为什么稀疏自编码器很少见到多层的?
Andrew Ng 的视频和资料也好,还是网上的资料和代码,以及书上的内容,我很少见到稀疏自编码器是多层的结构一般都是{N,m,N}的三层结构(一层是隐层,输入输出各一层)为什么很少见到例如{N,m,k,m,N}这种5层的结构的Auto Encoder?是没有必要吗?还是有别的原因(比如破坏稀疏性)?
自从Hinton 2006年的工作之后,越来越多的研究者开始关注各种自编码器模型相应的堆叠模型。实际上,自编码器(Auto-Encoder)是一个较早的概念了,比如Hinton等人在1986, 1989年的工作。(说来说去都是这些人呐。。。)
自编码器简介
先暂且不谈神经网络、深度学习,仅是自编码器的话,其原理很简单。自编码器可以理解为一个试图去还原其原始输入的系统。如下图所示。

图中,虚线蓝色框内就是一个自编码器模型,它由编码器(Encoder)和解码器(Decoder)两部分组成,本质上都是对输入信号做某种变换。编码器将输入信号x变换成编码信号y,而解码器将编码y转换成输出信号。即
y=f(x)
=g(y)=g(f(x))
而自编码器的目的是,让输出尽可能复现输入x,即tries to copy its input to its output。但是,这样问题就来了——如果f和g都是恒等映射,那不就恒有=x了?不错,确实如此,但这样的变换——没有任何卵用啊!因此,我们经常对中间信号y(也叫作“编码”)做一定的约束,这样,系统往往能学出很有趣的编码变换f和编码y。
这里强调一点,对于自编码器,我们往往并不关系输出是啥(反正只是复现输入),我们真正关心的是中间层的编码,或者说是从输入到编码的映射。可以这么想,在我们强迫编码y和输入x不同的情况下,系统还能够去复原原始信号x,那么说明编码y已经承载了原始数据的所有信息,但以一种不同的形式!这就是特征提取啊,而且是自动学出来的!实际上,自动学习原始数据的特征表达也是神经网络和深度学习的核心目的之一。
为了更好的理解自编码器,下面结合神经网络加以介绍。
自编码器与神经网络
神经网络的知识不再详细介绍,相信了解自编码器的读者或多或少会了解一些。简单来讲,神经网络就是在对原始信号逐层地做非线性变换,如下图所示。
该网络把输入层数据x∈Rn转换到中间层(隐层)h∈Rp,再转换到输出层y∈Rm。图中的每个节点代表数据的一个维度(偏置项图中未标出)。每两层之间的变换都是“线性变化”+“非线性激活”,用公式表示即为
h=f(W(1)x+b(1))
y=f(W(2)h+b(2))
神经网络往往用于分类,其目的是去逼近从输入层到输出层的变换函数。因此,我们会定义一个目标函数来衡量当前的输出和真实结果的差异,利用该函数去逐步调整(如梯度下降)系统的参数(W(1),b(1),W(2),b(2)),以使得整个网络尽可能去拟合训练数据。如果有正则约束的话,还同时要求模型尽量简单(防止过拟合)。
那么,自编码器怎么表示呢?前面已说过,自编码器试图复现其原始输入,因此,在训练中,网络中的输出应与输入相同,即y=x,因此,一个自编码器的输入、输出应有相同的结构,即
我们利用训练数据训练这个网络,等训练结束后,这个网络即学习出了x→h→x的能力。对我们来说,此时的h是至关重要的,因为它是在尽量不损失信息量的情况下,对原始数据的另一种表达。结合神经网络的惯例,我们再将自编码器的公式表示如下:(假设激活函数是sigmoid,用s表示)
y=fθ(x)=s(Wx+b)
=gθ′(y)=s(W′y+b′)
L(x, )=L(x,g(f(x)))
其中,L表示损失函数,结合数据的不同形式,可以是二次误差(squared error loss)或交叉熵误差(cross entropy loss)。如果,一般称为tied weights。
为了尽量学到有意义的表达,我们会给隐层加入一定的约束。从数据维度来看,常见以下两种情况:
- n>p,即隐层维度小于输入数据维度。也就是说从x→h的变换是一种降维的操作,网络试图以更小的维度去描述原始数据而尽量不损失数据信息。实际上,当每两层之间的变换均为线性,且监督训练的误差是二次型误差时,该网络等价于PCA!没反应过来的童鞋可以反思下PCA是在做什么事情。
- n
堆叠自编码器
有过深度学习基础的童鞋想必了解,深层网络的威力在于其能够逐层地学习原始数据的多种表达。每一层的都以底一层的表达为基础,但往往更抽象,更加适合复杂的分类等任务。
堆叠自编码器实际上就在做这样的事情,如前所述,单个自编码器通过虚构x→h→x的三层网络,能够学习出一种特征变化h=fθ(x)(这里用θ表示变换的参数,包括W,b和激活函数)。实际上,当训练结束后,输出层已经没什么意义了,我们一般将其去掉,即将自编码器表示为
之前之所以将自编码器模型表示为3层的神经网络,那是因为训练的需要,我们将原始数据作为假想的目标输出,以此构建监督误差来训练整个网络。等训练结束后,输出层就可以去掉了,我们关心的只是从x到h的变换。
接下来的思路就很自然了——我们已经得到特征表达h,那么我们可不可以将
h再当做原始信息,训练一个新的自编码器,得到新的特征表达呢?当然可以!这就是所谓的堆叠自编码器(Stacked Auto-Encoder, SAE)。Stacked就是逐层垒叠的意思,跟“栈”有点像。UFLDL教程将其翻译为“栈式自编码”,anyway,不管怎么称呼,都是这个东东,别被花里胡哨的专业术语吓到就行。当把多个自编码器Stack起来之后,这个系统看起来就像这样:
亦可赛艇!这个系统实际上已经有点深度学习的味道了,即learning multiple levels of representation and abstraction(Hinton, Bengio, LeCun, 2015)。需要注意的是,整个网络的训练不是一蹴而就的,而是逐层进行。按题主提到的结构n,m,k结构,实际上我们是先训练网络n→m→n,得到n→m的变换,然后再训练m→k→m,得到m→k的变换。最终堆叠成SAE,即为n→m→k的结果,整个过程就像一层层往上盖房子,这便是大名鼎鼎的layer-wise unsuperwised pre-training(逐层非监督预训练),正是导致深度学习(神经网络)在2006年第3次兴起的核心技术。
关于逐层预训练与深度学习,将在本文最后探讨。
自编码器的变种形式
上述介绍的自编码器是最基本的形式。善于思考的童鞋可能已经意识到了这个问题:隐层的维度到底怎么确定?为什么稀疏的特征比较好?或者更准确的说,怎么才能称得上是一个好的表达(What defines a good representation)?
事实上,这个问题回答并不唯一,也正是从不同的角度去思考这个问题,导致了自编码器的各种变种形式出现。目前常见的几种模型总结如下(有些术语实在不好翻译,看英文就好。。。)
下面简介下其中两种模型,以对这些变种模型有个直观感受。
稀疏自编码器
UFLDL-自编码算法与稀疏性对该模型有着比较详细的介绍。如前所示,这种模型背后的思想是,高维而稀疏的表达是好的。一般而言,我们不会指定隐层表达h中哪些节点是被抑制的(对于sigmoid单元即输出为0),而是指定一个稀疏性参数ρ,代表隐藏神经元的平均活跃程度(在训练集上取平均)。比如,当ρ=0.05时,可以认为隐层节点在95%的时间里都是被一直的,只有5%的机会被激活。实际上,为了满足这一条件,隐层神经元的活跃度需要接近于0。
那么,怎么从数学模型上做到这点呢?思路也不复杂,既然要求平均激活度为ρ,那么只要引入一个度量,来衡量神经元ii的实际激活度与期望激活度ρ之间的差异即可,然后将这个度量添加到目标函数作为正则,训练整个网络即可。那么,什么样的度量适合这个任务呢?有过概率论、信息论基础的同学应该很容易想到它——相对熵,也就是KL散度(KL divergence)。因此,整个网络所添加的惩罚项即为
具体的公式不再展开,可以从下图(摘自UFLDL)中直观理解KL散度作为惩罚项的含义。图中假设平均激活度ρ=0.2。
可以看出,当^ρiρ^i一旦偏离期望激活度ρρ,这种误差便急剧增大,从而作为惩罚项添加到目标函数,指导整个网络学习出稀疏的特征表达。
降噪自编码器
关于降噪自编码器,强烈推荐其作者Pascal Vincent的论文Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion。DAE的核心思想是,一个能够从中恢复出原始信号的表达未必是最好的,能够对“被污染/破坏”的原始数据编码、解码,然后还能恢复真正的原始数据,这样的特征才是好的。
稍微数学一点,假设原始数据x被我们“故意破坏”,比如加入高斯白噪,或者把某些维度数据抹掉,变成了,然后再对编码、解码,得到恢复信号,该恢复信号尽可能逼近未被污染的数据xx。此时,监督训练的误差从L(x,g(f(x)))变成了L(x,g(f()))。
直观上理解,DAE希望学到的特征变换尽可能鲁棒,能够在一定程度上对抗原始数据的污染、缺失。Vincent论文里也对DAE提出了基于流行的解释,并且在图像数据上进行测试,发现DAE能够学出类似Gabor边缘提取的特征变换。注意,这一切都是在我们定义好规则、误差后,系统自动学出来的!从而避免了领域专家费尽心力去设计这些性能良好的特征。
DAE的系统结构如下图(摘自Vincent论文)所示。
现在使用比较多的noise主要是mask noise,即原始数据中部分数据缺失,这是有着很强的实际意义的,比如图像部分像素被遮挡、文本因记录原因漏掉了一些单词等等。
其他的模型就不再展开了,总之,每遇到一个自编码器的一个变种模型时,搞清楚其背后的思想(什么样的表达才是好的),就很容易掌握了。套用V的”Behind this mask is a man, and behind this man is an idea, and ideas are bulletproof”,我们可以说,”Behind this auto-encoder is a model, and behind this model is an idea, and ideas are bulletproof”。
关于预训练与深度学习
深度学习第3次兴起正式因为逐层预训练方法的提出,使得深度网络的训练成为可能。对于一个深度网络,这种逐层预训练的方法,正是前面介绍的这种Stacked Auto-Encoder。对于常见的分类任务,一般分为以下两个阶段:
- layer-wise pre-training (逐层预训练)
- fune-tuning (微调)
注意到,前述的各种SAE,本质上都是非监督学习,SAE各层的输出都是原始数据的不同表达。对于分类任务,往往在SAE顶端再添加一分类层(如Softmax层),并结合有标注的训练数据,在误差函数的指导下,对系统的参数进行微调,以使得整个网络能够完成所需的分类任务。
对于微调过程,即可以只调整分类层的参数(此时相当于把整个SAE当做一个feature extractor),也可以调整整个网络的参数(适合训练数据量比较大的情况)。
题主提到,为什么训练稀疏自编码器为什么一般都是3层的结构,实际上这里的3层是指训练单个自编码器所假想的3层神经网络,这对任何基于神经网络的编码器都是如此。多层的稀疏自编码器自然是有的,只不过是通过layer-wise pre-training这种方式逐层垒叠起来的,而不是直接去训练一个5层或是更多层的网络。
为什么要这样?实际上,这正是在训练深层神经网络中遇到的问题。直接去训练一个深层的自编码器,其实本质上就是在做深度网络的训练,由于梯度扩散等问题,这样的网络往往根本无法训练。这倒不是因为会破坏稀疏性等原因,只要网络能够训练,对模型施加的约束总能得到相应的结果。
但为什么逐层预训练就可以使得深度网络的训练成为可能了呢?有不少文章也做过这方面的研究。一个直观的解释是,预训练好的网络在一定程度上拟合了训练数据的结构,这使得整个网络的初始值是在一个合适的状态,便于有监督阶段加快迭代收敛。
笔者曾经基于 MNIST数据集,尝试了一个9层的网络完成分类任务。当随机初始化时,误差传到底层几乎全为0,根本无法训练。但采用逐层预训练的方法,训练好每两层之间的自编码变换,将其参数作为系统初始值,然后网络在有监督阶段就能比较稳定的迭代了。
当然,有不少研究提出了很好的初始化策略,再加上现在常用的dropout、ReLU,直接去训练一个深层网络已经不是问题。这是否意味着这种逐层预训练的方式已经过时了呢?这里,我想采用下Bengio先生2015年的一段话作为回答:
Stacks of unsupervised feature learning layers are STILL useful when you are in a regime with insufficient labeled examples, for transfer learning or domain adaptation. It is a regularizer. But when the number of labeled examples becomes large enough, the advantage of that regularizer becomes much less. I suspect however that this story is far from ended! There are other ways besides pre-training of combining supervised and unsupervised learning, and I believe that we still have a lot to improve in terms of our unsupervised learning algorithms.
最后,多说一句,除了AE和SAE这种逐层预训练的方式外,还有另外一条类似的主线,即限制玻尔兹曼机(RBM)与深度信念网络(DBN)。这些模型在神经网络/深度学习框架中的位置,可以简要总结为下图。
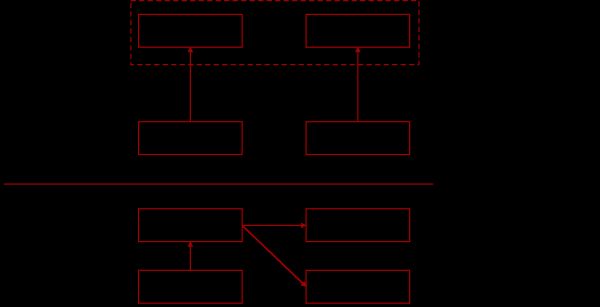
订正:感谢@Detective 夏恩指正,RBM堆叠起来是Deep Boltzmann Machines, 再加一个分类器才是DBN,供阅读上图时参考。
相关学习资料推荐
- Sranford UFLDL教程 旧版有中文版作为参考
- Deep Learning Tutorial (Theano) 其中有关于AE、DAE、SDAE基于Theano的实现
- DeepLearnToolbox 该Toolbox基于Matlab实现,其中有SAE、CAE的实现
- 相关论文
- Hinton, G.E. and R.R. Salakhutdinov, Reducing the dimensionality of data with neural networks. Science, 2006. 313(5786): p. 504-507.
- Learning multiple layers of representation. Trends in cognitive sciences, 2007. 11(10): p. 428-434.
- Vincent, P., et al. Extracting and composing robust features with denoising autoencoders. in Proceedings of the 25th international conference on Machine learning. 2008.
- Bengio, Y., Learning deep architectures for AI. Foundations and trends? in Machine Learning, 2009. 2(1): p. 1-127.
- Vincent, P., et al., Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion. Journal of Machine Learning Research, 2010. 11(6): p.3371-3408.
- Rifai, S., et al., Contractive Auto-Encoders: Explicit Invariance During Feature Extraction. Icml, 2011.
- Chen, M., et al., Marginalized denoising autoencoders for domain adaptation. arXiv preprint arXiv:1206.4683, 2012.
- Bengio, Y., A. Courville and P. Vincent, Representation learning: A review and new perspectives. Pattern Analysis and Machine Intelligence, IEEE Transactions on, 2013. 35(8): p. 1798-1828.
- LeCun, Y., Y. Bengio and G. Hinton, Deep learning. Nature, 2015. 521(7553): p. 436-444.
【非常高兴看到大家喜欢并赞同我们的回答。应许多知友的建议,最近我们开通了同名公众号: PhDer,也会定期更新我们的文章,如果您不想错过我们的每篇回答,欢迎扫码关注~ 】
http://weixin.qq.com/r/5zsuNoHEZdwarcVV9271 (二维码自动识别)
from: https://www.zhihu.com/question/41490383#answer-36659160