Android之全面解析OkHttp源码
转载请标明出处:【顾林海的博客】
本平台的文章更新会有延迟,大家可以关注微信公众号-顾林海,更有Android、后端、Python、PHP、IOS以及React Native等等相关视频教程,如果大家想获取最新教程,请关注微信公众号,谢谢!
前言
OkHttp是目前非常火的网络库,支持HTTP/2,允许所有同一个主机地址的请求共享同一个socket连接,连接池减少请求延时,透明的GZIP压缩减少响应数据的大小,缓存响应内容,避免一些完全重复的请求。
OkHttpClient
private OkHttpClient mHttpClient = null;
private void initHttpClient() {
if (null == mHttpClient) {
mHttpClient = new OkHttpClient.Builder()
.readTimeout(5, TimeUnit.SECONDS)//设置读超时
.writeTimeout(5,TimeUnit.SECONDS)////设置写超时
.connectTimeout(15,TimeUnit.SECONDS)//设置连接超时
.retryOnConnectionFailure(true)//是否自动重连
.build();
}
}
在使用OkHttp请求网络时,需要先获取一个OkHttp的客户端对象OkHttpClient,OkHttpClient可以直接通过new来创建,也可以通过OkHttpClient静态内部类Builder来创建,日常开发最常用的是通过build的方式(建造者模式+链式调用)来创建,静态内部Builder提供了很多方法,比如readTimeout代表读时间、writeTimeout代表写时间、connectTimeout代表连接超时时间以及retryOnConnectionFailure代表是否重连等等方法,有了OkHttpClient之后就可以进行网络的同步和异步请求。
同步请求
private void synRequest() {
Request request=new Request.Builder()
.url("http://www.baidu.com")
.get()
.build();
Call call=mHttpClient.newCall(request);
try {
Response response=call.execute();
System.out.println(request.body().toString());
} catch (IOException e) {
e.printStackTrace();
}
}
进行网络请求时,需要先创建一个请求对象Request,Request对象也是通过build方式创建,在Request的静态内部类Builder中定义了设置请求地址、请求方式、请求头的方法。
接着创建Call对象,Call对象可以理解为Request和Response之间的一个桥梁,最后通过Call对象的execute方法完成Response的读取,
总结同步请求的三个步骤如下:
-
创建OkHttpClient和Request对象。
-
将Request对象封装成Call对象。
-
调用Call的execute()方法发送同步请求。
注意:OkHttp的同步请求会阻塞当前线程,因此不能在UI线程中请求,需要开启子线程,在子线程中发送请求。
异步请求
private void asyRequest() {
final Request request=new Request.Builder()
.url("http://www.baidu.com")
.get()
.build();
Call call=mHttpClient.newCall(request);
call.enqueue(new Callback() {
@Override
public void onFailure(Call call, IOException e) {
}
@Override
public void onResponse(Call call, Response response) throws IOException {
System.out.println(request.body().toString());
}
});
}
异步请求与同步请求的前两步都是一样的创建OkHttpClient和Request对象以及将Request对象封装成Call对象,通过Call对象的enqueue方法执行异步请求,enqueue传入一个Callback对象,Callback提供了两个回调方法,分别是成功和失败。
总结异步请求的三个步骤如下:
-
创建OkHttpClient和Request对象。
-
将Request对象封装成Call对象。
-
调用Call的enqueue方法进行异步请求。
注意:OkHttp的异步请求,其中两个回调方法onResponse和onFailure都是在工作线程中执行的,执行结果可以通过Handler来发送。
解析同步请求
无论是同步请求还是异步请求,都需要一个OkHttpClient。
private OkHttpClient mHttpClient = null;
private void initHttpClient() {
if (null == mHttpClient) {
mHttpClient = new OkHttpClient.Builder()
.readTimeout(5, TimeUnit.SECONDS)//设置读超时
.writeTimeout(5,TimeUnit.SECONDS)////设置写超时
.connectTimeout(15,TimeUnit.SECONDS)//设置连接超时
.retryOnConnectionFailure(true)//是否自动重连
.build();
}
}
进入OkHttpClient的静态内部类Builder:
public static final class Builder {
Dispatcher dispatcher;
ConnectionPool connectionPool;
public Builder() {
//分发器
dispatcher = new Dispatcher();
//连接池
connectionPool = new ConnectionPool();
...
}
public OkHttpClient build() {
return new OkHttpClient(this);
}
}
Builder构造器进行初始化操作,这里先介绍几个比较重要参数
-
Dispatcher分发器:它的作用是用于在异步请求时是直接进行处理,还是进行缓存等待,对于同步请求,Dispatcher会将请求放入队列中。
-
ConnectionPool连接池:可以将客户端与服务器的连接理解为一个connection,每一个connection都会放在ConnectionPool这个连接池中,当请求的URL相同时,可以复用连接池中的connection,并且ConnectionPool实现了哪些网络连接可以保持打开状态以及哪些网络连接可以复用的相应策略的设置。
通过Builder进行了一些参数的初始化,最后通过build方法创建OkHttpClient对象。
创建OkHttpClient对象时使用到了设计模式中的Builder模式,将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。
private void synRequest() {
Request request=new Request.Builder()
.url("http://www.baidu.com")
.get()
.build();
Call call=mHttpClient.newCall(request);
try {
Response response=call.execute();
System.out.println(request.body().toString());
} catch (IOException e) {
e.printStackTrace();
}
}
创建完OkHttpClient对象后,接着创建Request对象,也就是我们的请求对象。Request的创建方式和OkHttpClient的创建方式一样,都使用了Builder模式。
Request内部类Builder的构造方法:
public static class Builder {
String method;
Headers.Builder headers;
public Builder() {
this.method = "GET";
this.headers = new Headers.Builder();
}
}
Request内部类的Builder构造方法非常的简单,初始化了请求方式,默认是GET请求,接着初始化了头部信息。
接着看它的build方法:
public Request build() {
if (url == null) throw new IllegalStateException("url == null");
return new Request(this);
}
build方法中先校验传入的url是否为空,再将当前配置的请求参数传给Request。
Request的构造方法:
Request(Builder builder) {
this.url = builder.url;
this.method = builder.method;
this.headers = builder.headers.build();
this.body = builder.body;
this.tags = Util.immutableMap(builder.tags);
}
将我们配置好的参数,比如请求地址url、请求方式、请求头部信息、请求体以及请求标志传给了Request。
总结同步请求的前两步:
-
创建一个OkHttpClient对象。
-
构建了携带请求信息的Request对象。
完成上面两步后,就可以通过OkHttpClient的newCall方法将Request包装成Call对象。
Call call=mHttpClient.newCall(request);
进入OkHttpClient的newCall方法:
@Override public Call newCall(Request request) {
return RealCall.newRealCall(this, request, false /* for web socket */);
}
Call只是一个接口,因此它的所有操作都在RealCall中实现的。
看一下RealCall的newRealCall方法:
static RealCall newRealCall(OkHttpClient client, Request originalRequest, boolean forWebSocket) {
RealCall call = new RealCall(client, originalRequest, forWebSocket);
call.eventListener = client.eventListenerFactory().create(call);
return call;
}
可以看到newRealCall方法只有三行代码,第一行创建RealCall对象,第二行设置RealCall的eventListener也就是监听事件,最后返回RealCall对象,我们看下RealCall的构造方法。
private RealCall(OkHttpClient client, Request originalRequest, boolean forWebSocket) {
this.client = client;
this.originalRequest = originalRequest;
this.forWebSocket = forWebSocket;
//重定向拦截器
this.retryAndFollowUpInterceptor = new RetryAndFollowUpInterceptor(client, forWebSocket);
}
RealCall的构造方法中,设置了前两步创建的对象OkHttpClient和Request并设置了重定向拦截器(拦截器概念后面会进行详解)。
到这里Call对象也创建完毕了,最后通过Call的execute方法来完成同步请求,看一下execute方法到底做了哪些操作,由于Call是接口,execute方法的具体实现在RealCall中:
@Override public Response execute() throws IOException {
//第一步:判断同一Http是否请求过
synchronized (this) {
if (executed) throw new IllegalStateException("Already Executed");
executed = true;
}
//捕捉Http请求的异常堆栈信息
captureCallStackTrace();
//监听请求开始
eventListener.callStart(this);
try {
//第二步:同步请求添加到同步队列中
client.dispatcher().executed(this);
//第三步:
Response result = getResponseWithInterceptorChain();
if (result == null) throw new IOException("Canceled");
return result;
} catch (IOException e) {
eventListener.callFailed(this, e);
throw e;
} finally {
//第四步:回收请求
client.dispatcher().finished(this);
}
}
第一步,在同步代码块中判断标志位executed是否为ture,为true抛出异常,也就是说同一个Http请求只能执行一次。
第二步,调用Dispatcher分发器的executed方法,我们进入Dispatcher的executed方法中。
private final Deque<RealCall> runningSyncCalls = new ArrayDeque<>();
synchronized void executed(RealCall call) {
runningSyncCalls.add(call);
}
Dispatcher的executed方法只是将我们的RealCall对象也就是请求添加到runningSyncCalls同步队列中。
Dispatcher的作用就是维持Call请求发给它的一些状态,同时维护一个线程池,用于执行网络请求,Call这个请求在执行任务时通过Dispatcher分发器,将它的任务添加到执行队列中进行操作。
第三步,通过getResponseWithInterceptorChain方法获取Response对象,getResponseWithInterceptorChain方法的作用是通过一系列拦截器进行操作,最终获取请求结果。
第四步,在finally块中,主动回收同步请求,进入Dispatcher的finished方法:
void finished(RealCall call) {
finished(runningSyncCalls, call, false);
}
private <T> void finished(Deque<T> calls, T call, boolean promoteCalls) {
int runningCallsCount;
Runnable idleCallback;
synchronized (this) {
//移除请求
if (!calls.remove(call)) throw new AssertionError("Call wasn't in-flight!");
if (promoteCalls) promoteCalls();
//计算同步请求队列+异步请求队列的总数
runningCallsCount = runningCallsCount();
idleCallback = this.idleCallback;
}
if (runningCallsCount == 0 && idleCallback != null) {
idleCallback.run();
}
}
将我们正在执行的同步请求RealCall对象通过finished方法传了进去,接着从当前的同步队列中移除本次同步请求,promoteCalls默认传入是false,也就是promoteCalls方法不会执行到,但如果是异步请求,这里传入的是ture,会执行promoteCalls方法,关于异步请求后面进行讲解。从同步队列中清除当前请求RealCall后,重新计算当前请求总数,我们可以看下runningCallsCount方法的具体实现。
public synchronized int runningCallsCount() {
return runningAsyncCalls.size() + runningSyncCalls.size();
}
方法非常简单,就是计算正在执行的同步请求和异步请求的总和。
在finished方法最后判断runningCallsCount,如果正在执行的请求数为0并且idleaCallback不为null,就执行idleaCallback的回调方法run。
到这里同步请求已经介绍完了,在同步请求中Dispatcher分发器做的工作很简单,就做了保存同步请求和移除同步请求的操作。
总结流程图如下:
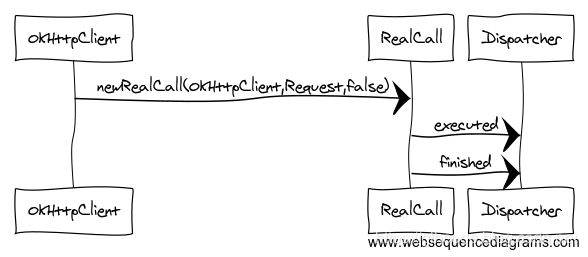
解析异步请求
其实从OkHttp的同步和异步的调用来看差别不是很大,在剖析OkHttp中的同步请求一节中知道同步是通过Call对象的execute()方法,而这节的异步请求调用的是Call对象的enqueue方法,但异步请求机制与同步请求相比,还是有所区别,这节就来分析异步请求的流程以及源码分析。
还是先贴出异步请求的代码:
private OkHttpClient mHttpClient = null;
private void initHttpClient() {
if (null == mHttpClient) {
mHttpClient = new OkHttpClient.Builder()
.readTimeout(5, TimeUnit.SECONDS)//设置读超时
.writeTimeout(5, TimeUnit.SECONDS)////设置写超时
.connectTimeout(15, TimeUnit.SECONDS)//设置连接超时
.retryOnConnectionFailure(true)//是否自动重连
.build();
}
}
private void asyRequest() {
final Request request = new Request.Builder()
.url("http://www.baidu.com")
.get()
.build();
Call call = mHttpClient.newCall(request);
call.enqueue(new Callback() {
@Override
public void onFailure(Call call, IOException e) {
}
@Override
public void onResponse(Call call, Response response) throws IOException {
System.out.println(request.body().toString());
}
});
}
这段代码很熟悉,我们快速过一下流程:
-
创建OkHttpClient对象。
-
创建Request对象。
-
通过OkHttpClient的newCall方法将Request对象封装Http实际请求的Call对象。
-
最后通过Call对象的enqueue方法传入Callback对象并实现两个回调方法。
这里最大的区别就是最后一步调用的是enqueue方法,前三步都没有发起真正的网络请求,真正的网络请求是在第四步,所以我们着重看最后一步。
在enqueue方法中,会传入Callback对象进来,这个Callback对象就是用于请求结束后对结果进行回调的,进入enqueu方法。
public interface Call extends Cloneable {
...
void enqueue(Callback responseCallback);
...
}
发现这个Call只是接口,在剖析OkHttp中的同步请求一节中知道RealCall才是真正实现Call的类。
点击进入RealCall的enqueue方法:
@Override public void enqueue(Callback responseCallback) {
//判断同一Http是否请求过
synchronized (this) {
if (executed) throw new IllegalStateException("Already Executed");
executed = true;
}
//捕捉Http请求的异常堆栈信息
captureCallStackTrace();
eventListener.callStart(this);
//重点1
client.dispatcher().enqueue(new RealCall.AsyncCall(responseCallback));
}
在enqueue方法中会先判断RealCall这个Http请求是否请求过,请求过会抛出异常。
接着看最后一行代码重点1:
1、传入的Callback对象被封装成了AsyncCall对象,点进去看一下AsyncCall对象到底是干什么的。
final class AsyncCall extends NamedRunnable {
private final Callback responseCallback;
AsyncCall(Callback responseCallback) {
super("OkHttp %s", redactedUrl());
this.responseCallback = responseCallback;
}
...
}
这个AsyncCall继承了NameRunnable,这个NameRunnable又是什么呢?点进去看一下:
public abstract class NamedRunnable implements Runnable {
}
原来NameRunnable就是一个Runnable对象。回过头来总结一下,也就是说我们传入的Callback对象被封装成AsyncCall对象,这个AsyncCall对象本质就是一个Runnable对象。
2、获取Dispatcher分发器,调用Dispatcher对象的enqueue方法并将AsyncCall对象作为参数传递过去,最终完成异步请求,我们看下Dispatcher的enqueue方法。
private int maxRequests = 64;
private int maxRequestsPerHost = 5;
synchronized void enqueue(RealCall.AsyncCall call) {
if (runningAsyncCalls.size() < maxRequests && runningCallsForHost(call) < maxRequestsPerHost) {
//第一步
runningAsyncCalls.add(call);
executorService().execute(call);
} else {
//第二步
readyAsyncCalls.add(call);
}
}
在enqueue方法前使用了synchronized关键字进行修饰,也就是为这个方法加了个同步锁,继续往下看第一步,先是判断当前异步请求总数是否小于设定的最大请求数(默认是64),以及正在运行的每个主机请求数是否小于设定的主机最大请求数(默认是5),如果满足这两个条件,就会把传递进来的AsyncCall对象添加到正在运行的异步请求队列中,然后通过线程池执行这个请求。如果满足不了上面的两个条件就会走第二步,将AsyncCall对象存入readyAsyncCalls队列中,这个readyAsyncCalls就是用来存放等待请求的一个队列。
总结RealCall的enqueue方法:
-
判断当前Call:实际的Http请求是否只执行一次,如果不是抛出异常。
-
封装成一个AsyncCall对象:将Callback对象封装成一个AsyncCall对象,AsyncCall对象就是一个Runnable对象。
-
client.dispatcher().enqueue():构建完AsyncCall也就是Runnable对象后,调用Dispatcher对象的enqueue方法来进行异步的网络请求,并判断当前请求数小于64以及当前host请求数小于5的情况下,将Runnable对象放入正在请求的异步队列中并通过线程池执行RealCall请求。如果不满足条件,将Runnable添加到等待就绪的异步请求队列当中。
在上面总结的第三步中,满足条件会将AsyncCall对象通过线程池执行,我们看一下线程池方法executorService():
private @Nullable ExecutorService executorService;
public synchronized ExecutorService executorService() {
if (executorService == null) {
executorService = new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(), Util.threadFactory("OkHttp Dispatcher", false));
}
return executorService;
}
executorService方法只是返回一个线程池对象executorService。
获取线程池对象后,就可以调用它的execute方法,execute方法需要传入一个Runnable对象,AsyncCall对象继承NamedRunnable对象,而NamedRunnable又继承了Runnable对象,那么AsyncCall就是一个Runnable对象,这里就会将AsyncCall对象传入。
在源码中发现AsyncCall并没有实现run方法,那么这个run方法一定就是在它的父类NamedRunnable中,我们点击进去看下:
public abstract class NamedRunnable implements Runnable {
protected final String name;
public NamedRunnable(String format, Object... args) {
this.name = Util.format(format, args);
}
@Override public final void run() {
String oldName = Thread.currentThread().getName();
Thread.currentThread().setName(name);
try {
execute();
} finally {
Thread.currentThread().setName(oldName);
}
}
protected abstract void execute();
}
发现NamedRunnable是一个抽象类,在run方法中并没有做实际操作,只是调用了抽象方法execute,这是一个典型的模板方法模式。既然AsyncCall继承了NamedRunnable这个抽象类,那么抽象方法execute的具体实现就交由AsyncCall来实现了。
进入AsyncCall中的execute方法:
@Override protected void execute() {
boolean signalledCallback = false;
try {
//重点1
Response response = getResponseWithInterceptorChain();
if (retryAndFollowUpInterceptor.isCanceled()) {
//重点2:重定向和重试拦截器
signalledCallback = true;
responseCallback.onFailure(RealCall.this, new IOException("Canceled"));
} else {
signalledCallback = true;
responseCallback.onResponse(RealCall.this, response);
}
} catch (IOException e) {
if (signalledCallback) {
// Do not signal the callback twice!
Platform.get().log(INFO, "Callback failure for " + toLoggableString(), e);
} else {
eventListener.callFailed(RealCall.this, e);
responseCallback.onFailure(RealCall.this, e);
}
} finally {
//重点3:请求当前的异步请求
client.dispatcher().finished(this);
}
}
在重点1处通过getResponseWithInterceptorChain()方法获取返回的Response对象,getResponseWithInterceptorChain方法的作用是通过一系列的拦截器获取Response对象。
在重点2处判断重定向和重试拦截器是否取消,如果取消,调用responseCallback的onFailure回调,responseCallback就是我们通过enqueue方法传入的Callback对象。如果没取消,调用responseCallback的onResponse回调。
由于execute方法是在run方法中执行的,所以onFailure和onResponse回调都是在子线程当中。
在重点3处finally块中,调用Dispatcher的finished方法。
void finished(AsyncCall call) {
finished(runningAsyncCalls, call, true);
}
private <T> void finished(Deque<T> calls, T call, boolean promoteCalls) {
int runningCallsCount;
Runnable idleCallback;
synchronized (this) {
//移除请求
if (!calls.remove(call)) throw new AssertionError("Call wasn't in-flight!");
if (promoteCalls) promoteCalls();
//计算同步请求队列+异步请求队列的总数
runningCallsCount = runningCallsCount();
idleCallback = this.idleCallback;
}
if (runningCallsCount == 0 && idleCallback != null) {
idleCallback.run();
}
}
finished方法内部会将本次的异步请求RealCall从正在请求的异步请求队列中移除,由于promoteCalls传入的是true,接着调用promoteCalls()方法,接着统计正在请求的同步和异步的请求总数,以及判断当前总的请求数如果等于0并且idleCallback对象不为空的情况下执行idleCallback对象的run方法。
finished方法的介绍在剖析OkHttp中的同步请求一节中其实已经介绍过了,唯一有区别的就是promoteCalls参数,同步的时候传入的是false,但在异步请求时传入的是true,也就是会执行promoteCalls方法。
private void promoteCalls() {
if (runningAsyncCalls.size() >= maxRequests) return; // Already running max capacity.
if (readyAsyncCalls.isEmpty()) return; // No ready calls to promote.
for (Iterator<AsyncCall> i = readyAsyncCalls.iterator(); i.hasNext(); ) {
AsyncCall call = i.next();
if (runningCallsForHost(call) < maxRequestsPerHost) {
i.remove();
runningAsyncCalls.add(call);
executorService().execute(call);
}
if (runningAsyncCalls.size() >= maxRequests) return; // Reached max capacity.
}
}
在完成异步请求后,需要将当前的异步请求RealCall从正在请求的异步队列中移除,移除完毕后会通过promoteCalls方法,将等待就绪的异步队列中的请求添加到正在请求的异步请求队列中去并通过线程池来执行异步请求。
任务调度器Dispatcher
OkHttp发送的同步或异步请求队列的状态会在dispatcher中进行管理,dispatcher的作用就是用于维护同步和异步请求的状态,内部维护一个线程池,用于执行相应的请求。
在dispatcher内部维护着三个队列,这三个队列如下:
private final Deque<RealCall.AsyncCall> readyAsyncCalls = new ArrayDeque<>();
private final Deque<RealCall.AsyncCall> runningAsyncCalls = new ArrayDeque<>();
private final Deque<RealCall> runningSyncCalls = new ArrayDeque<>();
runningAsyncCalls表示的是正在执行的异步请求队列。
readyAsyncCalls表示就绪状态的异步请求队列,如果当前的请求不满足某种条件时,当前的异步请求会进入就绪等待的异步请求队列中,当满足某种条件时,会从就绪等待的异步请求队列中取出异步请求,放入正在执行的异步请求队列中。
runningSyncCalls表示的正在执行的同步请求队列。
除了上面的三个队列,还有一个参数也是非常重要的,如下:
private @Nullable ExecutorService executorService;
executorService就是一个线程池对象,OkHttp的异步请求操作会放入这个线程池中。
OkHttp的异步请求在dispatcher中的一系列操作可以理解为生产者消费者模式,其中Dispatcher是生产者,它是运行在主线程中的,ExecutorService代表消费者池。
当同步和异步请求结束后,会调用dispatcher的finished方法,将当前的请求从队列中移除。
client.dispatcher().finished(this);
这段代码是在finally块中,也就是说,无论请求成不成功,还是出现异常,这段代码都会执行,保证了请求的整个生命周期从开始到销毁。
接下来,我们重新看看同步请求和异步请求在dispatcher中的操作。
1、同步请求会执行dispatcher的executed方法:
synchronized void executed(RealCall call) {
runningSyncCalls.add(call);
}
在executed方法中,只是将当前请求RealCall存入正在执行的同步请求队列中。
2、异步请求会执行dispatcher的enqueue方法;
private int maxRequests = 64;
private int maxRequestsPerHost = 5;
synchronized void enqueue(RealCall.AsyncCall call) {
if (runningAsyncCalls.size() < maxRequests && runningCallsForHost(call) < maxRequestsPerHost) {
//第一步
runningAsyncCalls.add(call);
executorService().execute(call);
} else {
//第二步
readyAsyncCalls.add(call);
}
}
上一节在讲解异步请求时已经解释过了,这里直接复制过来:在enqueue方法前使用了synchronized关键字进行修饰,也就是为这个方法加了个同步锁,继续往下看第一步,先是判断当前异步请求总数是否小于设定的最大请求数(默认是64),以及正在运行的每个主机请求数是否小于设定的主机最大请求数(默认是5),如果满足这两个条件,就会把传递进来的AsyncCall对象添加到正在运行的异步请求队列中,然后通过线程池执行这个请求。如果满足不了上面的两个条件就会走第二步,将AsyncCall对象存入readyAsyncCalls队列中,这个readyAsyncCalls就是用来存放等待请求的一个异步队列。
其中线程池的创建和获取代码如下:
public synchronized ExecutorService executorService() {
if (executorService == null) {
executorService = new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(), Util.threadFactory("OkHttp Dispatcher", false));
}
return executorService;
}
创建线程池时,第一个参数表示核心线程数,设置为0,当线程池空闲一段时间后,就会将线程池中的所有线程进行销毁;第二个参数表示最大线程数,设置为整型的最大值,具体多少线程数还是受限OkHttp中的maxRequests这个参数;第三个参数表示当我们的线程数大于核心线程数的时候,多余的空闲线程存活的最大时间为60秒,结合第一个核心线程数为0,也就是说OkHttp中的线程在工作完毕后,会在60秒之内进行关闭。
拦截器介绍
在OkHttp中执行同步请求会阻塞当前线程,直到HTTP响应返回,同步请求使用的是execute()方法;而异步请求类似于非阻塞式的请求,它的执行结果一般通过接口回调的方式告知调用者,异步请求使用的是enqueue(Callback)方法;
OkHttp中不管是同步还是异步,都是通过拦截器完成网络的获取。
官网对拦截器的解释是:拦截器是OkHttp中提供的一种强大机制,它可以实现网络监听、请求以及响应重写、请求失败重试等功能。
看下面这张图:
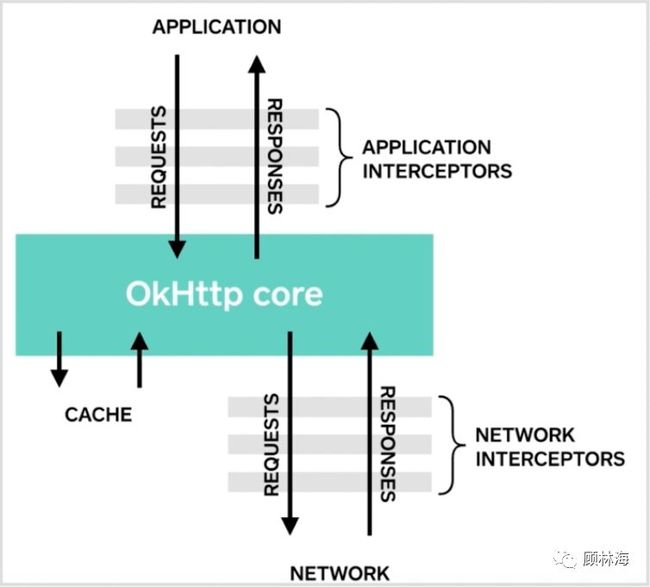
在这张图中可以看到有两种拦截器,一种是APPLICATION INTERCEPTORS,也就是应用拦截器;第二种是NETWORK INTERCEPTORS,表示网络拦截器。除了这两种拦截器,重要的是中间OkHttp core这块,这是OkHttp提供的内部拦截器。
看下图:
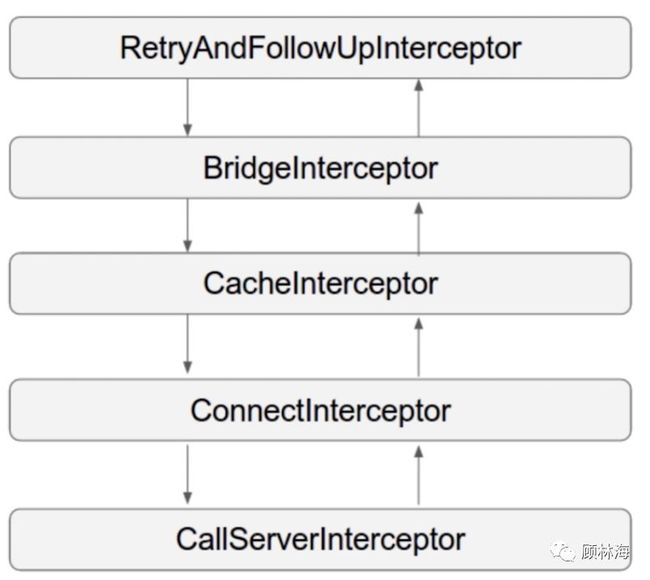
这是OkHttp提供给我们的拦截器,内部是以拦截器的链的形式执行HTTP的请求,其中RetryAndFollowUpInterceptor是重试和失败重定向拦截器,BridgeInterceptor是桥接和适配拦截器,CacheInterceptor是缓存拦截器,ConnectInterceptor是连接拦截器,负责建立可用的连接,CallServerInterceptor负责将HTTP的请求写入网络的IO流中,并且从网络IO流中读取服务端返回给客户端的数据。
看过前面几节的同学应该知道,无论是同步请求还是异步请求,最终执行网络请求并获取的Response都是通过getResponseWithInterceptorChain()方法获取的,代码如下。
//异步请求
@Override protected void execute() {
boolean signalledCallback = false;
try {
//重点1 使用拦截器链
Response response = getResponseWithInterceptorChain();
...
} catch (IOException e) {
...
} finally {
回收请求
client.dispatcher().finished(this);
}
}
//同步请求
@Override public Response execute() throws IOException {
//第一步:判断同一Http是否请求过
...
//捕捉Http请求的异常堆栈信息
...
//监听请求开始
...
try {
//第二步:同步请求添加到同步队列中
...
//第三步:使用拦截器链
Response result = getResponseWithInterceptorChain();
...
} catch (IOException e) {
...
} finally {
//第四步:回收请求
client.dispatcher().finished(this);
}
}
getResponseWithInterceptorChain()方法返回的就是我们网络请求的响应结果Response对象。
进入getResponseWithInterceptorChain()方法:
Response getResponseWithInterceptorChain() throws IOException {
// Build a full stack of interceptors.
List<Interceptor> interceptors = new ArrayList<>();
//用户自定义的拦截器
interceptors.addAll(client.interceptors());
//添加OkHttp提供的五个拦截器以及networkInterceptors
interceptors.add(retryAndFollowUpInterceptor);
interceptors.add(new BridgeInterceptor(client.cookieJar()));
interceptors.add(new CacheInterceptor(client.internalCache()));
interceptors.add(new ConnectInterceptor(client));
if (!forWebSocket) {
interceptors.addAll(client.networkInterceptors());
}
interceptors.add(new CallServerInterceptor(forWebSocket));
//标记1
Interceptor.Chain chain = new RealInterceptorChain(interceptors, null, null, null, 0,
originalRequest, this, eventListener, client.connectTimeoutMillis(),
client.readTimeoutMillis(), client.writeTimeoutMillis());
//标记2
return chain.proceed(originalRequest);
}
getResponseWithInterceptorChain方法一开始将我们需要的拦截器添加到一个集合中,其中就包括我们自定义的拦截器以及上面提到的几种拦截器。
接着在标记1处创建了一个RealInterceptorChain对象,传入的第一个参数就是上面的添加的一系列拦截器,创建完毕后,在标记2处执行RealInterceptorChain对象的proceed方法。
进入RealInterceptorChain的proceed方法:
@Override public Response proceed(Request request) throws IOException {
return proceed(request, streamAllocation, httpCodec, connection);
}
继续往下看:
public Response proceed(Request request, StreamAllocation streamAllocation, HttpCodec httpCodec,
RealConnection connection) throws IOException {
...
//标记1
RealInterceptorChain next = new RealInterceptorChain(interceptors, streamAllocation, httpCodec,
connection, index + 1, request, call, eventListener, connectTimeout, readTimeout,
writeTimeout);
//标记2:取出index位置的拦截器
Interceptor interceptor = interceptors.get(index);
//标记3
Response response = interceptor.intercept(next);
...
return response;
}
在标记1处又创建了一个RealInterceptorChain对象,在创建对象时,传入的第五个参数是index+1,这样的话在下次访问时,只能从下一个拦截器开始进行访问,而不能从当前拦截器。
在标记2处取出第index位置的拦截器。
在标记3处将代表下一个拦截器的链的RealInterceptorChain对象传入当前位置的拦截器中,在当前拦截器链中执行请求,获取Response后依次返回给它的上一个拦截器,如果当前拦截器没有获取Response就继续调用RealInterceptorChain对象的prceed方法来创建下一个拦截器链,就这样拦截器链一层一层的调用,这样所有的拦截器链构成了一个完整的链条。
到目前为止,总结如下:
-
创建一系列拦截器,并将其放入一个拦截器list集合中。
-
创建一个拦截器链RealInterceptorChain,并执行拦截器链的proceed方法,这个proceed方法的核心是继续创建下一个拦截器链。
我们看下RetryAndFollowUpInterceptor这个拦截器,它是重试和失败重定向拦截器。
@Override public Response intercept(Interceptor.Chain chain) throws IOException {
...
RealInterceptorChain realChain = (RealInterceptorChain) chain;
...
response = realChain.proceed(request, streamAllocation, null, null);
...
}
可以看到RetryAndFollowUpInterceptor拦截器的intercept方法,内部又执行了传递进来的RealInterceptorChain对象的proceed方法,而proceed方法在上面介绍过了,作用是创建下一个拦截器链,这样就说明了整个拦截器链的执行过程就像链条一样,一环扣一环。
RetryAndFollowUpInterceptor拦截器
RetryAndFollowupInterceptor是重试重定向拦截器,它的主要作用是负责失败重连。OkHttp中的重定向功能是默认开启的。
该拦截器方法如下:
@Override public Response intercept(Interceptor.Chain chain) throws IOException {
Request request = chain.request();
RealInterceptorChain realChain = (RealInterceptorChain) chain;
...
//标记1
StreamAllocation streamAllocation = new StreamAllocation(client.connectionPool(),
createAddress(request.url()), call, eventListener, callStackTrace);
...
while (true) {
//取消,释放
if (canceled) {
streamAllocation.release();
throw new IOException("Canceled");
}
Response response;
boolean releaseConnection = true;
...
//标记2
response = realChain.proceed(request, streamAllocation, null, null);
releaseConnection = false;
...
Request followUp;
//标记3
followUp = followUpRequest(response, streamAllocation.route());
...
//标记4
if (++followUpCount > MAX_FOLLOW_UPS) {
streamAllocation.release();
throw new ProtocolException("Too many follow-up requests: " + followUpCount);
}
...
}
}
在intercept方法中省略了一些代码,我们只看核心代码:
在标记1处创建了StreamAllocation对象,创建的StreamAllocation对象在RetryAndFollowupInterceptor拦截器中并没有使用到。
StreamAllocation对象会通过标记2处的proceed方法传递给下一个拦截器,直到ConnectInterceptor拦截器,StreamAllocation的主要作用是提供建立HTTP请求所需要的网络组件,ConnectInterceptor从RealInterceptorChain获取前面的Interceptor传过来的StreamAllocation对象,执行StreamAllocation对象的newStream()方法完成所有的连接建立工作,并将这个过程中创建的用于网络IO的RealConnection对象,以及与服务器交互最为关键的HttpCodec等对象传递给后面的CallServerInterceptor拦截器。
在标记3处,会对返回的Response进行检查,通过followUpRequest方法对Response返回的状态码判断,并创建重定向需要发出的Request对象。
followUpRequest代码如下:
private Request followUpRequest(Response userResponse, Route route) throws IOException {
if (userResponse == null) throw new IllegalStateException();
int responseCode = userResponse.code();
final String method = userResponse.request().method();
switch (responseCode) {
case HTTP_PROXY_AUTH://407 代理服务器认证
...
case HTTP_UNAUTHORIZED://401 身份未认证
...
case HTTP_PERM_REDIRECT://308
case HTTP_TEMP_REDIRECT://307
//当请求的method不为GET和HEAD时不进行重定向
...
case HTTP_MULT_CHOICE://300 多种选择
case HTTP_MOVED_PERM://301 永久移除
case HTTP_MOVED_TEMP://302 临时重定向
case HTTP_SEE_OTHER://303 其他问题
...
case HTTP_CLIENT_TIMEOUT://408 请求超时
...
case HTTP_UNAVAILABLE://503 服务不可用
...
default:
return null;
}
}
followUpRequest方法主要是对返回的状态码进行判断,根据特定的状态码创建重定向需要的Request对象。
回到上面拦截器intercept方法,在标记4判断followUpCount是否大于MAX_FOLLOW_UPS(20),也就是说重定向次数上限为20,当重试次数超过20的时候,会释放StreamAllocation这个对象,这样做是为了防止无限制的重试网络请求,从而造成资源的浪费,关于重定向的次数建议可以按照Chrome遵循21个重定向;Firefox、CURL和WGET遵循20;Safari遵循16;HTTP/1推荐5。
总结RetryAndFollowupInterceptor拦截器:
-
创建StreamAllocation对象。
-
调用RealInterceptorChain.proceed()进行网络请求。
-
根据异常结果或响应结果判断是否进行重新请求。
-
调用下一个拦截器,对Response进行处理,返回给上一个拦截器。
BridgeInterceptor拦截器
BridgeInterceptor是桥接和适配拦截器,它的作用是设置内容长度、编码方式以及压缩等等一系列操作,主要是添加头部的作用。
该拦截器方法如下:
@Override public Response intercept(Interceptor.Chain chain) throws IOException {
Request userRequest = chain.request();
Request.Builder requestBuilder = userRequest.newBuilder();
//====================添加头部信息========================
RequestBody body = userRequest.body();
...
if (userRequest.header("Connection") == null) {
//标记1
requestBuilder.header("Connection", "Keep-Alive");
}
...
//标记2
Response networkResponse = chain.proceed(requestBuilder.build());
//标记3
HttpHeaders.receiveHeaders(cookieJar, userRequest.url(), networkResponse.headers());
Response.Builder responseBuilder = networkResponse.newBuilder()
.request(userRequest);
//标记4
if (transparentGzip
&& "gzip".equalsIgnoreCase(networkResponse.header("Content-Encoding"))
&& HttpHeaders.hasBody(networkResponse)) {
//标记5
GzipSource responseBody = new GzipSource(networkResponse.body().source());
...
}
return responseBuilder.build();
}
intercept方法主要是给Request添加一些头部信息,在标记1处的Connection设置为Keep-Alive,Keep-Alive的作用是当我们开启一个HTTP连接后,在一定时间内保持它的连接状态。
在标记2处调用了拦截器链的proceed方法向服务器发起请求。
在标记3处通过HttpHeaders的receiveHeaders方法,通过网络请求,服务器返回的Response转化为客户端可以识别的Response,如果HTTP默认支持gzip,那么BridgeInterceptor拦截器将会对这个Response进行解压,最终得到客户端使用的Response。
在标记4处,对transparentGzip标志位进行判断,如果transparentGzip为true就表面Accept-Encoding支持gzip压缩;再判断头部的Content-Encoding是否为gzip,保证服务端返回的响应体内容是经过了gzip压缩的;最后判断HTTP头部是否有Body。当满足这些条件后在标记5处将Response的body转换为GzipSource类型,这样的话client端直接以解压的方式读取数据。
总结BridgeInterceptor拦截器:
-
负责将用户构建的一个Request请求转化为能够进行网络访问的请求,通过给头部添加信息。
-
将这个符合网络请求的Request进行网络请求。
-
将网络请求回来的响应Response转化为用户可用的Response。
CacheInterceptor拦截器
缓存策略
mHttpClient = new OkHttpClient.Builder()
.cache(new Cache(new File("cache"),30*1024*1024))//使用缓存策略
.build();
在OkHttp中使用缓存可以通过OkHttpClient的静态内部类Builder的cache方法进行配置,cache方法传入一个Cache对象。
public Cache(File directory, long maxSize) {
this(directory, maxSize, FileSystem.SYSTEM);
}
创建Cache对象时需要传入两个参数,第一个参数directory代表的是缓存目录,第二个参数maxSize代表的是缓存大小。
在Chache有一个很重要的接口:
public final class Cache implements Closeable, Flushable {
final InternalCache internalCache = new InternalCache() {
@Override
public Response get(Request request) throws IOException {
return Cache.this.get(request);
}
@Override
public CacheRequest put(Response response) throws IOException {
return Cache.this.put(response);
}
@Override
public void remove(Request request) throws IOException {
Cache.this.remove(request);
}
@Override
public void update(Response cached, Response network) {
Cache.this.update(cached, network);
}
@Override
public void trackConditionalCacheHit() {
Cache.this.trackConditionalCacheHit();
}
@Override
public void trackResponse(CacheStrategy cacheStrategy) {
Cache.this.trackResponse(cacheStrategy);
}
};
...
}
通过InternalCache这个接口实现了缓存的一系列操作,接着我们一步步看它是如何实现的,接下来分析缓存的get和put操作。
先看InternalCache的put方法,也就是存储缓存:
public final class Cache implements Closeable, Flushable {
final InternalCache internalCache = new InternalCache() {
...
@Override
public CacheRequest put(Response response) throws IOException {
return Cache.this.put(response);
}
...
};
...
}
InternalCache的put方法调用的是Cache的put方法,往下看:
@Nullable CacheRequest put(Response response) {
//标记1:获取请求方法
String requestMethod = response.request().method();
//标记2:判断缓存是否有效
if (HttpMethod.invalidatesCache(response.request().method())) {
try {
remove(response.request());
} catch (IOException ignored) {
}
return null;
}
//标记3:非GET请求不使用缓存
if (!requestMethod.equals("GET")) {
return null;
}
if (HttpHeaders.hasVaryAll(response)) {
return null;
}
//标记4:创建缓存体类
Cache.Entry entry = new Cache.Entry(response);
//标记5:使用DiskLruCache缓存策略
DiskLruCache.Editor editor = null;
try {
editor = cache.edit(key(response.request().url()));
if (editor == null) {
return null;
}
entry.writeTo(editor);
return new Cache.CacheRequestImpl(editor);
} catch (IOException e) {
abortQuietly(editor);
return null;
}
}
首先在标记1处获取我们的请求方式,接着在标记2处根据请求方式判断缓存是否有效,通过HttpMethod的静态方法invalidatesCache。
public static boolean invalidatesCache(String method) {
return method.equals("POST")
|| method.equals("PATCH")
|| method.equals("PUT")
|| method.equals("DELETE")
|| method.equals("MOVE"); // WebDAV
}
通过invalidatesCache方法,如果请求方式是POST、PATCH、PUT、DELETE以及MOVE中一个,就会将当前请求的缓存移除。
在标记3处会判断如果当前请求不是GET请求,就不会进行缓存。
在标记4处创建Entry对象,Entry的构造器如下:
Entry(Response response) {
this.url = response.request().url().toString();
this.varyHeaders = HttpHeaders.varyHeaders(response);
this.requestMethod = response.request().method();
this.protocol = response.protocol();
this.code = response.code();
this.message = response.message();
this.responseHeaders = response.headers();
this.handshake = response.handshake();
this.sentRequestMillis = response.sentRequestAtMillis();
this.receivedResponseMillis = response.receivedResponseAtMillis();
}
创建的Entry对象在内部会保存我们的请求url、头部、请求方式、协议、响应码等一系列参数。
在标记5处可以看到原来OkHttp的缓存策略使用的是DiskLruCache,DiskLruCache是用于磁盘缓存的一套解决框架,OkHttp对DiskLruCache稍微做了点修改,并且OkHttp内部维护着清理内存的线程池,通过这个线程池完成缓存的自动清理和管理工作,这里不做过多介绍。
拿到DiskLruCache的Editor对象后,通过它的edit方法创建缓存文件,edit方法传入的是缓存的文件名,通过key方法将请求url进行MD5加密并获取它的十六进制表示形式。
接着执行Entry对象的writeTo方法并传入Editor对象,writeTo方法的目的是将我们的缓存信息存储在本地。
点进writeTo方法:
public void writeTo(DiskLruCache.Editor editor) throws IOException {
BufferedSink sink = Okio.buffer(editor.newSink(ENTRY_METADATA));
//缓存URL
sink.writeUtf8(url)
.writeByte('\n');
//缓存请求方式
sink.writeUtf8(requestMethod)
.writeByte('\n');
//缓存头部
sink.writeDecimalLong(varyHeaders.size())
.writeByte('\n');
for (int i = 0, size = varyHeaders.size(); i < size; i++) {
sink.writeUtf8(varyHeaders.name(i))
.writeUtf8(": ")
.writeUtf8(varyHeaders.value(i))
.writeByte('\n');
}
//缓存协议,响应码,消息
sink.writeUtf8(new StatusLine(protocol, code, message).toString())
.writeByte('\n');
sink.writeDecimalLong(responseHeaders.size() + 2)
.writeByte('\n');
for (int i = 0, size = responseHeaders.size(); i < size; i++) {
sink.writeUtf8(responseHeaders.name(i))
.writeUtf8(": ")
.writeUtf8(responseHeaders.value(i))
.writeByte('\n');
}
//缓存时间
sink.writeUtf8(SENT_MILLIS)
.writeUtf8(": ")
.writeDecimalLong(sentRequestMillis)
.writeByte('\n');
sink.writeUtf8(RECEIVED_MILLIS)
.writeUtf8(": ")
.writeDecimalLong(receivedResponseMillis)
.writeByte('\n');
//判断https
if (isHttps()) {
sink.writeByte('\n');
sink.writeUtf8(handshake.cipherSuite().javaName())
.writeByte('\n');
writeCertList(sink, handshake.peerCertificates());
writeCertList(sink, handshake.localCertificates());
sink.writeUtf8(handshake.tlsVersion().javaName()).writeByte('\n');
}
sink.close();
}
writeTo方法内部对Response的相关信息进行缓存,并判断是否是https请求并缓存Https相关信息,从上面的writeTo方法中发现,返回的响应主体body并没有在这里进行缓存,最后返回一个CacheRequestImpl对象。
private final class CacheRequestImpl implements CacheRequest {
private final DiskLruCache.Editor editor;
private Sink cacheOut;
private Sink body;
boolean done;
CacheRequestImpl(final DiskLruCache.Editor editor) {
this.editor = editor;
this.cacheOut = editor.newSink(ENTRY_BODY);
this.body = new ForwardingSink(cacheOut) {
@Override public void close() throws IOException {
synchronized (Cache.this) {
if (done) {
return;
}
done = true;
writeSuccessCount++;
}
super.close();
editor.commit();
}
};
}
}
在CacheRequestImpl类中有一个body对象,这个就是我们的响应主体。CacheRequestImpl实现了CacheRequest接口,用于暴露给缓存拦截器,这样的话缓存拦截器就可以直接通过这个类来更新或写入缓存数据。
看完了put方法,继续看get方法:
public final class Cache implements Closeable, Flushable {
final InternalCache internalCache = new InternalCache() {
...
@Override public Response get(Request request) throws IOException {
return Cache.this.get(request);
}
...
};
...
}
查看Cache的get方法:
@Nullable Response get(Request request) {
//获取缓存的key
String key = key(request.url());
//创建快照
DiskLruCache.Snapshot snapshot;
Cache.Entry entry;
try {
//更加key从缓存获取
snapshot = cache.get(key);
if (snapshot == null) {
return null;
}
} catch (IOException e) {
return null;
}
try {
//从快照中获取缓存
entry = new Cache.Entry(snapshot.getSource(ENTRY_METADATA));
} catch (IOException e) {
Util.closeQuietly(snapshot);
return null;
}
Response response = entry.response(snapshot);
if (!entry.matches(request, response)) {
//响应和请求不是成对出现
Util.closeQuietly(response.body());
return null;
}
return response;
}
get方法比较简单,先是根据请求的url获取缓存key,创建snapshot目标缓存中的快照,根据key获取快照,当目标缓存中没有这个key对应的快照,说明没有缓存返回null;如果目标缓存中有这个key对应的快照,那么根据快照创建缓存Entry对象,再从Entry中取出Response。
Entry的response方法:
public Response response(DiskLruCache.Snapshot snapshot) {
String contentType = responseHeaders.get("Content-Type");
String contentLength = responseHeaders.get("Content-Length");
//根据头部信息创建缓存请求
Request cacheRequest = new Request.Builder()
.url(url)
.method(requestMethod, null)
.headers(varyHeaders)
.build();
//创建Response
return new Response.Builder()
.request(cacheRequest)
.protocol(protocol)
.code(code)
.message(message)
.headers(responseHeaders)
.body(new Cache.CacheResponseBody(snapshot, contentType, contentLength))
.handshake(handshake)
.sentRequestAtMillis(sentRequestMillis)
.receivedResponseAtMillis(receivedResponseMillis)
.build();
}
Entry的response方法中会根据头部信息创建缓存请求,然后创建Response对象并返回。
回到get方法,接着判断响应和请求是否成对出现,如果不是成对出现,关闭流并返回null,否则返回Response。
到这里缓存的get和put方法的整体流程已经介绍完毕,接下来介绍缓存拦截器。
CacheInterceptor
进入CacheInterceptor的intercept方法,下面贴出部分重要的代码。
@Override public Response intercept(Interceptor.Chain chain) throws IOException {
Response cacheCandidate = cache != null
? cache.get(chain.request())
: null;
...
}
第一步先尝试从缓存中获取Response,这里分两种情况,要么获取缓存Response,要么cacheCandidate为null。
@Override public Response intercept(Interceptor.Chain chain) throws IOException {
...
CacheStrategy strategy = new CacheStrategy.Factory(now, chain.request(), cacheCandidate).get();
Request networkRequest = strategy.networkRequest;
Response cacheResponse = strategy.cacheResponse;
...
}
第二步,获取缓存策略CacheStrategy对象,CacheStrategy内部维护了一个Request和一个Response,也就是说CacheStrategy能指定到底是通过网络还是缓存,亦或是两者同时使用获取Response。
CacheStrategy内部工厂类Factory的get方法如下:
public CacheStrategy get() {
CacheStrategy candidate = getCandidate();
if (candidate.networkRequest != null && request.cacheControl().onlyIfCached()) {
// We're forbidden from using the network and the cache is insufficient.
return new CacheStrategy(null, null);
}
return candidate;
}
方法中通过getCandidate方法获取CacheStrategy对象,继续点进去:
private CacheStrategy getCandidate() {
//标记1:没有缓存Response
if (cacheResponse == null) {
return new CacheStrategy(request, null);
}
//标记2
if (request.isHttps() && cacheResponse.handshake() == null) {
return new CacheStrategy(request, null);
}
...
CacheControl requestCaching = request.cacheControl();
//标记3
if (requestCaching.noCache() || hasConditions(request)) {
return new CacheStrategy(request, null);
}
CacheControl responseCaching = cacheResponse.cacheControl();
//标记4
if (responseCaching.immutable()) {
return new CacheStrategy(null, cacheResponse);
}
...
//标记5
if (!responseCaching.noCache() && ageMillis + minFreshMillis < freshMillis + maxStaleMillis) {
Response.Builder builder = cacheResponse.newBuilder();
if (ageMillis + minFreshMillis >= freshMillis) {
builder.addHeader("Warning", "110 HttpURLConnection \"Response is stale\"");
}
long oneDayMillis = 24 * 60 * 60 * 1000L;
if (ageMillis > oneDayMillis && isFreshnessLifetimeHeuristic()) {
builder.addHeader("Warning", "113 HttpURLConnection \"Heuristic expiration\"");
}
return new CacheStrategy(null, builder.build());
}
...
}
标记1处,可以看到先对cacheResponse进行判断,如果为空,说明没有缓存对象,这时创建CacheStrategy对象并且第二个参数Response传入null。
标记2处,判断请求是否是https请求,如果是https请求但没有经过握手操作 ,创建CacheStrategy对象并且第二个参数Response传入null。
标记3处,判断如果不使用缓存或者服务端资源改变,亦或者验证服务端发过来的最后修改的时间戳,同样创建CacheStrategy对象并且第二个参数Response传入null。
标记4处,判断缓存是否受影响,如果不受影响,创建CacheStrategy对象时,第一个参数Request为null,第二个参数Response直接使用cacheResponse。
标记5处,根据一些信息添加头部信息 ,最后创建CacheStrategy对象。
回到CacheInterceptor的intercept方法:
@Override public Response intercept(Chain chain) throws IOException {
...
if (networkRequest == null && cacheResponse == null) {
return new Response.Builder()
.request(chain.request())
.protocol(Protocol.HTTP_1_1)
.code(504)
.message("Unsatisfiable Request (only-if-cached)")
.body(Util.EMPTY_RESPONSE)
.sentRequestAtMillis(-1L)
.receivedResponseAtMillis(System.currentTimeMillis())
.build();
}
...
}
第三步,判断当前如果不能使用网络同时又没有找到缓存,这时会创建一个Response对象,code为504的错误。
@Override public Response intercept(Chain chain) throws IOException {
...
if (networkRequest == null) {
return cacheResponse.newBuilder()
.cacheResponse(stripBody(cacheResponse))
.build();
}
...
}
第四步,如果当前不能使用网络,就直接返回缓存结果。
@Override public Response intercept(Chain chain) throws IOException {
...
Response networkResponse = null;
try {
networkResponse = chain.proceed(networkRequest);
} finally {
...
}
...
}
第五步,调用下一个拦截器进行网络请求。
@Override public Response intercept(Chain chain) throws IOException {
...
if (cacheResponse != null) {
if (networkResponse.code() == HTTP_NOT_MODIFIED) {
Response response = cacheResponse.newBuilder()
.headers(combine(cacheResponse.headers(), networkResponse.headers()))
.sentRequestAtMillis(networkResponse.sentRequestAtMillis())
.receivedResponseAtMillis(networkResponse.receivedResponseAtMillis())
.cacheResponse(stripBody(cacheResponse))
.networkResponse(stripBody(networkResponse))
.build();
networkResponse.body().close();
cache.trackConditionalCacheHit();
cache.update(cacheResponse, response);
return response;
} else {
closeQuietly(cacheResponse.body());
}
}
...
}
第六步,当通过下个拦截器获取Response后,判断当前如果有缓存Response,并且网络返回的Response的响应码为304,代表从缓存中获取。
@Override public Response intercept(Chain chain) throws IOException {
...
if (cache != null) {
//标记1
if (HttpHeaders.hasBody(response) && CacheStrategy.isCacheable(response, networkRequest)) {
CacheRequest cacheRequest = cache.put(response);
return cacheWritingResponse(cacheRequest, response);
}
//标记2
if (HttpMethod.invalidatesCache(networkRequest.method())) {
try {
cache.remove(networkRequest);
} catch (IOException ignored) {
}
}
}
return response;
}
第七步,标记1判断http头部有没有响应体,并且缓存策略可以被缓存的,满足这两个条件后,网络获取的Response通过cache的put方法写入到缓存中,这样下次取的时候就可以从缓存中获取;标记2处判断请求方法是否是无效的请求方法,如果是的话,从缓存池中删除这个Request。最后返回Response给上一个拦截器。
ConnectInterceptor拦截器
ConnectInterceptor是网络连接拦截器,我们知道在OkHttp当中真正的网络请求都是通过拦截器链来实现的,通过依次执行这个拦截器链上不同功能的拦截器来完成数据的响应,ConnectInterceptor的作用就是打开与服务器之间的连接,正式开启OkHttp的网络请求。
走进ConnectInterceptor的intercept方法:
@Override public Response intercept(Interceptor.Chain chain) throws IOException {
RealInterceptorChain realChain = (RealInterceptorChain) chain;
Request request = realChain.request();
//标记1
StreamAllocation streamAllocation = realChain.streamAllocation();
...
}
在标记1处可以看到从上一个拦截器中获取StreamAllocation对象,在讲解第一个拦截器RetryAndFollowUpInterceptor重试重定向的时候已经介绍过StreamAllocation,在RetryAndFollowUpInterceptor中只是创建了这个对象并没有使用,真正使用它的是在ConnectInterceptor中,StreamAllocation是用来建立执行HTTP请求所需要的网络组件,既然我们拿到了StreamAllocation,接下来看这个StreamAllocation到底做了哪些操作。
@Override public Response intercept(Interceptor.Chain chain) throws IOException {
...
//标记1
StreamAllocation streamAllocation = realChain.streamAllocation();
..
//标记2
HttpCodec httpCodec = streamAllocation.newStream(client, chain, doExtensiveHealthChecks);
...
}
在标记2处通过StreamAllocation对象的newStream方法创建了一个HttpCodec对象,HttpCodec的作用是用来编码我们的Request以及解码我们的Response。
@Override public Response intercept(Interceptor.Chain chain) throws IOException {
...
//标记1
StreamAllocation streamAllocation = realChain.streamAllocation();
...
//标记2
HttpCodec httpCodec = streamAllocation.newStream(client, chain, doExtensiveHealthChecks);
//标记3
RealConnection connection = streamAllocation.connection();
...
}
在标记3处通过StreamAllocation对象的connection方法获取到RealConnection对象,这个RealConnection对象是用来进行实际的网络IO传输的。
@Override public Response intercept(Interceptor.Chain chain) throws IOException {
...
//标记1
StreamAllocation streamAllocation = realChain.streamAllocation();
...
//标记2
HttpCodec httpCodec = streamAllocation.newStream(client, chain, doExtensiveHealthChecks);
//标记3
RealConnection connection = streamAllocation.connection();
//标记4
return realChain.proceed(request, streamAllocation, httpCodec, connection);
}
标记4处是我们非常熟悉的代码了,继续调用拦截器链的下一个拦截器并将Request、StreamAllocation、HttpCodec以及RealConnection对象传递过去。
总结:
-
首先ConnectInterceptor拦截器从拦截器链获取到前面传递过来的StreamAllocation,接着执行StreamAllocation的newStream方法创建HttpCodec,HttpCodec对象是用于处理我们的Request和Response。
-
最后将刚才创建的用于网络IO的RealConnection对象,以及对于服务器交互最为关键的HttpCodec等对象传递给后面的拦截器。
从上面我们了解了ConnectInterceptor拦截器的intercept方法的整体流程,从前一个拦截器中获取StreamAllocation对象,通过StreamAllocation对象的newStream方法创建了一个HttpCodec对象,我们看看这个newStream方法具体做了哪些操作。
public HttpCodec newStream(
OkHttpClient client, Interceptor.Chain chain, boolean doExtensiveHealthChecks) {
...
try {
//标记1
RealConnection resultConnection = findHealthyConnection(connectTimeout, readTimeout,
writeTimeout, pingIntervalMillis, connectionRetryEnabled, doExtensiveHealthChecks);
HttpCodec resultCodec = resultConnection.newCodec(client, chain, this);
...
} catch (IOException e) {
throw new RouteException(e);
}
}
我们可以看到在标记1处创建了一个RealConnection对象,以及HttpCodec对象,这两个对象在上面已经介绍过了,RealConnection对象是用来进行实际的网络IO传输的,HttpCodec是用来编码我们的Request以及解码我们的Response。
通过findHealthyConnection方法生成一个RealConnection对象,来进行实际的网络连接。
findHealthyConnection方法:
private RealConnection findHealthyConnection(int connectTimeout, int readTimeout,
int writeTimeout, int pingIntervalMillis, boolean connectionRetryEnabled,
boolean doExtensiveHealthChecks) throws IOException {
while (true) {
RealConnection candidate = findConnection(connectTimeout, readTimeout, writeTimeout,
pingIntervalMillis, connectionRetryEnabled);
...
synchronized (connectionPool) {
if (candidate.successCount == 0) {
return candidate;
}
}
...
return candidate;
}
}
在方法中开启了while循环,内部的同步代码块中判断candidate的successCount如果等于0,说明整个网络连接结束并直接返回candidate,而这个candidate是通过同步代码块上面的findConnection方法获取的。
private RealConnection findHealthyConnection(int connectTimeout, int readTimeout,
int writeTimeout, int pingIntervalMillis, boolean connectionRetryEnabled,
boolean doExtensiveHealthChecks) throws IOException {
while (true) {
RealConnection candidate = findConnection(connectTimeout, readTimeout, writeTimeout,
pingIntervalMillis, connectionRetryEnabled);
synchronized (connectionPool) {
if (candidate.successCount == 0) {
return candidate;
}
}
//标记1
if (!candidate.isHealthy(doExtensiveHealthChecks)) {
noNewStreams();
continue;
}
return candidate;
}
}
往下看标记1,这边会判断这个连接是否健康(比如Socket没有关闭、或者它的输入输出流没有关闭等等),如果不健康就调用noNewStreams方法从连接池中取出并销毁,接着调用continue,继续循环调用findConnection方法获取RealConnection对象。
通过不停的循环调用findConnection方法来获取RealConnection对象,接着看这个findConnection方法做了哪些操作。
private RealConnection findConnection(int connectTimeout, int readTimeout, int writeTimeout,
int pingIntervalMillis, boolean connectionRetryEnabled) throws IOException {
...
RealConnection result = null;
Connection releasedConnection;
...
synchronized (connectionPool) {
...
//标记1
releasedConnection = this.connection;
...
if (this.connection != null) {
result = this.connection;
releasedConnection = null;
}
...
}
...
return result;
}
在findConnection方法的标记1处,尝试将connection赋值给releasedConnection,然后判断这个connection能不能复用,如果能复用,就将connection赋值给result,最后返回这个复用的连接。如果不能复用,那么result就为null,我们继续往下看。
private RealConnection findConnection(int connectTimeout, int readTimeout, int writeTimeout,
int pingIntervalMillis, boolean connectionRetryEnabled) throws IOException {
...
RealConnection result = null;
Connection releasedConnection;
...
synchronized (connectionPool) {
...
//标记1
...
//标记2
if (result == null) {
Internal.instance.get(connectionPool, address, this, null);
if (connection != null) {
foundPooledConnection = true;
result = connection;
} else {
selectedRoute = route;
}
}
...
}
...
return result;
}
如果result为null说明不能复用这个connection,那么就从连接池connectionPool中获取一个实际的RealConnection并赋值给connection,接着判断connection是否为空,不为空赋值给result。
private RealConnection findConnection(int connectTimeout, int readTimeout, int writeTimeout,
int pingIntervalMillis, boolean connectionRetryEnabled) throws IOException {
...
RealConnection result = null;
Connection releasedConnection;
...
synchronized (connectionPool) {
...
//标记1
...
//标记2
if (result == null) {
Internal.instance.get(connectionPool, address, this, null);
if (connection != null) {
foundPooledConnection = true;
result = connection;
} else {
selectedRoute = route;
}
}
...
}
...
//标记3
result.connect(connectTimeout, readTimeout, writeTimeout, pingIntervalMillis,
connectionRetryEnabled, call, eventListener);
...
return result;
}
标记3处,拿到我们的RealConnection对象result之后,调用它的connect方法来进行实际的网络连接。
private RealConnection findConnection(int connectTimeout, int readTimeout, int writeTimeout,
int pingIntervalMillis, boolean connectionRetryEnabled) throws IOException {
...
RealConnection result = null;
Connection releasedConnection;
...
synchronized (connectionPool) {
...
//标记1
...
//标记2
if (result == null) {
Internal.instance.get(connectionPool, address, this, null);
if (connection != null) {
foundPooledConnection = true;
result = connection;
} else {
selectedRoute = route;
}
}
...
}
...
//标记3
result.connect(connectTimeout, readTimeout, writeTimeout, pingIntervalMillis,
connectionRetryEnabled, call, eventListener);
...
//标记4
Internal.instance.put(connectionPool, result);
...
return result;
}
在标记4处,进行真正的网络连接后,将连接成功后的RealConnection对象result放入connectionPool连接池,方便后面复用。
上面我们介绍了StreamAllocation对象的newStream方法的具体操作,接下来看看ConnectInterceptor拦截器中一个很重要的概念-连接池。
不管HTTP协议是1.1还是2.0,它们的Keep-Alive机制,或者2.0的多路复用机制在实现上都需要引入一个连接池的概念,来维护整个网络连接。OkHttp中将客户端与服务端之间的链接抽象成一个Connection类,而RealConnection是它的实现类,为了管理所有的Connection,OkHttp提供了一个ConnectionPool这个类,它的主要作用就是在时间范围内复用Connection。
接下来主要介绍它的get和put方法。
@Nullable RealConnection get(Address address, StreamAllocation streamAllocation, Route route) {
assert (Thread.holdsLock(this));
for (RealConnection connection : connections) {
if (connection.isEligible(address, route)) {
streamAllocation.acquire(connection, true);
return connection;
}
}
return null;
}
在get方法中遍历连接池中的Connection,通过isEligible方法判断Connection是否可用,如果可以使用就会调用streamAllocation的acquire方法来获取所用的连接。
进入StreamAllocation的acquire方法:
public void acquire(RealConnection connection, boolean reportedAcquired) {
assert (Thread.holdsLock(connectionPool));
if (this.connection != null) throw new IllegalStateException();
//标记1
this.connection = connection;
this.reportedAcquired = reportedAcquired;
//标记2
connection.allocations.add(new StreamAllocationReference(this, callStackTrace));
}
标记1处,从连接池中获取的RealConnection对象赋值给StreamAllocation的成员变量connection。
标记2处,将StreamAllocation对象的弱引用添加到RealConnection的allocations集合中去,这样做的用处是通过allocations集合的大小来判断网络连接次数是否超过OkHttp指定的连接次数。
put方法:
void put(RealConnection connection) {
assert (Thread.holdsLock(this));
if (!cleanupRunning) {
cleanupRunning = true;
executor.execute(cleanupRunnable);
}
connections.add(connection);
}
put方法中在添加连接到连接池之前,会处理清理任务,做完清理任务后,将我们的connection添加到连接池中。
connection自动回收l利用了GC的回收算法,当StreamAllocation数量为0时,会被线程池检测到,然后进行回收,在ConnectionPool中有一个独立的线程,它会开启cleanupRunnable来清理连接池。
private final Runnable cleanupRunnable = new Runnable() {
@Override public void run() {
while (true) {
//标记1
long waitNanos = cleanup(System.nanoTime());
if (waitNanos == -1) return;
if (waitNanos > 0) {
long waitMillis = waitNanos / 1000000L;
waitNanos -= (waitMillis * 1000000L);
synchronized (ConnectionPool.this) {
try {
//标记2
ConnectionPool.this.wait(waitMillis, (int) waitNanos);
} catch (InterruptedException ignored) {
}
}
}
}
}
};
在run方法中是一个死循环,内部标记1处首次进行清理时,需要返回下次清理的间隔时间。标记2处调用了wait方法进行等待,等待释放锁和时间片,当等待时间过了之后会再次调用Runnable进行清理,同时返回下次要清理的间隔时间waitNanos。
标记2处的cleanup方法内部实现了具体的GC回收算法,该算法类似Java GC当中的标记清除算法;cleanup方法循环标记出最不活跃的connection,通过响应的判断来进行清理。
CallServerInterceptor拦截器
CallServerInterceptor拦截器主要作用是负责向服务器发起真正的网络请求,并获取返回结果。
CallServerInterceptor的intercept方法:
@Override public Response intercept(Chain chain) throws IOException {
RealInterceptorChain realChain = (RealInterceptorChain) chain;
HttpCodec httpCodec = realChain.httpStream();
StreamAllocation streamAllocation = realChain.streamAllocation();
RealConnection connection = (RealConnection) realChain.connection();
Request request = realChain.request();
...
}
intercept方法中先是获取五个对象,下面分别介绍这5个对象的含义。
RealInterceptorChain:拦截器链,真正进行请求的地方。
HttpCodec:在OkHttp中,它把所有的流对象都封装成了HttpCodec这个类,作用是编码Request,解码Response。
StreamAllocation:建立HTTP连接所需要的网络组件。
RealConnection:服务器与客户端的具体连接。
Request:网络请求。
@Override public Response intercept(Chain chain) throws IOException {
RealInterceptorChain realChain = (RealInterceptorChain) chain;
HttpCodec httpCodec = realChain.httpStream();
StreamAllocation streamAllocation = realChain.streamAllocation();
RealConnection connection = (RealConnection) realChain.connection();
Request request = realChain.request();
...
//标记1
httpCodec.finishRequest();
...
}
标记1处,调用httpCodec的finishRequest方法,表面网络请求的写入工作已经完成,具体网络请求的写入工作大家可以看源码,也就是标记1之上的代码。
网络请求的写入工作完成后,接下来就进行网络请求的读取工作。
@Override public Response intercept(Chain chain) throws IOException {
RealInterceptorChain realChain = (RealInterceptorChain) chain;
HttpCodec httpCodec = realChain.httpStream();
StreamAllocation streamAllocation = realChain.streamAllocation();
RealConnection connection = (RealConnection) realChain.connection();
Request request = realChain.request();
...
//网络请求一系列写入工作
...
//向socket当中写入请求的body信息
request.body().writeTo(bufferedRequestBody);
...
//标记1:写入结束
httpCodec.finishRequest();
...
if (responseBuilder == null) {
realChain.eventListener().responseHeadersStart(realChain.call());
//读取网络写入的头部信息
responseBuilder = httpCodec.readResponseHeaders(false);
}
Response response = responseBuilder
.request(request)
.handshake(streamAllocation.connection().handshake())
.sentRequestAtMillis(sentRequestMillis)
.receivedResponseAtMillis(System.currentTimeMillis())
.build();
...
//读取Response
//标记1
response = response.newBuilder()
.body(httpCodec.openResponseBody(response))
.build();
...
return response;
}
我们只取核心代码标记1,通过httpCodec的openResponseBody方法获取body,并通过build创建Response对象,最终返回Response对象。
到这里OkHttp的同步和异步请求、分发器,以及五个拦截器都已经介绍一边了,怎么说呢,OkHttp的源码实在太庞大了,要想全部理解需要花费很长时间,我只是整理出了OkHttp中几个比较重要的概念,了解它的整体脉络,这样你才能有条理的分析它的源码。