使用Python+jieba和java+庖丁分词在Spark集群上进行中文分词统计
写在前边的话:
本篇博客也是在做豆瓣电影数据的分析过程中,需要对影评信息和剧情摘要信息进行分析而写的一篇博客
以前学习hadoop时,感觉做中文分词也没那么麻烦,但是到了Spark,却碰到了诸多困难,但幸好最终都解决了这些问题,而得到了正确的结果,这里我们不解释具体的spark语法之类的,着重于解决中文分词统计这个问题
同步github地址:点击查看
1:Python+jieba
使用python版本的spark,首先想到的便是jieba分词,这里结合python的jieba分词和Spark对文件内容进行分词和词频统计,使用的样例数据依旧豆瓣电影的影评数据,这里只是采用了大鱼海棠的影评信息进行分词。
数据样例的格式如下:
26051523 根据真实事件改编,影片聚焦1973年智利政变时期,一对年轻的德国夫妇丹尼尔与莱娜反抗智利军政府统领、独裁者皮诺切特的故事。当时正值智利政变的高潮期,丹尼尔被皮诺切特的手下绑架到一个被称为“尊严殖民地”的秘密基地。那儿正是前德国纳粹分子逃亡智利所建的聚集地,而军政府武装进行着大量的刑讯工作与秘密人体实验,被绑架的人从来没有一个曾活着逃出“殖民地”。然而丹尼尔的妻子莱娜没有放弃,她找到了基地所在,并计划救出丈夫。
需要注意的是:如果去掉下面函数中的combine函数,则正常保存统计结果,显示的形式大致是这样的
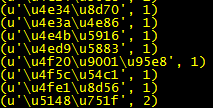
而这里的combine函数就是为了解决这个问题,最终的统计结果为

#-*-coding:utf-8-*-
from pyspark import SparkConf, SparkContext
import jieba
def split(line):
word_list = jieba.cut(line.strip().split("\t")[1]) #进行中文分词
ls =[]
for word in word_list:
if len(word)>1: #过滤掉单音节词
ls.append(word)
return ls
def combine(line): #去除保存结果中的括号和解=解决中文编码显示的问题
result = ""
result +=line[0]+"\t"+str(line[1]) #让数字在前,方便统计
return result
def main(sc):
text = sc.textFile("/file/douban_movie_data/movie_summary.txt")
word_list = text.map(split).collect() #保存为列表
count = sc.parallelize(word_list[0]) #返回列表中的第一个元素
results = count.map(lambda w:(w,1)).reduceByKey(lambda x,y:x+y).map(combine).sortByKey().saveAsTextFile("/file/douban_movie_data/result")
print "succeed"
if __name__=="__main__":
conf = SparkConf().setAppName("wordSplit")
conf.setMaster("local")
sc= SparkContext(conf = conf)
main(sc)2:Java+Scala+庖丁分词
网上搜了一遍,有使用ansj分词的,但是瞄了一遍,不懂,于是还是回归到了庖丁分词,整体的程序分为两部分,一个是java+庖丁分词程序,一个是scala提交spark的统计程序,具体代码和解释如下
至于如何使用Idea+Spark构建开发环境请移步:点击阅读
庖丁分词等中文分词比较请移步:点击阅读
这里需要注意的是:庖丁分词的字典库的配置问题(下图红线所示),正常情况下,程序打成jar包在spark集群上运行会报出各种错误,但主要是两个方面,一个是spark集群的内存问题(我用的是自己电脑的虚拟机,视具体配置而定),二是字典库的路径问题,我这里是把dic放在集群上每台机器的一个指定的相同的目录,同时把jar包在放在集群上的每台机器上

tokens.java
import java.io.IOException;
import java.io.StringReader;
import java.util.ArrayList;
import java.util.List;
import net.paoding.analysis.analyzer.PaodingAnalyzer;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.Token;
import org.apache.lucene.analysis.TokenStream;
public class tokens {
public static List anaylyzerWords (String str){
// TODO Auto-generated method stub
//定义一个解析器
Analyzer analyzer = new PaodingAnalyzer();
//定义一个存放存词的列表
List list=new ArrayList();
//得到token序列的输出流
TokenStream tokens = analyzer.tokenStream(str, new StringReader(str));
try{
Token t;
while((t=tokens.next() ) !=null){
list.add(t.termText());
}
}catch(IOException e){
e.printStackTrace();
}
return list;
}
public static void main(String[] args){
String text = "本思想就是在分词的同时进行句法、语义分析, 利用句法信息和语义信息来进行词性标注, " +
"以解决分词歧义现象。因为现有的语法知识、句法规则十分笼统、复杂, 基于语法和规则的分词" +
"法所能达到的精确度远远还不能令人满意, 目前这种分词系统还处在试验阶段。";
List list=tokens.anaylyzerWords(text);
for(String s:list){
System.out.println(s);
}
}
} import org.apache.spark._
/**
* Created by gaoyt on 2016/8/11.
*/
object Analyzer {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("my app").setMaster("spark://192.168.48.130:7077")
val sc = new SparkContext(conf)
val outputPath = "/file/douban_movie_data/summary"
sc.addJar("/home/master/SparkApp/WordAnalyzer.jar")
sc.textFile("/file/douban_movie_data/movie_summary.txt").map(x => {
val list=tokens.anaylyzerWords(x)
list.toString.replace("[", "").replace("]", "").split(",")
}).flatMap(x => x.toList).map(x => (x.trim(),1)).reduceByKey(_+_).saveAsTextFile(outputPath)
}
}最终的运行结果如下:

执行查看命令
/opt/hadoop/bin/hdfs dfs -cat /file/douban_movie_data/summary/part-00001