Ubuntu安装Pyenv+Anaconda2+PyCharm+OpenAI-gym+Cuda+TensorFlow (四)
八. 测试
1. 测试Cuda
该部分主要参考南墙已破简书中的cuda测试内容
在/home/gh目录下下载cuda测试集源代码:
$ cuda-install-samples-8.0.sh ~
进入到这个文件夹进行编译:
$ cd ~/NVIDIA_CUDA-8.0_Samples
$ make
编译完成后运行deviceQuery.py和bandwidthTest.py两个脚本:
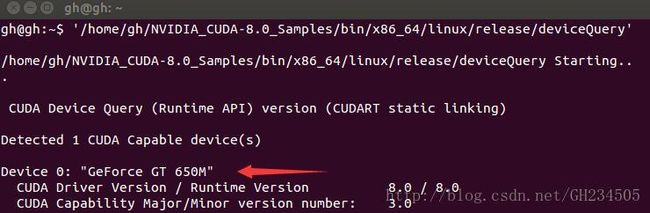

可以看到已经检测到显卡Device 0: “GeForce GT 650m”,并且最后一行运行结果Result = PASS。
这里我刚安完cuda和cuDNN之后进行测试同样遇到了脚本运行失败的结果,关于这个问题博主南墙已破给出了重启的解决方案,我是直接注销了下,然后再回来也行。
2. 测试TensorFlow和gym
打开PyCharm,新建一个叫做test的工程,python解释器选择anaconda下带有tensorflow环境的那个:

在PyCharm编辑栏File中选择Settings——Project:test——Project Interpreter,在右侧可以看到在这个python解释器下已经安装了的所有功能包,我们可以看到gym和tensorflow都已经安装在了这个tensorflow的虚拟环境中,此外还有很多其它常用的功能包。
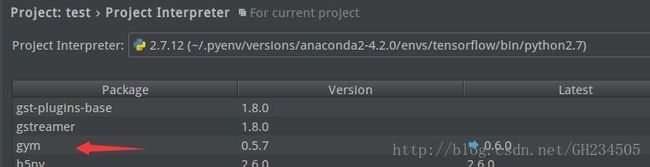
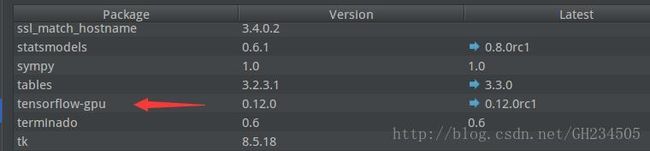
至此,可以确定gym和tensorflow安装无误。
3. 跑一个DQN的例子
该部分代码全部来自于知乎专栏—智能单元中Flood Sung的150行代码实现DQN算法,这个专栏对深度学习和增强学习有不少不错的科普贴,这里安利一下:P
在上面的新建工程test下,新建一个python脚本dqn,复制如下代码:
#!/usr/bin/env python # encoding: utf-8
"""
@author: GH
@contact: [email protected]
@file: dqn.py
@time: 16-12-28 下午3:32
"""
import gym
import tensorflow as tf
import numpy as np
import random
from collections import deque
# Hyper Parameters for DQN
GAMMA = 0.9 # discount factor for target Q
INITIAL_EPSILON = 0.5 # starting value of epsilon
FINAL_EPSILON = 0.01 # final value of epsilon
REPLAY_SIZE = 10000 # experience replay buffer size
BATCH_SIZE = 32 # size of minibatch
class DQN():
# DQN Agent
def __init__(self, env):
# init experience replay
self.replay_buffer = deque()
# init some parameters
self.time_step = 0
self.epsilon = INITIAL_EPSILON
self.state_dim = env.observation_space.shape[0]
self.action_dim = env.action_space.n
self.create_Q_network()
self.create_training_method()
# Init session
self.session = tf.InteractiveSession()
self.session.run(tf.initialize_all_variables())
def create_Q_network(self):
# network weights
W1 = self.weight_variable([self.state_dim,20])
b1 = self.bias_variable([20])
W2 = self.weight_variable([20,self.action_dim])
b2 = self.bias_variable([self.action_dim])
# input layer
self.state_input = tf.placeholder("float",[None,self.state_dim])
# hidden layers
h_layer = tf.nn.relu(tf.matmul(self.state_input,W1) + b1)
# Q Value layer
self.Q_value = tf.matmul(h_layer,W2) + b2
def create_training_method(self):
self.action_input = tf.placeholder("float",[None,self.action_dim]) # one hot presentation
self.y_input = tf.placeholder("float",[None])
Q_action = tf.reduce_sum(tf.mul(self.Q_value,self.action_input),reduction_indices = 1)
self.cost = tf.reduce_mean(tf.square(self.y_input - Q_action))
self.optimizer = tf.train.AdamOptimizer(0.0001).minimize(self.cost)
def perceive(self,state,action,reward,next_state,done):
one_hot_action = np.zeros(self.action_dim)
one_hot_action[action] = 1
self.replay_buffer.append((state,one_hot_action,reward,next_state,done))
if len(self.replay_buffer) > REPLAY_SIZE:
self.replay_buffer.popleft()
if len(self.replay_buffer) > BATCH_SIZE:
self.train_Q_network()
def train_Q_network(self):
self.time_step += 1
# Step 1: obtain random minibatch from replay memory
minibatch = random.sample(self.replay_buffer,BATCH_SIZE)
state_batch = [data[0] for data in minibatch]
action_batch = [data[1] for data in minibatch]
reward_batch = [data[2] for data in minibatch]
next_state_batch = [data[3] for data in minibatch]
# Step 2: calculate y
y_batch = []
Q_value_batch = self.Q_value.eval(feed_dict={self.state_input:next_state_batch})
for i in range(0,BATCH_SIZE):
done = minibatch[i][4]
if done:
y_batch.append(reward_batch[i])
else :
y_batch.append(reward_batch[i] + GAMMA * np.max(Q_value_batch[i]))
self.optimizer.run(feed_dict={
self.y_input:y_batch,
self.action_input:action_batch,
self.state_input:state_batch
})
def egreedy_action(self,state):
Q_value = self.Q_value.eval(feed_dict = {
self.state_input:[state]
})[0]
if random.random() <= self.epsilon:
return random.randint(0,self.action_dim - 1)
else:
return np.argmax(Q_value)
self.epsilon -= (INITIAL_EPSILON - FINAL_EPSILON)/10000
def action(self,state):
return np.argmax(self.Q_value.eval(feed_dict = {
self.state_input:[state]
})[0])
def weight_variable(self,shape):
initial = tf.truncated_normal(shape)
return tf.Variable(initial)
def bias_variable(self,shape):
initial = tf.constant(0.01, shape = shape)
return tf.Variable(initial)
# ---------------------------------------------------------
# Hyper Parameters
ENV_NAME = 'CartPole-v0'
EPISODE = 10000 # Episode limitation
STEP = 300 # Step limitation in an episode
TEST = 10 # The number of experiment test every 100 episode
def main():
# initialize OpenAI Gym env and dqn agent
env = gym.make(ENV_NAME)
agent = DQN(env)
for episode in xrange(EPISODE):
# initialize task
state = env.reset()
# Train
for step in xrange(STEP):
action = agent.egreedy_action(state) # e-greedy action for train
next_state,reward,done,_ = env.step(action)
# Define reward for agent
reward_agent = -1 if done else 0.1
agent.perceive(state,action,reward,next_state,done)
state = next_state
if done:
break
# Test every 100 episodes
if episode % 100 == 0:
total_reward = 0
for i in xrange(TEST):
state = env.reset()
for j in xrange(STEP):
env.render()
action = agent.action(state) # direct action for test
state,reward,done,_ = env.step(action)
total_reward += reward
if done:
break
ave_reward = total_reward/TEST
print 'episode: ',episode,'Evaluation Average Reward:',ave_reward
if ave_reward == 200:
break
if __name__ == '__main__':
main() 在PyCharm编辑栏Run条目下选择Edit Configuration,定义一个name,Scrips选择刚才新建的dqn.py,点击OK确定。
现在按下编辑栏上绿色小三角按钮就可以运行啦!
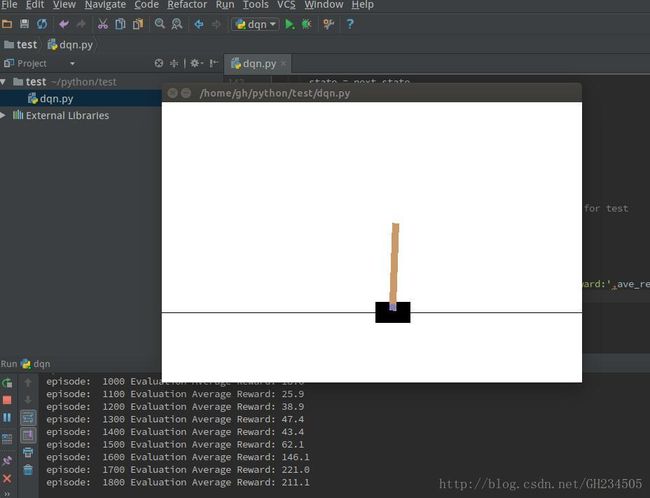
到此为止整个tensorflow+gym的框架就搭好啦,之后就可以自己写算法利用gym平台进行测试啦。
全文参考:
[1]. 南墙已破的简书http://www.jianshu.com/p/c89b97d052b7
[2]. TensorFlow官网https://www.tensorflow.org/get_started/os_setup#anaconda_installation
[3]. OpenAI-gym官网https://gym.openai.com/docs
[4]. 知乎专栏-智能单元https://zhuanlan.zhihu.com/intelligentunit
[5]. super的博客园http://www.cnblogs.com/super-d2/p/4725818.html
个人理解,如有错误请指出