Java笔记---Hadoop 2.7.1下WordCount程序详解
一、前言
在之前我们已经在 CenOS6.5 下搭建好了 Hadoop2.x 的开发环境。既然环境已经搭建好了,那么现在我们就应该来干点正事嘛!比如来一个Hadoop世界的HelloWorld,也就是WordCount程序(一个简单的单词计数程序)
二、WordCount 官方案例的运行
2.1 程序简介
WordCount程序是hadoop自带的案例,我们可以在 hadoop 解压目录下找到包含这个程序的 jar 文件(hadoop-mapreduce-examples-2.7.1.jar),该文件所在路径为 hadoop/share/hadoop/mapreduce。
我们可以使用 hadoop jar 命令查看该jar包详细信息。执行命令:hadoop jar hadoop-mapreduce-examples-2.7.1.jar
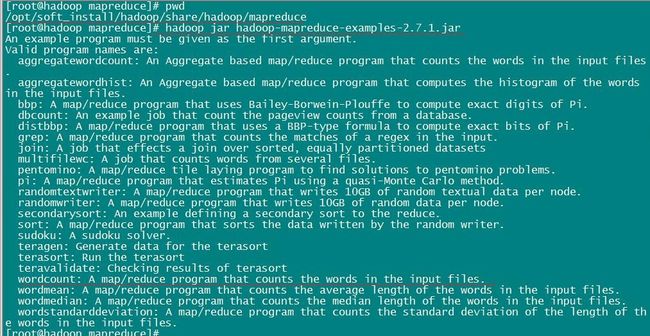
可以看到,该 jar 文件中并不止有一个案例,当然我们此时只想看看 WordCount 程序,其他的靠边边。那么我们按照提示,执行命令:hadoop jar hadoop-mapreduce-examples-2.7.1.jar wordcount 看看有什么东西?
![]()
根据提示,它说是需要输入文件和输出目录,那么接下来,我们就准备以下输入文件和输出目录吧。
注:其实只需要准备输入文件,不需要准备输出目录。因为 MapReduce 程序的运行,其输出目录不能是已存在的,否则会抛出异常。
这是为了避免数据覆盖的问题。请看《Hadoop权威指南》
2.2 准备材料
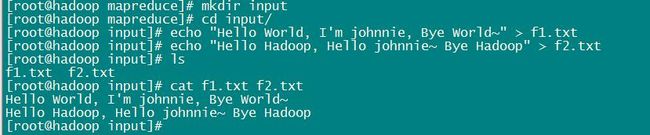
为了方便使用该官方 jar 文件,我们在当前目录下创建一个 input 目录(你也可以在别的目录下创建目录,目录名也可以自己取,喜欢就好),用来存放输入文件。然后准备2个输入文件。如下所示:
因为我们是使用 HDFS 文件系统的,所以我们要运行 WordCount 这个 MapReduce 程序的话,需要将文件放入 HDFS 上。因此我们使用 HDFS 的文件系统命令,在HDFS文件系统根目录下创建一个input目录,用来保存输入文件。执行命令:hadoop fs -mkdir /input
![]()
注:hadoop fs -mkdir 命令是用来在 HDFS 上创建目录的,类似于Linux下的 mkdir 命令
目录创建好后,我们需要把刚刚在本地文件系统上准备的输入文件拷贝到 HDFS 上。执行命令:hadoop fs -put input/f*.txt /input

2.3 运行程序
准备工作就绪了,那么现在就开始运行程序了。执行命令:hadoop jar hadoop-mapreduce-examples-2.7.1.jar wordcount /input /output
注:hadoop jar hadoop-mapreduce-examples-2.7.1.jar wordcount /input /output详解
- 该命令中 /input 表示使用 HDFS 上根目录(/)下的 input 目录下所有文件作为程序输入
- /output 表示使用 HDFS 根目录下的 output 目录存储程序的输出(该 output 文件,是本来不存在的,会由程序自动创建)
从终端可以看到如下命令输出:
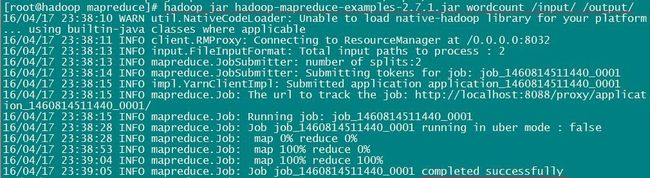
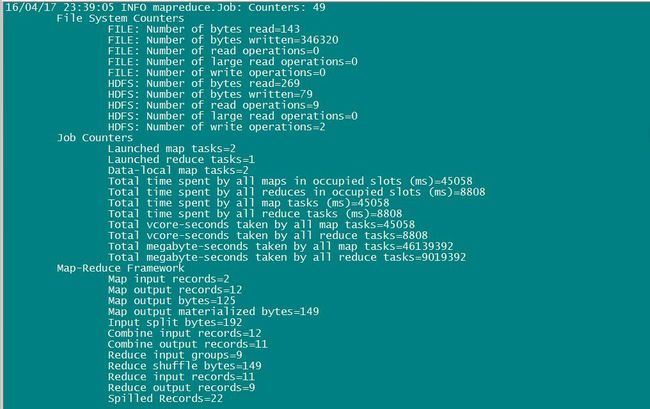
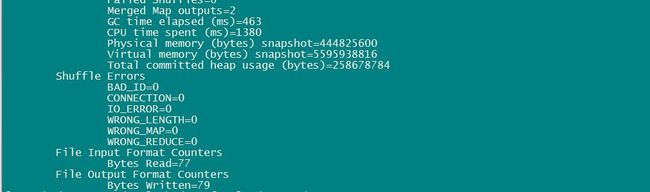
程序运行完毕,我们看一下输出都有啥,执行命令:hadoop fs -cat /output/*
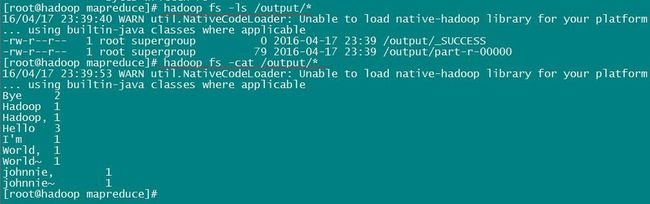
注:hadoop fs -cat 命令功能类似于linux下的 cat 命令
从上面的输出,可以看到该程序将我们的输入文件中的单词出现情况,进行了统计。都是 key,value 的形式出现的
三、WordCount 官方程序的源码分析
3.1 查看源码
刚刚已经运行WordCount程序爽了一把,现在我们通过查看源码来看看该程序的真面目。
我们使用 Eclipse 来查看源码。在 hadoop-mapreduce-examples-2.7.1.jar 文件所在目录中,有一个 source 目录,其中就存有该 jar 对应的 hadoop-mapreduce-examples-2.7.1-sources.jar。通过 Eclipse 查看的情况如下:
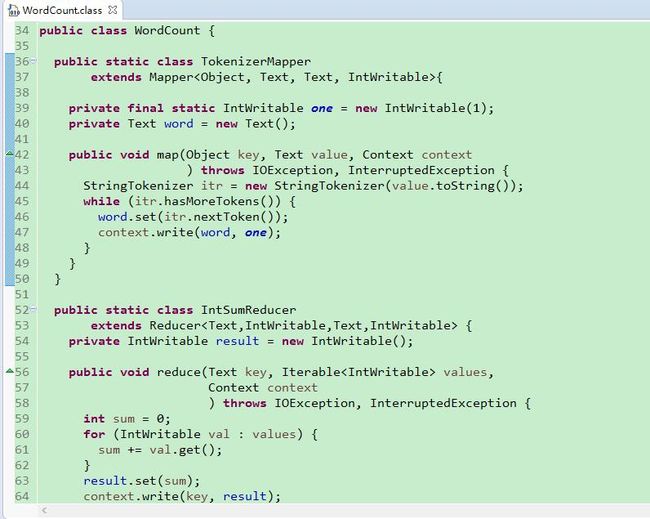
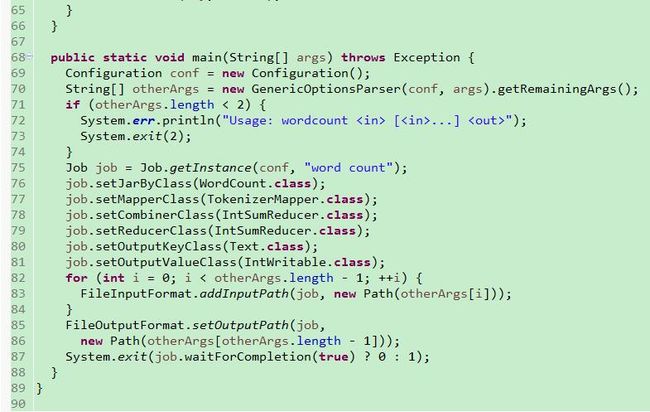
可以看到该程序很简单,代码量很少。其中内置了2个内部类,分别继承字 Mapper 和 Reducer 类。这其实就是编写 MapReduce 程序时,我们需要进行的工作。
3.2 分析程序结构
程序大概结构如下:(此处只简单说一下,待会儿在自实现的 WordCount 中进行详细的代码注释)
① Mapper 区:继承自 Mapper 类的一个内部类,实现 map() 函数
② Reducer 区:继承自 Reducer 类的一个内部类,实现 reduce() 函数
③ Client 区:程序运行入口
这个结构,也就是 MapReduce 程序编写的基本结构了。编写一个 MapReduce 程序,我们程序猿只需要实现 map() 和 reduce() 程序。
3.3 自实现 WordCount
我们按照 MapReduce 程序的编写情况,实现一个我们自己的 WordCount 程序。
① 创建一个 Java Project
② 导入如下 jar 包
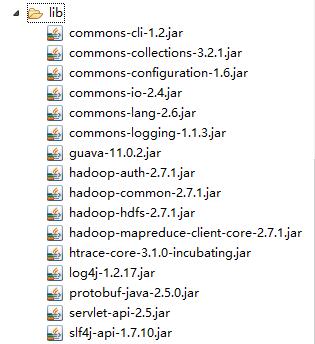
注:其中 hadoop-hdfs-2.7.1.jar 和 hadoop-mapreduce-client-core-2.7.1.jar 是编写程序需要的 jar 包,其他的 jar 包是我们在 linux 下运行程序需要的依赖 jar,也就是环境需要的 jar 包。
③ 编写程序:WordCount.java
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* WordCount:MapReduce初级案例,按八股文的结构遍写
* @author johnnie
*
*/
public class WordCount {
/**
* Mapper区: WordCount程序 Map 类
* Mapper:
* | | | |
* 输入key类型 输入value类型 输出key类型 输出value类型
* @author johnnie
*
*/
public static class TokenizerMapper extends Mapper{
// 输出结果
private Text word = new Text(); // KEYOUT
// 因为若每个单词出现后,就置为 1,并将其作为一个对,因此可以声明为常量,值为 1
private final static IntWritable one = new IntWritable(1); // VALUEOUT
/**
* value 是文本每一行的值
* context 是上下文对象
*/
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 获取每行数据的值
String lineValue = value.toString();
// 分词:将每行的单词进行分割,按照" \t\n\r\f"(空格、制表符、换行符、回车符、换页)进行分割
StringTokenizer tokenizer = new StringTokenizer(lineValue);
// 遍历
while (tokenizer.hasMoreTokens()) {
// 获取每个值
String wordValue = tokenizer.nextToken();
// 设置 map 输出的 key 值
word.set(wordValue);
// 上下文输出 map 处理结果
context.write(word, one);
}
}
}
/**
* Reducer 区域:WordCount 程序 Reduce 类
* Reducer:Map 的输出类型,就是Reduce 的输入类型
* @author johnnie
*
*/
public static class IntSumReducer extends Reducer {
// 输出结果:总次数
private IntWritable result = new IntWritable();
@Override
public void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int sum = 0; // 累加器,累加每个单词出现的总次数
// 遍历values
for (IntWritable val : values) {
sum += val.get(); // 累加
}
// 设置输出 value
result.set(sum);
// 上下文输出 reduce 结果
context.write(key, result);
}
}
// Driver 区:客户端
public static void main(String[] args) throws Exception {
// 获取配置信息
Configuration conf = new Configuration();
// 创建一个 Job
Job job = Job.getInstance(conf, "word count"); // 设置 job name 为 word count
// job = new Job(conf, "word count"); // 过时的方式
// 1. 设置 Job 运行的类
job.setJarByClass(WordCount.class);
// 2. 设置Mapper类和Reducer类
job.setMapperClass(TokenizerMapper.class);
job.setReducerClass(IntSumReducer.class);
// 3. 获取输入参数,设置输入文件目录和输出文件目录
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 4. 设置输出结果 key 和 value 的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// job.setCombinerClass(IntSumReducer.class);
// 5. 提交 job,等待运行结果,并在客户端显示运行信息,最后结束程序
boolean isSuccess = job.waitForCompletion(true);
// 结束程序
System.exit(isSuccess ? 0 : 1);
}
}
④ 编写 Main.java:我们配置一个程序执行入口,方便以后添加其他的示例,做成官方 jar 的样子
⑤ 我们将该项目打包成可执行 jar包:此处我将该 jar 取名为 WordCount.jar
⑥ 利用 FileZilla 将该 jar 包上传到 CenOS6.5 上
⑦ 利用 hadoop jar 命令来执行程序。执行命令:hadoop jar wordcount.jar WordCount ./data/f*.txt /out
注:这种传参方式就是 Linux下参数传递的方式。这里也介绍了我们平时在 Java 程序中 main() 中 args 的使用--就是来接受命令行参数的。
具体的步骤,还是和刚刚一样,准备输入文件,以及指定输出目录。输入文件和输出目录的路径都是在 HDFS 文件系统上的。./data/f*.txt 也和刚刚的 f1.txt 和 f2.txt 差不多。输出结果也不多说了,也差不多。
前往 bascker/javaworld 获取更多 Java 知识