定元素
2.有两种形式:
(1)第一种形式假定List是按照自然顺序升序排序的
(2)第二种形式需要增加一个Comparator对象,表示比较规则,并假定List是按照这种规则排序的
3.将binary Search算法作用在集合上时,会首先检查集合是否实现了RandomAccess接口。是:二分法查找,不是:线性查找
六、寻找最值
1.用于任何集合对象
2.min和max算法返回指定集合中的最小值和最大值
3.这两个算法分别都有两种形式:
(1)简单形式按照元素的自然顺序返回最值
(2)另一种形式需要附加一个Comparator对象作为参数,并按照Comparator对象指定的比较规则返回最值
数组实用方法(Arrays类)
一、存在位置
在java.util包中
二、常用方法
1.fill(type[] a,typeval):给数组填充,就是简单地把一个数组全部或者某段数据填成一个特殊的值
2.equals(type[]a,type[] b):实现两个数组的比较,相等时返回true
3.sort(type[] a):对数组排序
4.binarySearch():对数组元素进行二分查找
5.asList(Type a[]):实现数组到ArrayList的转换
6.toString(基本类型或object数组引用):实现数组到string的转换
同步、异步:
一、概念
多线程并发时,多个线程同时请求同一个资源,必然导致此资源的数据不安全,A线程修改了B线程的处理的数据,而B线程又修改了A线程处理的数理。显然这是由于全局资源造成的,有时为了解决此问题,优先考虑使用局部变量,退而求其次使用同步代码块,出于这样的安全考虑就必须牺牲系统处理性能,加在多线程并发时资源争夺最激烈的地方,这就实现了线程的同步机制
二、同步
A线程要请求某个资源,但是此资源正在被B线程使用中,因为同步机制存在,A线程请求不到,怎么办,A线程只能等待下去
二、异步
A线程要请求某个资源,但是此资源正在被B线程使用中,因为没有同步机制存在,A线程仍然请求的到,A线程无需等待
三、特点
显然,同步最最安全,最保险的。而异步不安全,容易导致死锁,这样一个线程死掉就会导致整个进程崩溃,但没有同步机制的存在,性能会有所提升
基于动态数组的类型(Vector类、ArrayList类)
一、Vector、ArrayList共同点
1.都实现了Collection接口
2.能够存储相同类型(或具有相同父类或相同接口)的对象
3.不能存储基本数据类型,要将基本数据类型包裹在包裹类(Integer)中
4.容量能够根据空间需要自动扩充
5.增加元素方法的效率较高,除非空间已满的时候,效率会下降(在这种情况下,在增加之前需要先扩充容量,从而消耗了运行时间)
二、二者差别
1.Vector是集合框架的遗留类,不鼓励使用,线程同步、安全
2.ArrayList是非线程同步的,效率较高
3.Java提供线程安全的集合:Java.util.concurrent包,有:映像、有序集、队列。
使用同步包装器也可以将任何集合类变成线程安全的,格式如下:
List
三、ArrayList
1.构造方法
(1)ArrayList():构造一个空表,默认容量为10
(2)ArrayList(Collection c):将参数集合中的所有元素为ArrayList初始化。或该参数集合元素类型的子类也可以初始化声明为该参数集合元素类型的ArrayList。例:
如我有MySubClass是MyClass的子类。
Collection
Collection
ArrayList
也可以:ArrayList
(3)ArrayList(int initialCapacity):构造一个空表,容量为initialCapacity
2.其它方法
(1)boolean add(E e):增加一个元素到队尾
(2)void add(intindex,E e):把下标为index的位置插入元素e
(3)boolean addAll(Collectionc)
(4)void clear()
(5)Object clone()
(6)boolean contains(Object obj)
(7)void ensureCapacity(int minCapacity)
(8)void forEach(Consumeraction)
(9)E get(int index):得到第几个元素的值
(10)int indexOf(Object o):此方法返回指定元素的第一个匹配项的索引在此列表中,或者如果此列表中不包含该元素返回-1
(11)boolean isEmpty()
(12)Iterator
(13)booleanremove(E e):删除队尾的一个元素
(14)E remove(intindex):删除下标为index的元素
(15)void set(intindex,E e):把下标为index的元素更新为e
遍历Collection
一、三种遍历方式
1.通过Enumeration及Iterator接口遍历集合
2.增加for循环遍历集合
3.通过聚集操作遍历集合
二、通过Enumberation及Iterator接口遍历
1.Enumeration/Iterator
(1)能够从集合类对象中提前每一个元素,并提供了用于遍历元素的方法
(2)Java中许多方法(如elements())都返回Enumeration类型的对象,而不是返回集合类对象
(3)Enumeration接口不能用于ArrayList对象,而Iterator接口既可以用于ArrayList对象,也可以用于Vector对象
2.Iterator接口
(1)是对Enumeration接口的改进,因此在遍历集合元素时,优选Iterator接口
(2)具有从正在遍历的集合中去除对象的能力
(3)具有以下三个实例方法:
hasNext():判断是否还有下个元素
next():取得下一个元素
remove():去除一个元素。注意是从集合中去除最后调用next()返回的元素,而不是从Iterator类中去除
3.Iterator实例
import java.util.Vector;
import java.util.Iterator;
public class IteratorTester{
publicstatic void main(String args[]){
String[]num={“one”,”two”,”three”,”four”,”five”,”six”,”seven”,”eight”,”nine”,”ten”};
Vector
System.out.println(“BeforeVector:”+aVector);
Iterator
while(nums.hasNext())
{
StringaString =(String)num.next();
System.out.println(aString);
if(aString.length()>4)
nums.remove();
}
System.out.println(“After Vector:”+aVector);
}
}

三、用增强for循环遍历
1.格式:for(Type a:集合对象)
2.实例:
import java.util.Vector;
import java.util.Enumeration;
public class ForTester{
publicstatic void main(String args[]){
Enumeration
Vector
dayNames.add(“Sunday”);
dayNames.add(“Monday”);
dayNames.add(“Tuesday”);
dayNames.add(“Wednesday”);
dayNames.add(“Thursday”);
dayNames.add(“Friday”);
dayNames.add(“Saturday”);
days=dayNames.elements();
for(String day: dayNames)
System.out.println(day);
}
}
Map接口及其实现类
一、Map接口意义
1.用于存储“关键字”key和“值”value的元素对,其中每个关键字映射到一个值
2.当需要通过关键字实现对值的快速存取时使用
二、Map接口的抽象方法
1.查询方法:
(1)int size():返回Map中的元素个数
(2)boolean isEmpty():返回Map中是否包含元素,如不包括任何元素,则返回true
(3)boolean containsKey(Object key):判断给定的参数是否是Map中的一个关键字key
(4)boolean containsValue(Object val):判断给定的参数是否是Map中的一个值val
(5)Object get(Object key):返回Map中与给定关键字key相关联的值
(6)Collection values():返回包含Map中所有值的Collection对象
(7)Set keySet():返回包含Map中所有关键字的Set对象
(8)Set entrySet():返回包含Map中所有项的Set对象
2.修改方法:
(1)Object put(Object key,Object val):将给定的关键字(key)/值(value)对加入到Map对象中。其中关键字(key)必须唯一,否则,新加入的值会取代Map对象中已有的值
(2)void putAll(Map m):将给定的参数Map中的所有项加入到接收者Map对象中
(3)Object remove(Object key):将关键字为给定参数的项从Map对象中删除
(4)void clear():从Map对象中删除所有项
三、哈希表
1.也成散列表,用来存储群体对象的集合类结构
2.常用类:HashTable、HashMap
3.哈希表存储对象的方式:对象的位置和对象的关键属性k之间有一个特定的对应关系f,我们称之为哈希函数。它使每一个对象与一个唯一的存储位置相对应。因而在查找时,只要根据待查对象的关键属性k,计算f(k)的值即可知其存储位置
4.容量:哈希表的容量不是固定的,随着对象的加入,其容量可以自动扩充
5.关键字/键:每个存储的对象都需要一个关键字key,key可以是对象本身,也可以是对象的一部分(如对象的某个属性)
6.哈希码:要将对象存储到HashTable,就需要将关键字key映射到一个整型数据,称为key的哈希码
7.哈希表中每一项都有两个域:关键字域key及值域value。key和value都可以是任意的Object类型的对象,但不能为空,HashTable中所有关键字都是唯一的
8.装填因子:表中填入的项数/表的容量。装填因子小,存取效率高
7.HashMap构造方法:
(1)HashMap():默认容量16,默认装填因子0.75
(2)HashMap(int initialCapacity):容量initialCapacity,默认装填因子0.75
(3) HashMap(int initialCapacity,floatloadFactor):容量initialCapacity,装填因子loadFactor
(4)HashMap(Mapm):以参数m为初值构造新的HashMap
8.HashMap其他方法:
(1)void clear()
(2)Object clone()
(3)V compute(K key,BiFuncTionremappingFunction)
(4)V computeIfAbsent(Kkey,FuncTionmappingFunction)
(5)V computeIfPresent(Kkey,BiFuncTionremappingFunction)
(6)boolean containsKey(Object key)
(7)boolean containsValue(Object value)
(8)Set