mfs
客户端写入数据请求到mfs-master,mfs-master存到后端server根据客户端的存储服务器数两分配chunk servers,然后,mfs-master将这个信息转给客户端,客户端与chunk servers进行数据写入,存储
环境
redhat.7.3
server11 172.25.66.11 ##mfsmaster节点
server12 172.25.66.12 ##从节点,就是真正储存数据的节点
server13 172.25.66.13 ##通server12
server14 172.25.66.14 ##高可用用,作为master节点,前边实验不用
selinux=disable ,防火墙关闭,开机不启动NetworkManager关闭,开机不启动
一.安装mfs
官网:https://moosefs.com/
参考https://moosefs.com/download/
如果你没包的话参考上边的官网,配置yum源安装,这里已经下载好了
server11安装下边三个包,server11为master节点
[root@server11 ~]# rpm -ivh moosefs-cgi-3.0.100-1.rhsystemd.x86_64.rpm
[root@server11 ~]# rpm -ivh moosefs-cgiserv-3.0.100-1.rhsystemd.x86_64.rpm
[root@server11 ~]# rpm -ivh moosefs-master-3.0.100-1.rhsystemd.x86_64.rpm
安装完,自动创建mfs用户,数据储藏目录在/var/lib/mfs
[root@server11 ~]# ll -d /var/lib/mfs/
drwxr-xr-x 2 mfs mfs 52 May 17 17:57 /var/lib/mfs/
[root@server11 ~]# id mfs
uid=996(mfs) gid=994(mfs) groups=994(mfs)
启动mfsmaster服务,没有报错,ok,开启了三个端口9419 #metalogger 监听的端口地址(默认是9419);9420 #用于chunkserver 连接的端口地址(默认是9420);9421 #用于客户端挂接连接的端口地址(默认是9421);
[root@server11 ~]# mfsmaster start
open files limit has been set to: 16384
working directory: /var/lib/mfs
lockfile created and locked
initializing mfsmaster modules ...
exports file has been loaded
topology file has been loaded
loading metadata ...
metadata file has been loaded
no charts data file - initializing empty charts
master <-> metaloggers module: listen on *:9419
master <-> chunkservers module: listen on *:9420
main master server module: listen on *:9421
mfsmaster daemon initialized properly
[root@server11 ~]# netstat -antlp
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:9419 0.0.0.0:* LISTEN 2137/mfsmaster
tcp 0 0 0.0.0.0:9420 0.0.0.0:* LISTEN 2137/mfsmaster
tcp 0 0 0.0.0.0:9421 0.0.0.0:* LISTEN 2137/mfsmaster
启动cgi服务,主要用古web监控
[root@server11 ~]# mfscgiserv
lockfile created and locked
starting simple cgi server (host: any , port: 9425 , rootpath: /usr/share/mfscgi)
浏览器查看
http://172.25.66.11:9425/mfs.cgi
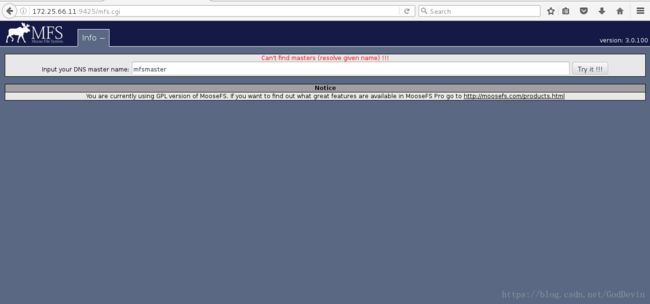
这是由于没有解析,注意是mfs的解析
添加解析,server11
[root@server11 ~]# vim /etc/hosts
172.25.66.11 server11 mfsmaster浏览器再次查看
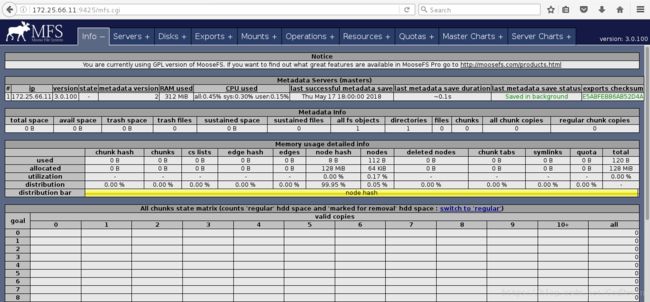
注意,mfsmaster这个解析从节点及一客户端短都要有,这里直接把server11的解析文件发给server12和server13以及server14
[root@server11 ~]# scp /etc/hosts server12:/etc/
[root@server11 ~]# scp /etc/hosts server13:/etc/
[root@server11 ~]# scp /etc/hosts server14:/etc/二.从节点部署
server12和server13安装包
[root@server12 ~]# rpm -ivh moosefs-chunkserver-3.0.100-1.rhsystemd.x86_64.rpm
[root@server13 ~]# rpm -ivh moosefs-chunkserver-3.0.100-1.rhsystemd.x86_64.rpm
server12从节点的配置
[root@server12 ~]# vim /etc/mfs/mfshdd.cfg ##这个文件全是注释只需要在最后一行写上这个目录,wq退出后重建该目录,修改所有人所有组为mfs
/mnt/chunk1
[root@server12 ~]# mkdir /mnt/chunk1
[root@server12 ~]# chown mfs.mfs /mnt/chunk1/
[root@server12 ~]# vim /etc/mfs/mfschunkserver.cfg ##这个文件页全是注释,取消下边这行注释,MASTER_HOST = mfsmaster
MASTER_HOST = mfsmasterserver13结点的配置与server12几乎相同
[root@server12 ~]# vim /etc/mfs/mfshdd.cfg ##这个文件全是注释只需要在最后一行写上这个目录,wq退出后重建该目录,修改所有人所有组为mfs
/mnt/chunk2
[root@server13 ~]# mkdir /mnt/chunk2
[root@server13 ~]# chown mfs.mfs /mnt/chunk2/
[root@server13 ~]# vim /etc/mfs/mfschunkserver.cfg ##这个文件页全是注释,取消下边这行注释,MASTER_HOST = mfsmaster
MASTER_HOST = mfsmaster启动两个结点的mfschunkserver
[root@server12 ~]# mfschunkserver start
open files limit has been set to: 16384
working directory: /var/lib/mfs
lockfile created and locked
setting glibc malloc arena max to 4
setting glibc malloc arena test to 4
initializing mfschunkserver modules ...
hdd space manager: path to scan: /mnt/chunk1/
hdd space manager: start background hdd scanning (searching for available chunks)
main server module: listen on *:9422
no charts data file - initializing empty charts
mfschunkserver daemon initialized properlyserver13也一样
[root@server13 ~]# mfschunkserver start
open files limit has been set to: 16384
working directory: /var/lib/mfs
lockfile created and locked
setting glibc malloc arena max to 4
setting glibc malloc arena test to 4
initializing mfschunkserver modules ...
hdd space manager: path to scan: /mnt/chunk2/
hdd space manager: start background hdd scanning (searching for available chunks)
main server module: listen on *:9422
no charts data file - initializing empty charts
mfschunkserver daemon initialized properly浏览器:查看
http://172.25.66.11:9425/
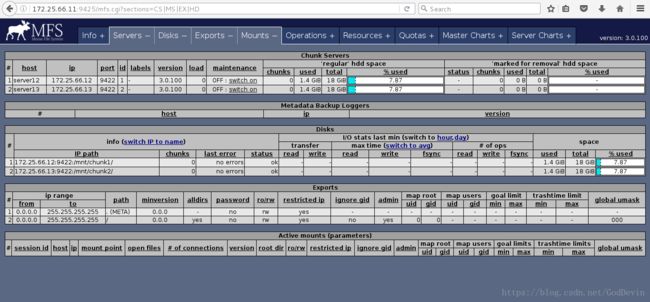
三.真机安装客户端
安装客户端
[root@foundation66 Desktop]# rpm -ivh moosefs-client-3.0.100-1.rhsystemd.x86_64.rpm配置解析
[root@foundation66 Desktop]# vim /etc/hosts
172.25.66.11 server11 mfsmaster
测试下,可以ping通
[root@foundation66 Desktop]# ping mfsmaster配置文件,挂载
[root@foundation66 Desktop]# vim /etc/mfs/mfsmount.cfg
/mnt/mfs
[root@foundation66 Desktop]# mkdir /mnt/mfs
[root@foundation66 Desktop]# mfsmount
mfsmaster accepted connection with parameters: read-write,restricted_ip,admin ; root mapped to root:rootdf 查看
[root@foundation66 Desktop]# df
mfsmaster:9421 37711872 2968512 34743360 8% /mnt/mfs数据的存储
在挂载的目录下新建两个目录
[root@foundation66 Desktop]# mkdir /mnt/mfs/dir1
[root@foundation66 Desktop]# mkdir /mnt/mfs/dir2查看由即太数据存储服务器(server2和server3)
[root@foundation66 Desktop]# mfsgetgoal /mnt/mfs/dir1
/mnt/mfs/dir1: 2 ##有两个
[root@foundation66 Desktop]# mfsgetgoal /mnt/mfs/dir2
/mnt/mfs/dir2: 2 ##有两个设置存储几份就是说,在给几台后端存储服务器上同步数据,这里最大为2因为只有server12和server13
[root@foundation66 Desktop]# mfsgetgoal /mnt/mfs/dir2
/mnt/mfs/dir2: 2
[root@foundation66 Desktop]# mfssetgoal -r 1 /mnt/mfs/dir1
/mnt/mfs/dir1:
inodes with goal changed: 1
inodes with goal not changed: 0
inodes with permission denied: 0
[root@foundation66 Desktop]# mfssetgoal -r 2 /mnt/mfs/dir2
/mnt/mfs/dir2:
inodes with goal changed: 0
inodes with goal not changed: 1
inodes with permission denied: 0各复制一份文件到/mnt/mfs/dir1和/mnt/mfs/dir2中
[root@foundation66 Desktop]# cp /etc/passwd /mnt/mfs/dir1
[root@foundation66 Desktop]# cp /etc/fstab /mnt/mfs/dir2
查看文件信息
[root@foundation66 Desktop]# mfsfileinfo /mnt/mfs/dir1/passwd
/mnt/mfs/dir1/passwd:
chunk 0: 0000000000000001_00000001 / (id:1 ver:1)
copy 1: 172.25.66.13:9422 (status:VALID)
[root@foundation66 Desktop]# mfsfileinfo /mnt/mfs/dir2/fstab
/mnt/mfs/dir2/fstab:
chunk 0: 0000000000000003_00000001 / (id:3 ver:1)
copy 1: 172.25.66.12:9422 (status:VALID)
copy 2: 172.25.66.13:9422 (status:VALID)
很显然fstab存了两份在server12和server13上各一份,而passwd只存了一份在server13上关闭server12
[root@server12 ~]# mfschunkserver stop
sending SIGTERM to lock owner (pid:2167)
waiting for termination terminated
对于fstasb这份文件来说不受影响,因为server12和server13都存了,关闭server12可以从server13读取
[root@foundation66 Desktop]# mfsfileinfo /mnt/mfs/dir2/fstab
/mnt/mfs/dir2/fstab:
chunk 0: 0000000000000003_00000001 / (id:3 ver:1)
copy 1: 172.25.66.13:9422 (status:VALID)
[root@foundation66 Desktop]# mfsfileinfo /mnt/mfs/dir1/passwd
/mnt/mfs/dir1/passwd:
chunk 0: 0000000000000001_00000001 / (id:1 ver:1)
copy 1: 172.25.66.13:9422 (status:VALID)开启server2
[root@server12 ~]# mfschunkserver start
open files limit has been set to: 16384
working directory: /var/lib/mfs
lockfile created and locked
setting glibc malloc arena max to 4
setting glibc malloc arena test to 4
initializing mfschunkserver modules ...
hdd space manager: path to scan: /mnt/chunk1/
hdd space manager: start background hdd scanning (searching for available chunks)
main server module: listen on *:9422
stats file has been loaded
mfschunkserver daemon initialized properly客户端恢复正常
[root@foundation66 Desktop]# mfsfileinfo /mnt/mfs/dir2/fstab
/mnt/mfs/dir2/fstab:
chunk 0: 0000000000000003_00000001 / (id:3 ver:1)
copy 1: 172.25.66.12:9422 (status:VALID)
copy 2: 172.25.66.13:9422 (status:VALID)
[root@foundation66 Desktop]# mfsfileinfo /mnt/mfs/dir1/passwd
/mnt/mfs/dir1/passwd:
chunk 0: 0000000000000001_00000001 / (id:1 ver:1)
copy 1: 172.25.66.13:9422 (status:VALID)关闭server3
[root@server13 ~]# mfschunkserver stop
sending SIGTERM to lock owner (pid:2408)
waiting for termination terminated
客户端查看信息如下
[root@foundation66 Desktop]# mfsfileinfo /mnt/mfs/dir1/passwd
/mnt/mfs/dir1/passwd:
chunk 0: 0000000000000001_00000001 / (id:1 ver:1)
no valid copies !!!
[root@foundation66 Desktop]# mfsfileinfo /mnt/mfs/dir2/fstab
/mnt/mfs/dir2/fstab:
chunk 0: 0000000000000003_00000001 / (id:3 ver:1)
copy 1: 172.25.66.12:9422 (status:VALID)
很显然passwd文件出现问题,恢复启动,进行下个实验对于大文件,实行离散存储
[root@foundation66 Desktop]# cd /mnt/mfs/dir1/
[root@foundation66 dir1]# dd if=/dev/zero of=bigfile bs=1M count=200
200+0 records in
200+0 records out
209715200 bytes (210 MB) copied, 0.768702 s, 273 MB/s
[root@foundation66 dir1]# mfsfileinfo bigfile
bigfile:
chunk 0: 0000000000000004_00000001 / (id:4 ver:1)
copy 1: 172.25.66.13:9422 (status:VALID)
chunk 1: 0000000000000005_00000001 / (id:5 ver:1)
copy 1: 172.25.66.12:9422 (status:VALID)
chunk 2: 0000000000000006_00000001 / (id:6 ver:1)
copy 1: 172.25.66.13:9422 (status:VALID)
chunk 3: 0000000000000007_00000001 / (id:7 ver:1)
copy 1: 172.25.66.12:9422 (status:VALID)
[root@foundation66 dir1]# cd ../dir2/
[root@foundation66 dir2]# dd if=/dev/zero of=bigfile bs=1M count=200
200+0 records in
200+0 records out
209715200 bytes (210 MB) copied, 1.52052 s, 138 MB/s
[root@foundation66 dir2]# mfsfileinfo bigfile
bigfile:
chunk 0: 000000000000000B_00000001 / (id:11 ver:1)
copy 1: 172.25.66.12:9422 (status:VALID)
copy 2: 172.25.66.13:9422 (status:VALID)
chunk 1: 000000000000000C_00000001 / (id:12 ver:1)
copy 1: 172.25.66.12:9422 (status:VALID)
copy 2: 172.25.66.13:9422 (status:VALID)
chunk 2: 000000000000000D_00000001 / (id:13 ver:1)
copy 1: 172.25.66.12:9422 (status:VALID)
copy 2: 172.25.66.13:9422 (status:VALID)
chunk 3: 000000000000000E_00000001 / (id:14 ver:1)
copy 1: 172.25.66.12:9422 (status:VALID)
copy 2: 172.25.66.13:9422 (status:VALID)
删除两个目录的bigfile
[root@foundation66 dir2]# rm -fr bigfile
[root@foundation66 dir2]# ls
fstab
[root@foundation66 dir2]# cd ../dir1/
[root@foundation66 dir1]# rm -fr bigfile
[root@foundation66 dir1]# ls
passwd删除文件缓存时间
[root@foundation66 dir1]# mfsgettrashtime .
.: 86400删除/mnt/mfs/dir1/passwd
[root@foundation66 dir1]# ls
passwd
[root@foundation66 dir1]# rm -rf passwd
接下来来进行元数据恢复
[root@foundation66 dir1]# mkdir /mnt/mfsmeta
[root@foundation66 dir1]# mfsmount -m /mnt/mfsmeta/
mfsmaster accepted connection with parameters: read-write,restricted_ip
此处挂载的话,事实上,df查看不到进行如下操作
[root@foundation66 dir1]# cd /mnt/mfsmeta/trash
[root@foundation66 trash]# find -name *passwd*
./004/00000004|dir1|passwd
[root@foundation66 trash]# mv ./004/00000004\|dir1\|passwd undel/
[root@foundation66 trash]# find -name *passwd* ##此时为空
[root@foundation66 trash]# cd /mnt/mfs/dir1
[root@foundation66 dir1]# ls ##文件找回来了
passwd补充
当mfs-master开启的时候在/var/lib/mfs/会有metadata.mfs.back这个文件,关闭的时候,转变成metadata.mfs
[root@server11 ~]# ll /var/lib/mfs/
total 3620
-rw-r----- 1 mfs mfs 4462 May 17 18:58 changelog.1.mfs
-rw-r----- 1 mfs mfs 45 May 17 17:59 changelog.2.mfs
-rw-r----- 1 mfs mfs 120 May 17 19:00 metadata.crc
-rw-r----- 1 mfs mfs 4253 May 17 19:00 metadata.mfs.back
-rw-r----- 1 mfs mfs 2901 May 17 18:00 metadata.mfs.back.1
-rw-r--r-- 1 mfs mfs 8 Jan 25 01:31 metadata.mfs.empty
-rw-r----- 1 mfs mfs 3672832 May 17 19:00 stats.mfs
[root@server11 ~]# mfsmaster stop
sending SIGTERM to lock owner (pid:2137)
waiting for termination terminated
[root@server11 ~]# ll /var/lib/mfs/
total 3624
-rw-r----- 1 mfs mfs 4462 May 17 18:58 changelog.2.mfs
-rw-r----- 1 mfs mfs 45 May 17 17:59 changelog.3.mfs
-rw-r----- 1 mfs mfs 120 May 17 19:01 metadata.crc
-rw-r----- 1 mfs mfs 4253 May 17 19:01 metadata.mfs
-rw-r----- 1 mfs mfs 4253 May 17 19:00 metadata.mfs.back.1
-rw-r--r-- 1 mfs mfs 8 Jan 25 01:31 metadata.mfs.empty
-rw-r----- 1 mfs mfs 3672832 May 17 19:01 stats.mfs四.高可用
1.需要安装pacemaker corosync pcs,我用的时redhat7.3所以用pcs
宿主机设置iptables
[root@foundation66 dir1]# iptables -t nat -I POSTROUTING -s 172.25.66.0/24 -j MASQUERADE
server11添加路由和dns
[root@server11 ~]# route add default gw 172.25.66.100
[root@server11 ~]# echo nameserver 114.114.114.114 >> /etc/resolv.conf
[root@server11 ~]# ping www.baidu.com阿里云yum源
[root@server11 ~]# vim /etc/yum.repos.d/yum.repo
[centos]
name=centos
baseurl=https://mirrors.aliyun.com/centos/7/os/x86_64/
gpgcheck=0安装
准备搭建第三方yum源
[root@server11 ~]# vim /etc/yum.conf
keepcache=1 ##改为1,缓存下的包
[root@server11 ~]# yum install pacemaker corosync pcs -y搭建第三方yum源
[root@server11 ~]# cp -r /var/cache/yum/x86_64/7Server/centos/packages/ /mnt
[root@server11 ~]# scp -r /mnt/packages/ [email protected]:
[root@server14 ~]# createrepo -v packages/
[root@server14 ~]# cat /etc/yum.repos.d/yum.repo
[rhel7.3]
name=rhel7.3
baseurl=http://172.25.66.100/rhel7.3
gpgcheck=0
enable=1
[centos]
name=centos
baseurl=file:///root/packages
gpgcheck=0
[root@server14 ~]# yum clean all
[root@server14 ~]# yum repolist
[root@server14 ~]# yum install pacemaker corosync pcs -y
2.免密配置
[root@server11 ~]# ssh-keygen
[root@server11 ~]# ssh-copy-id server11
[root@server11 ~]# scp -r /root/.ssh/ server14:~测试下
ssh相互连接测试
[root@server11 ~]# ssh server14
[root@server14 ~]# ssh server11
3.启动服务
[root@server11 ~]# systemctl start pcsd.service
[root@server11 ~]# systemctl enable pcsd.service
[root@server14 ~]# systemctl start pcsd.service
[root@server14 ~]# systemctl enable pcsd.service4.设置hacluster用户密码,当安装完三个包时,hacluster用户会自动创建,但是没密码,这里设置相同密码,必须相同
[root@server11 ~]# ssh server11 -- 'echo redhat | passwd --stdin hacluster' .
Changing password for user hacluster.
passwd: all authentication tokens updated successfully.
[root@server11 ~]# ssh server14 -- 'echo redhat | passwd --stdin hacluster'
Changing password for user hacluster.
passwd: all authentication tokens updated successfully
5.集群认证
[root@server11 ~]# pcs cluster auth server11 server14
Username: hacluster
Password:
server14: Authorized
server11: Authorized
6.给集群起个名字mycluster
[root@server11 ~]# pcs cluster setup --name mycluster server11 server14
Destroying cluster on nodes: server11, server14...
server11: Stopping Cluster (pacemaker)...
server14: Stopping Cluster (pacemaker)...
server14: Successfully destroyed cluster
server11: Successfully destroyed cluster
Sending 'pacemaker_remote authkey' to 'server11', 'server14'
server11: successful distribution of the file 'pacemaker_remote authkey'
server14: successful distribution of the file 'pacemaker_remote authkey'
Sending cluster config files to the nodes...
server11: Succeeded
server14: Succeeded
Synchronizing pcsd certificates on nodes server11, server14...
server14: Success
server11: Success
Restarting pcsd on the nodes in order to reload the certificates...
server14: Success
server11: Success
7.启动集群
[root@server11 ~]# pcs status cluster ##查看下关着
Error: cluster is not currently running on this node
[root@server11 ~]# pcs cluster start --all ##启动all标识两台主机server11和server14
server11: Starting Cluster...
server14: Starting Cluster...
[root@server11 ~]# pcs status cluster ##再次查看ok
Cluster Status:
Stack: unknown
Current DC: NONE
Last updated: Thu May 17 19:32:31 2018
Last change: Thu May 17 19:32:30 2018 by hacluster via crmd on server11
2 nodes configured
0 resources configured
PCSD Status:
server11: Online
server14: Online
8.查看集群信息的一些命令
[root@server11 ~]# corosync-cfgtool -s
Printing ring status.
Local node ID 1
RING ID 0
id = 172.25.66.11
status = ring 0 active with no faults
[root@server11 ~]# pcs status corosync
Membership information
----------------------
Nodeid Votes Name
1 1 server11 (local)
2 1 server14
[root@server11 ~]# pcs status
Cluster name: mycluster
WARNING: no stonith devices and stonith-enabled is not false
Stack: corosync
Current DC: server14 (version 1.1.18-11.el7-2b07d5c5a9) - partition with quorum
Last updated: Thu May 17 19:34:34 2018
Last change: Thu May 17 19:32:51 2018 by hacluster via crmd on server14
2 nodes configured
0 resources configured
Online: [ server11 server14 ]
No resources
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled9.配置集群服务
[root@server11 ~]# yum install bash-* -y
[root@server14 ~]# yum install bash-* -y
[root@server11 ~]# crm_verify -L -V ##会报一大堆error
error: unpack_resources: Resource start-up disabled since no STONITH resources have been defined
error: unpack_resources: Either configure some or disable STONITH with the stonith-enabled option
error: unpack_resources: NOTE: Clusters with shared data need STONITH to ensure data integrity
Errors found during check: config not valid关闭stonith-enabled
[root@server11 ~]# pcs property set stonith-enabled=false
[root@server11 ~]# crm_verify -L -V
添加vip
[root@server11 ~]# pcs resource create VIP ocf:heartbeat:IPaddr2 ip=172.25.66.250 cidr_netmask=32 op monitor interval=30s
[root@server11 ~]# pcs status
Cluster name: mycluster
Stack: corosync
Current DC: server14 (version 1.1.18-11.el7-2b07d5c5a9) - partition with quorum
Last updated: Thu May 17 19:37:28 2018
Last change: Thu May 17 19:37:21 2018 by root via cibadmin on server11
2 nodes configured
1 resource configured
Online: [ server11 server14 ]
Full list of resources:
VIP (ocf::heartbeat:IPaddr2): Started server11
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
查看下vip是否在server11
[root@server11 ~]# ip addr
1: lo: mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:0c:38:77 brd ff:ff:ff:ff:ff:ff
inet 172.25.66.11/24 brd 172.25.66.255 scope global eth0
valid_lft forever preferred_lft forever
inet 172.25.66.250/32 brd 172.25.66.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::5054:ff:fe0c:3877/64 scope link
valid_lft forever preferred_lft forever
挂起server1,vip转移server4
[root@server11 ~]# pcs node standby
[root@server11 ~]# pcs status
Cluster name: mycluster
Stack: corosync
Current DC: server14 (version 1.1.18-11.el7-2b07d5c5a9) - partition with quorum
Last updated: Thu May 17 19:39:23 2018
Last change: Thu May 17 19:39:17 2018 by root via cibadmin on server11
2 nodes configured
1 resource configured
Node server11: standby
Online: [ server14 ]
Full list of resources:
VIP (ocf::heartbeat:IPaddr2): Started server14
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
[root@server14 ~]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:39:f8:0d brd ff:ff:ff:ff:ff:ff
inet 172.25.66.14/24 brd 172.25.66.255 scope global eth0
valid_lft forever preferred_lft forever
inet 172.25.66.250/32 brd 172.25.66.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::5054:ff:fe39:f80d/64 scope link
valid_lft forever preferred_lft foreverserver1恢复过来vip不会在转移回来,除非server4挂了
[root@server11 ~]# pcs node unstandby
[root@server11 ~]# pcs status
Cluster name: mycluster
Stack: corosync
Current DC: server14 (version 1.1.18-11.el7-2b07d5c5a9) - partition with quorum
Last updated: Thu May 17 19:40:27 2018
Last change: Thu May 17 19:40:23 2018 by root via cibadmin on server11
2 nodes configured
1 resource configured
Online: [ server11 server14 ]
Full list of resources:
VIP (ocf::heartbeat:IPaddr2): Started server14
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
[root@server11 ~]# pcs resource providers ##查看提供的资源
heartbeat
openstack
pacemaker
[root@server11 ~]# pcs resource standards ##标准
lsb
ocf
service
systemd
编写systemd启动脚本
[root@server11 ~]# cd /usr/lib/systemd/system
[root@server11 system]# vim mfsd.service
[Unit]
Decription=mfs
After=network.target
[Service]
Type=forking
ExecStart=/usr/sbin/mfsmaster -a
ExecStop=/usr/sbin/mfsmaster stop
PrivateTmp=true
[Install]
WantedBy=multi-user.target
[root@server11 system]# systemctl daemon-reload
[root@server11 system]# systemctl stop mfsd.service
[root@server11 system]# systemctl start mfsd.service
[root@server11 system]# systemctl enable mfsd.service
经测试没问题后传给server14
[root@server11 system]# scp mfsd.service server14:/usr/lib/systemd/system/
测试的话可以通过查看进程或者看 ll /var/lib/mfs/有没有metadata.mfs这个文件,也可以通过客户端查看测试结果,在/mnt/mfs/中,server11关闭mfs-master客户端会卡住
server14安装mfs-master
[root@server14 ~]# rpm -ivh moosefs-master-3.0.100-1.rhsystemd.x86_64.rpm
[root@server14 ~]# systemctl start mfsd
[root@server14 ~]# systemctl enable mfsdserver13增加个虚拟硬盘
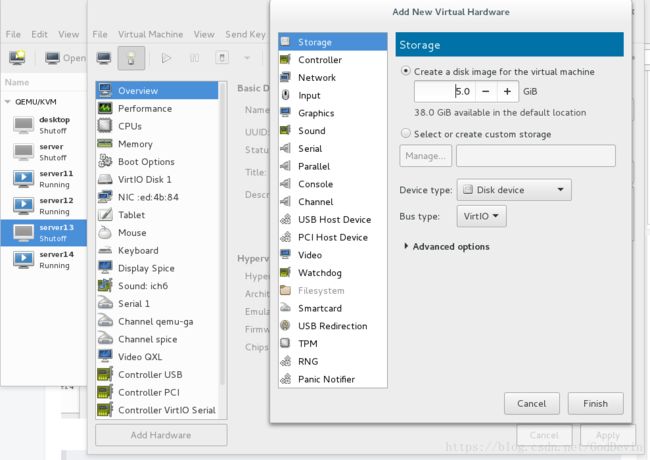
查找下盘符vda-5G
[root@server13 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
vda 252:0 0 20G 0 disk
├─vda1 252:1 0 1G 0 part /boot
└─vda2 252:2 0 19G 0 part
├─rhel-root 253:0 0 18G 0 lvm /
└─rhel-swap 253:1 0 1G 0 lvm [SWAP]
vdb 252:16 0 5G 0 disk
[root@server13 ~]# yum install targetcli -y
[root@server13 ~]# systemctl start target
[root@server13 ~]# targetcli
Warning: Could not load preferences file /root/.targetcli/prefs.bin.
targetcli shell version 2.1.fb41
Copyright 2011-2013 by Datera, Inc and others.
For help on commands, type 'help'.
/> /backstores/block create server13.disk1 /dev/vdb
Created block storage object server13.disk1 using /dev/vdb.
/> iscsi/ create iqn.2018-05.com.example:server13
Created target iqn.2018-05.com.example:server13.
Created TPG 1.
Global pref auto_add_default_portal=true
Created default portal listening on all IPs (0.0.0.0), port 3260.
/> iscsi/iqn.2018-05.com.example:server13/tpg1/acls create iqn.2018-05.com.example:mfs
Created Node ACL for iqn.2018-05.com.example:mfs
/> iscsi/iqn.2018-05.com.example:server13/tpg1/luns create /backstores/block/server13.disk1
Created LUN 0.
Created LUN 0->0 mapping in node ACL iqn.2018-05.com.example:mfs
/> exit
Global pref auto_save_on_exit=true
Last 10 configs saved in /etc/target/backup.
Configuration saved to /etc/target/saveconfig.json
[root@server13 ~]# netstat -anltpp | grep 3260 ##3260开启
tcp 0 0 0.0.0.0:3260 0.0.0.0:* LISTEN -
server11,server14安装iscsi
[root@server11 ~]# yum install iscsi-* -y
[root@server14 ~]# yum install iscsi-* -y
以下操作在server1上
发现设备
[root@server11 ~]# iscsiadm -m discovery -t st -p 172.25.66.13
172.25.66.13:3260,1 iqn.2018-05.com.example:server13
[root@server14 ~]# iscsiadm -m discovery -t st -p 172.25.66.13
172.25.66.13:3260,1 iqn.2018-05.com.example:server13链接设备
[root@server11 ~]# vim /etc/iscsi/initiatorname.iscsi
InitiatorName=iqn.2018-05.com.example:mfs
[root@server11 ~]# systemctl restart iscsid
[root@server11 ~]# iscsiadm -m node -l
Logging in to [iface: default, target: iqn.2018-05.com.example:server13, portal: 172.25.66.13,3260] (multiple)
Login to [iface: default, target: iqn.2018-05.com.example:server13, portal: 172.25.66.13,3260] successful.
[root@server11 ~]# lsblk ##查看盘符sda
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 5G 0 disk
vda 252:0 0 20G 0 disk
├─vda1 252:1 0 1G 0 part /boot
└─vda2 252:2 0 19G 0 part
├─rhel-root 253:0 0 18G 0 lvm /
└─rhel-swap 253:1 0 1G 0 lvm [SWAP]
分区,格式化ext4
[root@server11 ~]# fdisk /dev/sda ##建立sda1
[root@server11 ~]# mkfs.ext4 /dev/sda1
[root@server11 ~]# iscsiadm -m node -l
[root@server11 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 5G 0 disk
└─sda1 8:1 0 5G 0 part
vda 252:0 0 20G 0 disk
├─vda1 252:1 0 1G 0 part /boot
└─vda2 252:2 0 19G 0 part
├─rhel-root 253:0 0 18G 0 lvm /
└─rhel-swap 253:1 0 1G 0 lvm [SWAP]
[root@server11 ~]# blkid
/dev/vda1: UUID="f8295073-4c0b-4251-854b-532529e4fd14" TYPE="xfs"
/dev/vda2: UUID="2JnDpJ-CLgE-Q6fT-7qQZ-LcQJ-euHH-ZtYMPZ" TYPE="LVM2_member"
/dev/mapper/rhel-root: UUID="2b49c02e-3eef-4ac3-8b86-0017addb88cb" TYPE="xfs"
/dev/mapper/rhel-swap: UUID="40cba308-2871-41a8-bf62-0a2818805200" TYPE="swap"
/dev/sda1: UUID="1eb959f8-976a-4dd9-8569-906e8c9561fd" TYPE="ext4"
挂载
[root@server11 ~]# mount /dev/sda1 /mnt/
[root@server11 ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/rhel-root 18855936 1533896 17322040 9% /
devtmpfs 239232 0 239232 0% /dev
tmpfs 250212 38784 211428 16% /dev/shm
tmpfs 250212 4516 245696 2% /run
tmpfs 250212 0 250212 0% /sys/fs/cgroup
/dev/vda1 1038336 141532 896804 14% /boot
tmpfs 50044 0 50044 0% /run/user/0
/dev/sda1 5028480 20472 4729532 1% /mnt
[root@server11 ~]# cp -rp /var/lib/mfs/* /mnt/
不是所有都得这样修改,主要是挂载后,/var/lib/mfs/下的这些文件所有人和所有组要为mfs
[root@server11 ~]# cp -rp /var/lib/mfs/* /mnt/
[root@server11 ~]# umount /mnt/
[root@server11 ~]# mount /dev/sda1 /var/lib/mfs/
[root@server11 ~]# chown mfs.mfs /var/lib/mfs/*
[root@server11 ~]# chown root.root /var/lib/mfs/lost+found/ -R
[root@server11 ~]# ll /var/lib/mfs/
total 3644
-rw-r----- 1 mfs mfs 224 May 17 11:51 changelog.0.mfs
-rw-r----- 1 mfs mfs 4462 May 17 2018 changelog.2.mfs
-rw-r----- 1 mfs mfs 45 May 17 2018 changelog.3.mfs
drwx------ 2 root root 16384 May 17 12:01 lost+found
-rw-r----- 1 mfs mfs 120 May 17 2018 metadata.crc
-rw-r----- 1 mfs mfs 4253 May 17 2018 metadata.mfs.back
-rw-r----- 1 mfs mfs 4253 May 17 2018 metadata.mfs.back.1
-rw-r--r-- 1 mfs mfs 8 Jan 25 01:31 metadata.mfs.empty
-rw-r----- 1 mfs mfs 3672832 May 17 2018 stats.mfs
server14操作
server14挂载
[root@server14 ~]# vim /etc/iscsi/initiatorname.iscsi
InitiatorName=iqn.2018-05.com.example:mfs
[root@server14 ~]# systemctl restart iscsid
[root@server14 ~]# iscsiadm -m node -l
Logging in to [iface: default, target: iqn.2018-05.com.example:server13, portal: 172.25.66.13,3260] (multiple)
Login to [iface: default, target: iqn.2018-05.com.example:server13, portal: 172.25.66.13,3260] successful.
[root@server14 ~]# blkid
/dev/vda1: UUID="f8295073-4c0b-4251-854b-532529e4fd14" TYPE="xfs"
/dev/vda2: UUID="2JnDpJ-CLgE-Q6fT-7qQZ-LcQJ-euHH-ZtYMPZ" TYPE="LVM2_member"
/dev/mapper/rhel-root: UUID="2b49c02e-3eef-4ac3-8b86-0017addb88cb" TYPE="xfs"
/dev/mapper/rhel-swap: UUID="40cba308-2871-41a8-bf62-0a2818805200" TYPE="swap"
/dev/sda1: UUID="1eb959f8-976a-4dd9-8569-906e8c9561fd" TYPE="ext4"
[root@server14 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 5G 0 disk
└─sda1 8:1 0 5G 0 part
vda 252:0 0 20G 0 disk
├─vda1 252:1 0 1G 0 part /boot
└─vda2 252:2 0 19G 0 part
├─rhel-root 253:0 0 18G 0 lvm /
└─rhel-swap 253:1 0 1G 0 lvm [SWAP]
[root@server14 ~]# mount /dev/sda1 /var/lib/mfs/
[root@server14 ~]# ll /mnt/
total 0
[root@server14 ~]# chown mfs.mfs /var/lib/mfs/*
[root@server14 ~]# chown root.root /var/lib/mfs/lost+found/
usermod -g mfs mfs ##这个后边可能还有麻烦
添加磁盘,启动服务
[root@server11 ~]# pcs resource create mfsFS ocf:heartbeat:Filesystem device="/dev/sda1" directory="/var/lib/mfs/" fstype="ext4"
[root@server11 ~]# pcs status
[root@server11 ~]# pcs resource create mfsd systemd:mfsd
[root@server11 ~]# pcs status添加组服务
[root@server11 ~]# pcs resource group add mfsgroup VIP mfsFS mfsd op monitor interval=20s timeout=10s
[root@server11 ~]# pcs status
添加解析,集群内所有主机,包括客户机,注意去除原先的解析,这个解析文件会从上往下依次读取
真机、server1、server2、server3、server4都添加
172.25.66.250 mfsmaster
客户端此时可以正常使用
[root@foundation66 dir2]# mfsfileinfo fstab

接下来,挂server1,这里上边的操作并没有导致server4正常启动mfs-master,原因是/var/lib/mfs/下的那一堆文件的所有人和所有组有问题,总之解决了
[root@server11 ~]# pcs cluster standby server11
[root@server11 ~]# pcs status客户端正常访问

fence机制
[root@server11 ~]# yum install -y fence-virt.x86_64
[root@server14 ~]# yum install -y fence-virt.x86_64
查看可用的资源导入
[root@server11 ~]# stonith_admin -I
fence_xvm
fence_virt
2 devices found
[root@server11 ~]# stonith_admin -M -a fence_xvm
配置认证文件
[root@server11 ~]# mkdir /etc/cluster/
[root@server14 ~]# mkdir /etc/cluster/
##因为之前配好了,所以直接发,没有的话自行配置,参开之前的pacemaker
[root@foundation66 ~]# cd /etc/cluster/
[root@foundation66 cluster]# ls
fence_xvm.key
[root@foundation66 cluster]# scp fence_xvm.key server11:/etc/cluster/
[root@foundation66 cluster]# scp fence_xvm.key server14:/etc/cluster/
普通用户开启的时候输入密码了,途中没显示
[root@foundation66 ~]# systemctl start fence_virtd.service
添加服务
[root@server11 ~]# pcs property set stonith-enabled=true ##true
[root@server11 ~]# pcs stonith list
fence_virt - Fence agent for virtual machines
fence_xvm - Fence agent for virtual machines
[root@server11 ~]# pcs stonith create vmfence fence_xvm pcmk_host_map="server11:server11;server14:server14" op monitor interval=30s
[root@server11 ~]# pcs status
[root@server11 ~]# pcs cluster unstandby server11
[root@server11 ~]# pcs status
注意了:使server14崩溃,server14会自动断电重启
[root@server14 ~]# echo c >/proc/sysrq-trigger
服务转移server1,客户端正常
[root@server11 ~]# pcs status
[root@foundation66 dir2]# mfsfileinfo fstab重启后,由于没有设置开机自动启动集群服务,所以你得手动启动下
[root@server14 ~]# pcs cluster start --all
server11: Starting Cluster...
server14: Starting Cluster...
[root@server11 ~]# pcs status ##少等片刻,查看集群状态,fence机制到了server4上,服务正常