Java笔试必考知识点合集一
1.web开发中如何实现会话跟踪?
会话跟踪是一种灵活、轻便的机制,它使Web上的状态编程变为可能。
HTTP是一种无状态协议,每当用户发出请求时,服务器就会做出响应,客户端与服务器之间的联系是离散的、非连续的。当用户在同一网站的多个页面之间转换时,根本无法确定是否是同一个客户,会话跟踪技术就可以解决这个问题。当一个客户在多个页面间切换时,服务器会保存该用户的信息。
有四种方法可以实现会话跟踪技术:URL重写、隐藏表单域、Cookie、Session。
1).隐藏表单域:,一种非常适合且不需要大量数据存储的会话应用。
2).URL 重写:URL 可以在后面附加参数,和服务器的请求一起发送,这些参数为名字/值对。
3).Cookie:一个 Cookie 是一个小的已命名数据元素。服务器使用 SET-Cookie 头标将它作为 HTTP
响应的一部分传送到客户端,客户端被请求保存 Cookie 值,在对同一服务器的后续请求使用一个
Cookie 头标将之返回到服务器。与其它技术比较,Cookie 的一个优点是在浏览器会话结束后,甚至
在客户端计算机重启后它仍可以保留其值。
4).Session:使用 setAttribute(String str,Object obj)方法将对象捆绑到一个会话。
HTTP是“无状态”协议:客户程序每次读取 Web 页面,都打开到 Web 服务器的单独的连接,并且,服务器也不自动维护客户的上下文信息。即使那些支持持续性 HTTP 连接的服务器,尽管多个客户请求连续发生且间隔很短时它们会保持 socket 打开,但是,它们也没有提供维护上下文信息的内建支持。上下文的缺失引起许多困难。例如,在线商店的客户向他们的购物车中加入商品时,服务器如何知道购物车中己有何种物品呢?类似地,在客户决定结账时,服务器如何能确定之前创建的购物车中哪个属于此客户呢?这些问题虽然看起来十分简单,但是由于 HTTP 的不足,解答它们却异常复杂困难。对于这个问题,存在 3 种典型的解决方案:
Cookie(结合session使用)
可以使用 cookie 存储购物会话的 ID;在后续连接中,取出当前的会话 ID,并使用这个 ID 从服务器上的查找表(lookup table)中提取出会话的相关信息。 以这种方式使用 cookie 是一种绝佳的解决方案,也是在处理会话时最常使用的方式。但是,sevlet 中最好有一种高级的 API 来处理所有这些任务,以及下面这些冗长乏味的任务:从众多的其他cookie中(毕竟可能会存在许多cookie)提取出存储会话标识符的 cookie;确定空闲会话什么时候过期,并回收它们;将散列表与每个请求关联起来;生成惟一的会话标识符。
URL 重写
采用这种方式时,客户程序在每个URL的尾部添加一些额外数据。这些数据标识当前的会话,服务器将这个标识符与它存储的用户相关数据关联起来。 URL重写是比较不错的会话跟踪解决方案,即使浏览器不支持 cookie 或在用户禁用 cookie 的情况下,这种方案也能够工作。URL 重写具有 cookie 所具有的同样缺点,也就是说,服务器端程序要做许多简单但是冗长乏味的处理任务。即使有高层的 API 可以处理大部分的细节,仍须十分小心每个引用你的站点的 URL ,以及那些返回给用户的 URL。即使通过间接手段,比如服务器重定向中的 Location 字段,都要添加额外的信息。这种限制意味着,在你的站点上不能有任何静态 HTML 页面(至少静态页面中不能有任何链接到站点动态页面的链接)。因此,每个页面都必须使用 servlet 或 JSP 动态生成。即使所有的页面都动态生成,如果用户离开了会话并通过书签或链接再次回来,会话的信息也会丢失,因为存储下来的链接含有错误的标识信息。
隐藏的表单域
HTML 表单中可以含有如下的条目:
这个条目的意思是:在提交表单时,要将指定的名称和值自动包括在 GET 或 POST 数据中。这个隐藏域可以用来存储有关会话的信息,但它的主要缺点是:仅当每个页面都是由表单提交而动态生成时,才能使用这种方法。单击常规的超文本链接并不产生表单提交,因此隐藏的表单域不能支持通常的会话跟踪,只能用于一系列特定的操作中,比如在线商店的结账过程。
2.JVM内存配置参数
-Xmx10240m -Xms10240m -Xmn5120m -XXSurvivorRatio=3
其最小内存值和Survivor区总大小分别是:10240m,2048m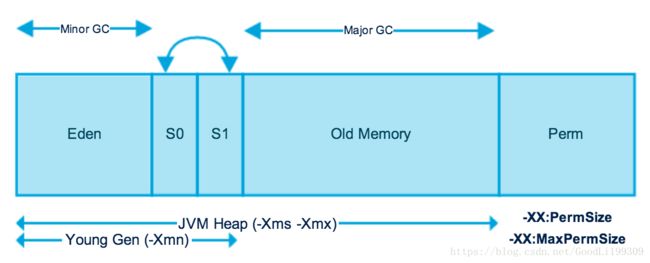
- 年轻代(Young Generation);
- 年老代(Old Generation);
- 永久代(Permanent Generation,也就是方法区)。
- ** 年轻代:对象被创建时(new)的对象通常被放在Young(除了一些占据内存比较大的对象),经过一定的Minor GC(针 对年轻代的内存回收)还活着的对象会被移动到年老代(一些具体的移动细节省略)。
- **年老代:就是上述年轻代移动过来的和一些比较大的对象。Minor GC(FullGC)是针对年老代的回收
- **永久代:存储的是final常量,static变量,常量池。
- permantspace(持久带)
- heap space
- 年轻代的垃圾回收叫 Young GC
- 年老代的垃圾回收叫 Full GC
- 年老代溢出原因:循环上万次的字符串处理、创建上千万个对象、在一段代码内申请上百M甚至上G的内存。
- 持久代溢出原因:动态加载了大量Java类而导致溢出
3.Math.round(11.5) 的使用:
4.webservice的描述:
5.前台线程和后台线程:
前台线程和后台线程的区别和联系:
2、可以在任何时候将前台线程修改为后台线程,方式是设置Thread.IsBackground 属性。
3、不管是前台线程还是后台线程,如果线程内出现了异常,都会导致进程的终止。
4、托管线程池中的线程都是后台线程,使用new Thread方式创建的线程默认都是前台线程。
*说明:
6.Java中的类加载器:
类的加载是由类加载器完成的,类加载器包括:根加载器( BootStrap )、扩展加载器( Extension )、系统加载器( System )和用户自定义类加载器( java.lang.ClassLoader 的子类)。
1
)Bootstrap ClassLoader(根加载器)
负责加载$JAVA_HOME中jre/lib/rt.jar里所有的
class
,由C++实现,不是ClassLoader子类
2
)Extension ClassLoader(扩展加载器)
负责加载java平台中扩展功能的一些jar包,包括$JAVA_HOME中jre/lib/*.jar或-Djava.ext.dirs指定目录下的jar包
3
)App ClassLoader(系统加载器)
负责记载classpath中指定的jar包及目录中
class
4
)Custom ClassLoader(用户自定义类加载器)
属于应用程序根据自身需要自定义的ClassLoader,如tomcat、jboss都会根据j2ee规范自行实现ClassLoader
加载过程中会先检查类是否被已加载,检查顺序是自底向上,从Custom ClassLoader到BootStrap ClassLoader逐层检查,
只要某个classloader已加载就视为已加载此类,保证此类及所有ClassLoader加载一次。而加载的顺序是自顶向下,也就是
由上层来逐层尝试加载此类。