Mybatis
MyBatis是什么:
MyBatis 是一款优秀的持久层框架,它支持定制化 SQL、存储过程以及高级映射。MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可以使用简单的 XML 或注解来配置和映射原生信息,将接口和 Java 的 POJOs(Plain Old Java Objects,普通的 Java对象)映射成数据库中的记录。MyBatis的前身就是iBatis,iBatis本是apache的一个开源项目,2010年这个项目由apahce sofeware foundation 迁移到了google code,并且改名,所以市面上也会有人称为iBatis.
MyBatis的出现原因:
JDBC(Java Data Base Connection,java数据库连接)是一种用于执行SQL语句的Java API,可以为多种关系数据库提供统一访问,它由一组用Java语言编写的类和接口组成.JDBC提供了一种基准,据此可以构建更高级的工具和接口,使数据库开发人员能够编写数据库应用程序
JDBC的步骤,
1.加载驱动
2.获取连接
3.执行sql语句
4.处理结果集
5.关闭资源
JDBC的优点:
1.运行时快捷高效
JDBC的缺点:
1.工作量相对较大。我们需要先连接,然后处理JDBC底层事务,处理数据类型。我们还需要操作Connection对象、Statement对象和ResultSet对象去拿到数据,并准确的关闭它们
2.我们要对JDBC编程可能产生的异常进行捕捉处理并正确关闭资源。
正式因为JDBC的繁琐以及复杂操作,于是我们就提出了对象关系映射(Object Relational Mapping)简称 ORM,或者O/RM,或者 O/R mapping。不过,我们要知道所有的ORM模型都是基于对JDBC的进行封装,不同的ORM模型对JDBC封闭的强度是不一样的。
什么是ORM模型?
ORM模型就是数据库的表和简单Java对象(Plain Ordinary Java Object,简称POJO)的映射关系模型。
ORM模型的作用是什么 ?
它主要解决数据库数据和POJO对象的相互映射。我们通过这层映射就可以简单的把数据库表的数据转化为POJO。以便程序员更加容易的理解和应用Java程序.而且程序员一般只需要了解Java应用而无需对数据库进行深入的了解。此外,ORM模型提供了统一的规则使得数据库的数据通过配置便可轻易的映射到POJO上。。
ORM常用的有:
1.Hibernate:属于淘汰的
2.MyBatis:大面积使用
3.Spring Date JPA:很少用,是Hibernate的封装
这里我们只说Mybatis。
MyBatis对比JDBC的优势:
1. DAO层代码可以通过现有插件直接生成,大大提高编码效率和准确性。
2. MyBatis在SqlMapConfig.xml中配置数据连接池,使用数据库连接池管理数据库连接。
3. 一致的编码风格大大减少代码的沟通成本;
4. MyBatis提供了一级和二级缓存(需要配置打开),强大的动态sql,自动化的session管理,都比手工维护来的方便和安全。
5. 自动将sql执行结果映射至java对象,通过statement中的resultType定义输出结果的类型。
6. 自动将java对象映射至sql语句,将sql语句及占位符号和参数全部配置在xml中,即使sql变化,不需要对java代码进行重新编译,而且相似的sql不需要重复写,也可以用注解写sql语句。
MyBatis的模块图

MyBatis的流程图
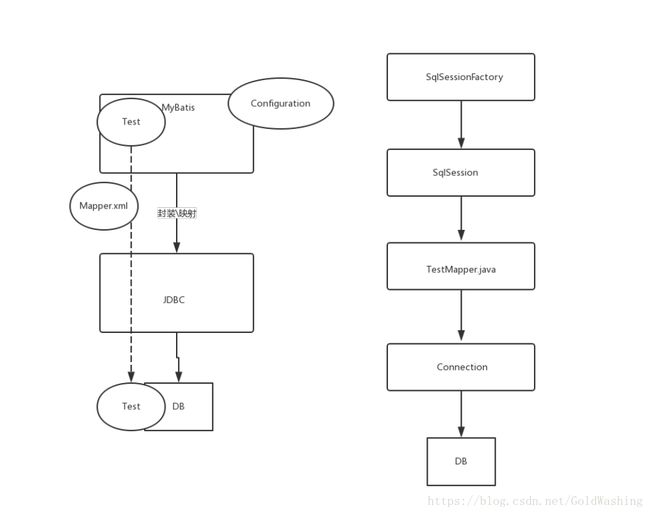
MyBatis的使用过程
1.配置bean
2.写SqlMapConfig.xml配置文件,配置数据库连接以及对Mapper的管理
3.配置SqlSessionFactory,或使用MyBatis自带的DefaultSqlSessionFactory,这个类实现了SqlSessionFactory,而SqlSessionFactory主要就是一个openSession的作用
4.sql语句的写法两种,Mapper.xml或在Mapper.java中方法上写注解sql
Myabatis的两者sql语句可以混合使用,达到互补的作用,注意id不能相同,不然会报错,id重复问题,没有所谓的优先级之说,两者的区别:
Mapper.xml:
优点:1.跟接口分离、统一管理
2.复杂的语句可以不影响接口的可读性
缺点:1.过多的XML文件
Annotation注解:
优点:1.接口就能看到sql语句,可读性高,不需要再去找xml文件,方便
2.复杂的联合查询不好维护,代码的可读性差
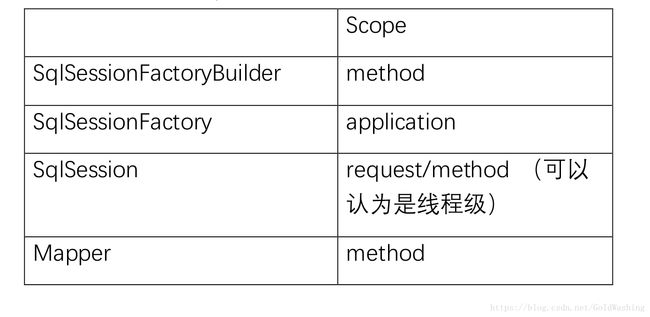
SqlSessionFactory\SqlSession\Mapper 推荐作用域
MyBatis的Type Handlers配置:
官方文档里有的可以 直接用http://www.mybatis.org/mybatis-3/configuration.html#typeHandlers
也可以创造自己的handler
package com.study.type;
import org.apache.ibatis.type.BaseTypeHandler;
import org.apache.ibatis.type.JdbcType;
import org.apache.ibatis.type.MappedJdbcTypes;
import java.sql.CallableStatement;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
@MappedJdbcTypes(JdbcType.VARCHAR)
public class StudyTypeHandle extends BaseTypeHandler {
@Override
public void setNonNullParameter(PreparedStatement preparedStatement, int i, String s, JdbcType jdbcType) throws SQLException {
System.out.println(s);
preparedStatement.setString(i,s+"study");
}
@Override
//可以在这里转义数据
public String getNullableResult(ResultSet resultSet, String s) throws SQLException {
return "天辉";
}
@Override
public String getNullableResult(ResultSet resultSet, int i) throws SQLException {
return null;
}
@Override
public String getNullableResult(CallableStatement callableStatement, int i) throws SQLException {
return null;
}
}
在Mapper.xml中这样配置自己的typehandler
上面加typeHandler只是查询用,如果其他的插入修改,则必须在sql语句中的列字段值中加入
#{schoolname,jdbcType=VARCHAR,typeHandler=com.study.type.StudyTypeHandle}在SqlMapConfig中配置typeHandler
sqlsession的工具类
package com.study.util;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import java.io.InputStream;
/**
* Created by Administrator on 2018/6/7 0007.
*/
public class SqlSessionUtil {
private static String filename= "SqlMapConfig.xml";
private static SqlSessionFactory factory=null;
static {
try {
InputStream inputstream= Resources.getResourceAsStream(filename);
factory=new SqlSessionFactoryBuilder().build(inputstream);
}catch (Exception e){
e.printStackTrace();
}
}
public static SqlSession getSqlSession(boolean flg){
if(null!=factory){
return factory.openSession(flg);
}
return null;
}
public static void closeSqlSession(SqlSession sqlSession){
if(null!=sqlSession){
sqlSession.close();
}
}
}
最后测试的方法,测试中发现插入ok,但是数据库没有,自增成功,原来是sqlSession没有commit,导致没事物没有提交
@Test
public void save() throws Exception{
School school=new School();
school.setSchoolname("小明");
school.setSchoolstudentid(2);
SqlSession sqlSession = SqlSessionUtil.getSqlSession(true);
SchoolMapper mapper =sqlSession.getMapper(SchoolMapper.class);
School school1 = mapper.selectByPrimaryKey(1);
System.out.println(school1);
int i = mapper.insert(school);
/* int i1 = mapper.updateByPrimaryKeySelective(school);
System.out.println(i1);*/
System.out.println(school);
SqlSessionUtil.closeSqlSession(sqlSession);
}
查询的结果,本来应该是

结果变成了这个,因为在getNullableResult这个方法中我把返回值变换成了这个
![]()
插入的结果也变了,因为在setNonNullParameter方法中我在传入的值后面结尾加了study
![]()
MyBatis的日志
在resources下添加log4j.properties这个文件
### 全局控制机制 ###
log4j.rootLogger = debug , stdout
#
#log4j日志分为5种级别
# debug 调试(开发阶段)
# info 运行信息(测试或者运行阶段)
# warn 警告信息
# error 程序错误信息
# fatal 系统错误信息
# 通过5种级别输出的日志 打印在文件中
#
# 全局控制机制
# root=info
# 日志级别 :fatal>error>warn>info>debug 所有全局控制中设值的级别以下的所有日志都不打印
### 输出到控制台 ###
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern =%-d{yyyy-MM-dd HH\:mm\:ss} [ %t\:%r ] - [ %p ] %m%n
在pom文件中添加依赖
org.slf4j
slf4j-log4j12
1.7.5
MyBatis的Mapper文件认识
与mapper.java文件的关联,扫包
sql复用,可以定义下面这种sql语句,然后通过
SchoolId, SchoolName, SchoolStudentId
动态sql语句,官网http://www.mybatis.org/mybatis-3/dynamic-sql.html,根据不同情况,生成不同的sql语句,灵活性强
SchoolId,
SchoolName,
SchoolStudentId,
Batch 批量操作,当很有数据要操作时候就需要批量操作了
1.for循环,性能差,每次都要进行db操作,在java文件中。
2.foreach 拼 SQL,性能最高,但是sql长度有限制,每次执行完必须检查,执行完之后id没有返回,在xml中。
传入的是List3.ExeutorType.BATCH ,性能高,执行完之后id没有返回。
Mybatis内置的ExecutorType有3种,默认的是simple,该模式下它为每个语句的执行创建一个新的预处理语句,单条提交sql;而batch模式重复使用已经预处理的语句,并且批量执行所有更新语句,显然batch性能将更优; 但batch模式也有自己的问题,比如在Insert操作时,在事务没有提交之前,是没有办法获取到自增的id,这在某型情形下是不符合业务要求的。
批量操作可以参考如下博客
https://blog.csdn.net/m0_37981235/article/details/79131493
MyBatis的级联查询
resultType与resultMap的区别
1.resulType是跟数据库的表字段对应的,所以当你如果只想要其中几个属性而不是全部时可以使用resultMap。
2.使用resultType进行输出映射,只有查询出来的列名和pojo中的属性名一致,该列才可以映射成功。如果查询出来的列名和pojo的属性名不一致,通过定义一个resultMap对列名和pojo属性名之间作一个映射关系,因为resultMap可以用typeHander转换。
3.resulType在多表关联字段是清楚知道的,性能调优直观,但是缺点必须要创建很多pojo类。
4.resulMap不需要写 join 语句 ,但是会产生N+1问题,先查出单个表的本身数据,在去查询关于数据,可以利用懒加载来解决。
一对一关系映射之resulMap嵌套结果
多对一关系映射之resulMap嵌套结果
MyBatis的分页操作
1.逻辑分页,即虽然看起来实现了分页的功能,但实际上是将查询的所有结果放置在内存中,每次都从内存获取。可以看看这个博客https://blog.csdn.net/qq924862077/article/details/52611848
所以内存开销比较大,在数据量比较小的情况下效率比物理分页高;在数据量很大的情况下,内存开销过大,容易内存溢出,不建议使用
2. 物理分页,这种分页方法从底层上就是每次只查询对应条目数量的数据,从而实现了真正意义上的分页。
MySQL通过limt关键字分页来达到效果,我们可以使用 分页插件 https://github.com/pagehelper/Mybatis-PageHelper来达到效果
所以 内存开销比较小,在数据量比较小的情况下效率比逻辑分页还是低,在数据量很大的情况下,建议使用物理分页