Spark读取mongoDB数据写入Hive普通表和分区表
版本:
spark 2.2.0
hive 1.1.0
scala 2.11.8
hadoop-2.6.0-cdh5.7.0
jdk 1.8
MongoDB 3.6.4
一 原始数据及Hive表
MongoDB数据格式
{
"_id" : ObjectId("5af65d86222b639e0c2212f3"),
"id" : "1",
"name" : "lisi",
"age" : "18",
"deptno" : "01"
}Hive普通表
create table mg_hive_test(
id string,
name string,
age string,
deptno string
)row format delimited fields terminated by '\t';Hive分区表
create table mg_hive_external(
id string,
name string,
age string
)
partitioned by (deptno string)
row format delimited fields terminated by '\t';二 IDEA+Maven+Java
依赖
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_2.11artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-hive_2.11artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.mongodbgroupId>
<artifactId>mongo-java-driverartifactId>
<version>3.6.3version>
dependency>
<dependency>
<groupId>org.mongodb.sparkgroupId>
<artifactId>mongo-spark-connector_2.11artifactId>
<version>2.2.2version>
dependency>代码
package com.huawei.mongo;/*
* @Author: Create by Achun
*@Time: 2018/6/2 21:00
*
*/
import com.mongodb.spark.MongoSpark;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.hive.HiveContext;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
import org.bson.Document;
import java.io.File;
import java.util.ArrayList;
import java.util.List;
public class sparkreadmgtohive {
public static void main(String[] args) {
//spark 2.x
String warehouseLocation = new File("spark-warehouse").getAbsolutePath();
SparkSession spark = SparkSession.builder()
.master("local[2]")
.appName("SparkReadMgToHive")
.config("spark.sql.warehouse.dir", warehouseLocation)
.config("spark.mongodb.input.uri", "mongodb://127.0.0.1:27017/test.mgtest")
.enableHiveSupport()
.getOrCreate();
JavaSparkContext sc = new JavaSparkContext(spark.sparkContext());
//spark 1.x
// JavaSparkContext sc = new JavaSparkContext(conf);
// sc.addJar("/Users/mac/zhangchun/jar/mongo-spark-connector_2.11-2.2.2.jar");
// sc.addJar("/Users/mac/zhangchun/jar/mongo-java-driver-3.6.3.jar");
// SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("SparkReadMgToHive");
// conf.set("spark.mongodb.input.uri", "mongodb://127.0.0.1:27017/test.mgtest");
// conf.set("spark. serializer","org.apache.spark.serializer.KryoSerialzier");
// HiveContext sqlContext = new HiveContext(sc);
// //create df from mongo
// Dataset df = MongoSpark.read(sqlContext).load().toDF();
// df.select("id","name","name").show();
String querysql= "select id,name,age,deptno,DateTime,Job from mgtable b";
String opType ="P";
SQLUtils sqlUtils = new SQLUtils();
List column = sqlUtils.getColumns(querysql);
//create rdd from mongo
JavaRDD rdd = MongoSpark.load(sc);
//将Document转成Object
JavaRDD
工具类
package com.huawei.mongo;/*
* @Author: Create by Achun
*@Time: 2018/6/3 23:20
*
*/
import java.util.ArrayList;
import java.util.List;
public class SQLUtils {
public List<String> getColumns(String querysql){
List<String> column = new ArrayList<String>();
String tmp = querysql.substring(querysql.indexOf("select") + 6,
querysql.indexOf("from")).trim();
if (tmp.indexOf("*") == -1){
String cols[] = tmp.split(",");
for (String c:cols){
column.add(c);
}
}
return column;
}
public String getTBname(String querysql){
String tmp = querysql.substring(querysql.indexOf("from")+4).trim();
int sx = tmp.indexOf(" ");
if(sx == -1){
return tmp;
}else {
return tmp.substring(0,sx);
}
}
}
三 错误解决办法
1 IDEA会获取不到Hive的数据库和表,将hive-site.xml放入resources文件中。并且将resources设置成配置文件(设置成功文件夹是蓝色否则是灰色)
file–>Project Structure–>Modules–>Source
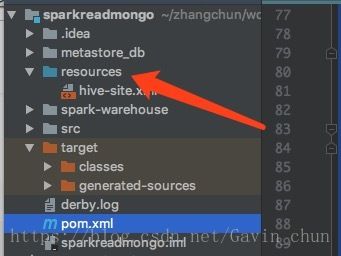
2 上面错误处理完后如果报JDO类型的错误,那么检查HIVE_HOME/lib下时候否mysql驱动,如果确定有,那么就是IDEA获取不到。解决方法如下:
- 将mysql驱动拷贝到jdk1.8.0_171.jdk/Contents/Home/jre/lib/ext路径下(jdk/jre/lib/ext)
- 在IDEA项目External Libraries下的<1.8>里面添加mysql驱动

四 注意点
由于将MongoDB数据表注册成了临时表和Hive表进行了关联,所以要将MongoDB中的id字段设置成索引字段,否则性能会很慢。
MongoDB设置索引方法:
db.getCollection('mgtest').ensureIndex({"id" : "1"}),{"background":true}查看索引:
db.getCollection('mgtest').getIndexes()MongoSpark网址:https://docs.mongodb.com/spark-connector/current/java-api/