python 中的排序大法
写在前面的话
今天还是技术博客,我怕我控制不住自己,未来的不久又开始写传说中的被蛋蛋狂吐槽的感情博客,先多写几篇技术博客压压惊。
今天写Python的排序大法,当然保持以前的作风,又不单单讲排序。
1.基本概念
1.1Pyhton 中的List排序
在Python中有两个排序函数,sort 和 sorted.下面我们一点点深入下去看看这两个函数怎么使用。
sorted 是Python的内建函数。
使用的方法:
sorted(data, cmp=None, key=None, reverse=False) 默认的reverse的值是false。表示是从小到大排序。
其中,data是待排序数据,可以使List或者iterator, cmp和key都是函数,这两个函数作用与data的元素上产生一个结果,sorted方法根据这个结果来排序。
cmp(e1, e2) 是带两个参数的比较函数, 返回值: 负数: e1 < e2, 0: e1 == e2, 正数: e1 > e2. 默认为 None, 即用内建的比较函数.
key 是带一个参数的函数, 用来为每个元素提取比较值. 默认为 None, 即直接比较每个元素.
通常, key 和 reverse 比 cmp 快很多, 因为对每个元素它们只处理一次; 而 cmp 会处理多次.
假设有一个List : aa=[9,2,1,4,6,7,8,0,3]
先来看看这两个排序函数的功效:
1.从小到大排序

我们使用sort函数给aa 这个list 从小到达排序,我们输出结果可以看到这个链表已经排序好了。但是注意: 这个函数是不能改变链表本身的,所以我们输出链表看看结果,发现还是一样的。 如果我们不想改变原始list的值,我们可以采用这种方法。
2.从大到小排序
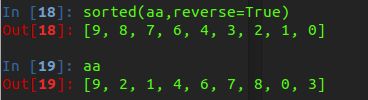
我们使用上面这个方法可以使用逆向排序,注意原始链表还是不会发生变化。
如果我们想让这个链表直接发生变化,我们可以使用sort在链表上进行操作,这样可以直接导致我们的链表发生变化。
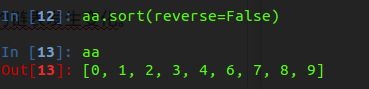
1.从小到大排序

图一
图二
reverse=False也表示是从小到大排序。
图一和图二的效果是一样的。
2.从大到小排序
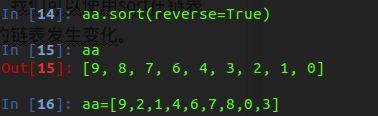
注意:
python 中的sort是不能对tuple类型的元素进行排序的,因为我们知道元组是不可以改变的。我们可以用sorted作用在我们的元组上,但是最后得到的结果的一个list

1.2Pyhton 中字典的排序
1.2.1 lambda
我们在对字典进行排序的时候,我们需要借助lambda,它实际上是一个匿名函数
它的一般形式:
lambda arguments: expression写成函数形式就是
def <lambda>(arguments):
return expression当lambda和sorted()的key [sorted(iterable[,key][,reverse])]结合在一起,会有很多神奇的化学反应。
1.2.2 对字典的key进行排序
如果我们直接使用sorted作用在我们的字典上面,实际上就是对我们的key键进行排序。
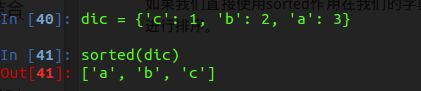

dic = {'c': 1, 'b': 2, 'a': 3}
print(sorted(dic))
# ['a', 'b', 'c']这个时候我们来看看我们排序之后的字典是什么样子的

字典的顺序竟然发生了变化
我们在试试下面逆向排序的结构是什么样子的:
print(sorted(dic, reverse=True))
# ['c', 'b', 'a']
可是这里只有键的排序发生了变化,但是我们再次查看我们的字典,纳尼,竟然没有变化??为什么一会有变化一会又没有变化?不懂了,跪求各位大神帮忙解释一下。
也有可能是字典的排序本来就是不按规则来的。但是每次都出现这种巧合?why??
1.2.3 对字典的其他排序方法
1.2.3.1 使用lambda
刚才说了我们可以使用lambda对我们的字典进行排序,但是这个会有个副作用,那就是排序之后我们的字典会变成字典和元组的嵌套.
我们来看一下下面的这个例子。
首先说明一点,我们使用lambda的时候既可以对我们的字典的key进行排序,也可以对values进行排序。
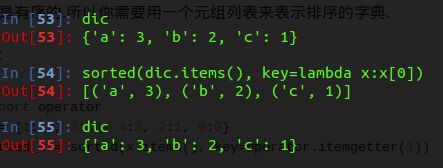
还是严格按照我们sorted的定义来看结合lambda
我们的字典是dic = {‘a’: 3, ‘b’: 2, ‘c’: 1}
我们来看这个排序语句是什么意思:
sorted(dic.items(), key=lambda x: x[0])我们结合我们的sorted的定义来看:
sorted(data, cmp=None, key=None, reverse=False) 首先我们要排序的字典是叫做dic, 我们使用dic.items()这个语句的时候我们可以得到整个字典的键值对,这个时候我们使用lambda这个匿名函数, 我们定义 x 表示字典中的所有简直对,这个时候我们取x[0],表示按照字典中的key来进行排序。
同理我们就知道如果我们要按照我们字典的values来排序,那么就是下面这个样子的。

那就是把我们的x[0]替换成我们的x[1]这个时候就表示对我们的值进行排序。我们可以从图中清楚的看出我的的排序结果。
得到的是list和我们的tuple的嵌套体。但是我们也可以发现它是不会对原来的字典进行任何改变的。
那我们可不可以先按照我们的键来排序一次,之后我们又按照我们的值来进行排序。答案是肯定的。我们来看看怎么使用。
语法如下:
sorted(dic.items(), key=lambda x:(x[0],x[1]))
1.2.3.2 使用operator进行排序
我们来看一下具体操作:

我们首先要import operator
根据字典的key进行排序:
sorted(x.items(), key=operator.itemgetter(0))根据字典的values进行排序:
sorted(x.items(),key=operator.itemgetter(1))我们在来看一个更加生动形象的例子,可能使用性更高
>>>peeps = [{'name': 'Bill', 'salary': 1000}, {'name': 'Bill', 'salary': 500}, {'name': 'Ted', 'salary': 500}]先按名字进行排序,之后按照工资进行排序
>>>sorted(peeps, key=lambda x: (x['name'], x['salary']))
[{'salary': 500, 'name': 'Bill'}, {'salary': 1000, 'name': 'Bill'}, {'salary': 500, 'name': 'Ted'}]如果是方向排序,那我们的做法就是取反
对 salary 反向排序?很简单,对它取反:
>>> sorted(peeps, key=lambda x: (x['name'], -x['salary']))
[{'salary': 1000, 'name': 'Bill'}, {'salary': 500, 'name': 'Bill'}, {'salary': 500, 'name': 'Ted'}]1.2Pyhton 中的嵌套排序
Python中的嵌套排序才是所有排序中的最有意思的部分。list,dict 还有tuple可以任意组合排列在一起。
下面我们看看这个东西组合在一起怎么使用。其实我们主要还是要借助我们强大的lambda来进行排序。
1.2.1 List 和List的嵌套
假设我们有一个list 它嵌套了一个List像下面这个样子的:
she=[[3,2,1],[1,4,0],[0,1,1],[5,3,3]]我们要对它进行排序
可以根据每一个List的第一个元素进行排序,也可以根据第二个,第三个,或者其中的任意两个,或者三个进行排序。
我们来实践一下。
之一这个也是不会改变原来的list的,我们可以把这个赋值给一个新的list。
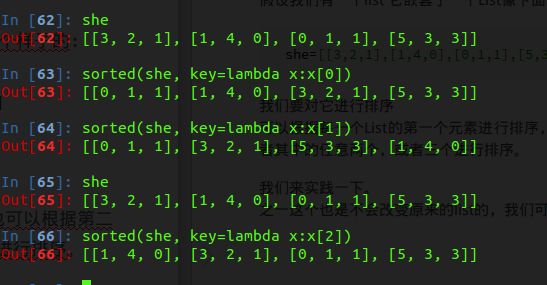
如果我们要根据其中的任意两个进行赋值:
先在保证第一个的情况下排序再来排序满足第二个的情况

同样其他的数据结构也是类似的操作。
1.2.2 List 和tuple的嵌套

同样它们不会改变原来的数据的


说明,我们只用sorted也是可以的
>>> items = [(1, 'B'), (1, 'A'), (2, 'A'), (0, 'B'), (0, 'a')]
>>> sorted(items)
[(0, 'B'), (0, 'a'), (1, 'A'), (1, 'B'), (2, 'A')]
默认情况下内置的sort和sorted函数接收的参数是元组时,他将会先按元组的第一个元素进行排序再按第二个元素进行排序。 然而,注意到结果中(0, ‘B’)在(0, ‘a’)的前面。这是因为大写字母B的ASCII编码比a小。
我们可以试着写一个lambda函数(eg.sorted(items, key=lambda x: x.lower() if isinstance(x, str) else x)),他将不会工作因为你只处理了元组的一个元素。
1.2.3 List 和字典的嵌套
lis = [
{'x': 3, 'y': 2, 'z': 1},
{'x': 2, 'y': 1, 'z': 3},
{'x': 1, 'y': 3, 'z': 2},
]
print(sorted(lis, key=lambda k: k['x']))
# [{'z': 2, 'x': 1, 'y': 3}, {'z': 3, 'x': 2, 'y': 1}, {'z': 1, 'x': 3, 'y': 2}]
print(sorted(lis, key=lambda k: k['y']))
# [{'z': 3, 'x': 2, 'y': 1}, {'z': 1, 'x': 3, 'y': 2}, {'z': 2, 'x': 1, 'y': 3}]
print(sorted(lis, key=lambda k: k['z']))
# [{'z': 1, 'x': 3, 'y': 2}, {'z': 2, 'x': 1, 'y': 3}, {'z': 3, 'x': 2, 'y': 1}]
print(sorted(lis, key=lambda k: k['x'], reverse=True))
# [{'z': 1, 'x': 3, 'y': 2}, {'z': 3, 'x': 2, 'y': 1}, {'z': 2, 'x': 1, 'y': 3}]好吧,我也写不动了。还有什么以后再来补充了把。我写了这么多程序用到的就是这么几个。如果还有其他的数据结构,其实都是可以转换的。
2.运用场景
现在我有一堆文件。
像下面这个样子的:
t # 150
v 0
v 1
v 2
v 3
v 4
v 5
v 6
v 7
v 8
v 9
e 0 1
e 0 2
e 3 1
e 4 5
e 6 5
e 7 8
e 2 9
e 1 9
t # 95
v 0
v 1
v 2
v 3
v 4
v 5
v 6
v 7
v 8
v 9
v 10
v 11
v 12
v 13
v 14
v 15
v 16
v 17
v 18
v 19
v 20
v 21
v 22
v 23
v 24
v 25
v 26
v 27
v 28
v 29
e 0 1
e 2 3
e 4 5
e 6 7
e 8 9
e 3 8
e 10 11
e 10 12
e 10 13
e 14 15
e 16 17
e 18 19
e 20 21
e 22 23
e 9 9
e 23 24
e 23 25
e 26 27
e 26 28
e 29 29
t # -1下面我们要把这堆文件改成下面这个样子的:
t # 150
v 0
v 1
v 2
v 3
v 4
v 5
v 6
v 7
v 8
v 9
e 0 1
e 0 2
e 1 9
e 2 9
e 3 1
e 4 5
e 6 5
e 7 8
t # 95
v 0
v 1
v 2
v 3
v 4
v 5
v 6
v 7
v 8
v 9
v 10
v 11
v 12
v 13
v 14
v 15
v 16
v 17
v 18
v 19
v 20
v 21
v 22
v 23
v 24
v 25
v 26
v 27
v 28
v 29
e 0 1
e 2 3
e 3 8
e 4 5
e 6 7
e 8 9
e 9 9
e 10 11
e 10 12
e 10 13
e 14 15
e 16 17
e 18 19
e 20 21
e 22 23
e 23 24
e 23 25
e 26 27
e 26 28
e 29 29 好的,如果你已经看出了规律,就是对e 后面的数据进行重拍,先按照第一列的数据从小到大排列,之后在按照第二列的数据从小到大进行排列。
3.代码
#!/usr/bin/env python
# coding=utf-8
# @ author : Chicho
# @ date : 2016-11-14
# @ running : python sortEdge.py
# @ function: sort the edge and output the result
import os
# store the files need to be handled
path = "/home/chicho/workspace/repackaged/sort/"
# get all the filename
fileList = os.listdir(path)
for filename in fileList:
filePath = os.path.join(path,filename)# get the path of each file path
f = open(filePath)
foutname = filename + "_Sort" # the outPut filename
foutPath = os.path.join(path,foutname) # destination filePath
fout =open(foutPath,"w+")
edgeList=[]
lineList = f.readlines() # get all lines of each file
i = 0
while i < len(lineList):
line = lineList[i]
'''
if i+1
if not line.startswith("e"):
if line.startswith("t"):
graphname = line.replace("\n","") # store the name of each graph which need sort
fout.write(line)
i = i + 1
if line.startswith("e"):
edgeList=[]
while lineList[i].startswith("e"):
line = lineList[i]
line = line.replace("\n","")
element = tuple(line.split(" "))# sort the edge
edgeList.append(element)
if i < len(lineList)-1:
i = i + 1
else:
newedgeList=sorted(edgeList, key=lambda x:(int(x[1]),int(x[2])))
if newedgeList != edgeList:
cmd = "{0} file {1} has changed!".format(filename,graphname)
print cmd
for edge in newedgeList:
for e in edge:
fout.write(e+" ")
fout.write("\n")
f.close()
fout.close()
'''
for line in f.readlines():
if line.startswith("v") or line.startswith(" "):
fout.write(line)
if line.startswith("e"):
line = line.replace("\n","")
elist = line.split(" ")
edgeList.append(elist)
if line.startswith("t"):
if len(edgeList)!=0:
edgeList.sort(key=lambda x:x[1])
# edgeList.sort(key=lambda x:x[1])
print edgeList
for edge in edgeList:
for element in edge:
fout.write(element + " ")
fout.write("\n")
edgeList=[]
fout.write(line)
f.close()
fout.close()
'''
Reference
[1]. http://gaopenghigh.iteye.com/blog/1483864
[2] Python:使用lambda应对各种复杂情况的排序,包括list嵌套dict
[3]用字典的值对字典进行排序
https://taizilongxu.gitbooks.io/stackoverflow-about-python/content/11/README.html
[4]在python中对一个元组排序
http://peiqiang.net/2015/01/20/in-python-you-sort-with-a-tuple.html
[5]https://www.peterbe.com/plog/in-python-you-sort-with-a-tuple
写在后面的话
毛爷爷说的:好好学习,天天向上
你必须非常努力才可以看起来毫不费力。

时间过了这么久,我们再也回不到从前的样子
你打太多工了啊
是你太会花钱了,哼╭(╯^╰)╮