Redis学习(7)——对象(redisObject)
一,Redis对象概述
我们知道Redis中使用了,简单动态字符串,双端链表,跳跃表,字典,压缩列表,整数集合,快速列表等数据结构,但是对于Redis,它并没用直接使用这些数据结构来实现键值对数据库,而是以它们为基础创建了一个对象系统。
- 这个对象系统包括了字符串对象、列表对象、哈希对象、集合对象和有序集合对象,这五个类型的对象。这些对象的实现都是基于上述的数据结构实现的。基于五个不同对象的键值对数据库,让Redis能够在执行对给出的命令进行判断,相应对象能否执行该命令。同时,对于不同情景下的不同对象还可以使用不同的数据结构进行实现,优化了对象在不同场景下的使用效率。
- Redis对象系统还实现了基于引用计数技术的内存回收机制,这一机制的实现使得Redis可以在不使用某个对象时及时的将其自动释放,同时还可以使得多个数据库键共享一个值对象来节约内存。
- Redis还在对象系统中实现了访问时间的记录。
二,对象类型
每次使用Redis数据库时,Redis会使用对象来表示数据库中的键和值。一个键值对就是两个对象,键就是键对象,值就是值对象。
2.1、Redis中的对象(redisObject)结构源码
这是一位在GitHub上对Redis进行解析和注释的大神的源码:https://github.com/menwengit/redis_source_annotation
#define LRU_BITS 24
#define LRU_CLOCK_MAX ((1<lru */
#define LRU_CLOCK_RESOLUTION 1000 /* LRU clock resolution in ms */
typedef struct redisObject {
//对象的数据类型,占4bits,共5种类型
unsigned type:4;
//对象的编码类型,占4bits,共10种类型
unsigned encoding:4;
//least recently used
//实用LRU算法计算相对server.lruclock的LRU时间
unsigned lru:LRU_BITS; /* lru time (relative to server.lruclock) */
//引用计数
int refcount;
//指向底层数据实现的指针
void *ptr;
} robj;
//type的占5种类型:
/* Object types */
#define OBJ_STRING 0 //字符串对象
#define OBJ_LIST 1 //列表对象
#define OBJ_SET 2 //集合对象
#define OBJ_ZSET 3 //有序集合对象
#define OBJ_HASH 4 //哈希对象
/* Objects encoding. Some kind of objects like Strings and Hashes can be
* internally represented in multiple ways. The 'encoding' field of the object
* is set to one of this fields for this object. */
// encoding 的10种类型
#define OBJ_ENCODING_RAW 0 /* Raw representation */ //原始表示方式,字符串对象是简单动态字符串
#define OBJ_ENCODING_INT 1 /* Encoded as integer */ //long类型的整数
#define OBJ_ENCODING_HT 2 /* Encoded as hash table */ //字典
#define OBJ_ENCODING_ZIPMAP 3 /* Encoded as zipmap */ //不在使用
#define OBJ_ENCODING_LINKEDLIST 4 /* Encoded as regular linked list */ //双端链表,不在使用
#define OBJ_ENCODING_ZIPLIST 5 /* Encoded as ziplist */ //压缩列表
#define OBJ_ENCODING_INTSET 6 /* Encoded as intset */ //整数集合
#define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */ //跳跃表和字典
#define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */ //embstr编码的简单动态字符串
#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of ziplists */ //由压缩列表组成的双向列表-->快速列表 2.2、对象类型
redisObject结构中的type属性记录对象的属性。有如下五种类型:
| 类型常量 | 对象 |
| OBJ_STRING 0 | 字符串对象 |
| OBJ_LIST 1 | 列表对象 |
| OBJ_SET 2 | 集合对象 |
| OBJ_ZSET 3 | 有序集合对象 |
| OBJ_HASH 4 | 哈希对象
|
在Redis中键经常是一个字符串对象,而值却可以是以上五大类型中的一种。我们可以使用TYPE命令来查看值对象的对象类型。
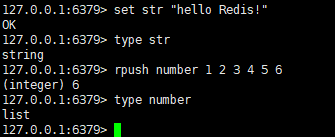
这里我们可以看到,键str对应的值对象为字符串类型,键number对应的是列表对象。
2.3、编码类型
redisObject结构中的ptr指针指向对象底层实现的数据结构,而这些数据结构有redisObject中的encoding决定。用encoding记录不同对象使用的不同编码类型,而不同的编码类型就代表了不同的数据结构。
| 类型 | 编码-encoding | 对象-ptr |
| OBJ_STRING | OBJ_ENCODING_INT | 使用整数值实现字符串对象 |
| OBJ_STRING | OBJ_ENCODING_EMBSTR | 使用embstr编码的简单动态字符串实现的字符串对象 |
| OBJ_STRING | OBJ_ENCODING_RAW | 使用简单动态字符串实现的字符串对象 |
| OBJ_LIST | OBJ_ENCODING_ZIPLIST | 使用压缩列表实现的列表对象(3.2之前版本) |
| OBJ_LIST | OBJ_ENCODING_LINKEDLIST | 使用双端链表实现对列表对象(3.2之前版本) |
| OBJ_LIST | OBJ_ENCODING_QUCIKLIST | 使用快速列表实现的列表对象(3.2之后的版本) |
| OBJ_HASH | OBJ_ENCODING_ZIPLIST | 使用压缩列表实现的哈希对象 |
| OBJ_HASH | OBJ_ENCODING_HT | 使用字典实现的哈希对象 |
| OBJ_SET | OBJ_ENCODING_INTSET | 使用整数集合实现的集合对象 |
| OBJ_SET | OBJ_ENCODING_HT | 使用字典实现的集合对象 |
| OBJ_ZSET | OBJ_ENCODING_ZIPLIST | 使用压缩列表实现的有序集合对象 |
| OBJ_ZSET | OBJ_ENCODING_SKIPLIST | 使用跳跃表实现的优秀集合对象 |
这里我们可以使用OBJECT ENCODING命令查看一个数据库对象键的值对象的编码方式。
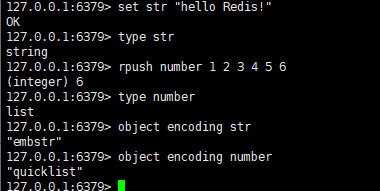
这里的键str对应的值对象为字符串对象它采用的是embstr编码的简单动态字符串实现。同理,这里的键number对应的值对象为列表对象它的编码方式为quicklist(我使用的是Redis5.0版本)
三,不同的对象对应编码方式详解
3.1、字符串对象
字符串对象的编码方式有int、raw、embstr。三种不同的类型对应不同的使用情景,且之间可以相互转换。
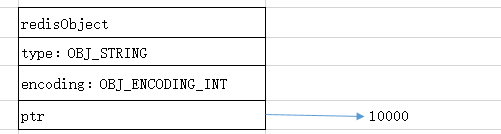
1,int(OBJ_ENCODING_INT)编码方式的使用情景:如果字符串对象保存的是整数值,且这个整数值可以用long类型表示就使用int编码方式。(注:1、字符串对象会将整数保存到ptr属性中去。2、long double类型在Redis中以字符串类型存储。3、保存浮点数会将其转换为字符串再进行保存,使用时将其转换回浮点数。)。
2,raw(OBJ_ENCODING_RAW)编码方式的使用情景:如果字符串对象保存的是一个字符串并且这个字符串长度大于32字节,那么就使用编码方式为raw的简单动态字符串来保存。
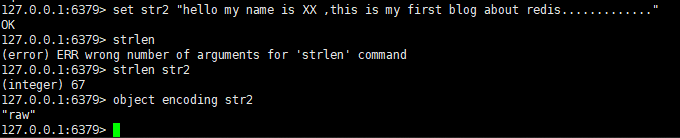

3,embstr(OBJ_ENCODING_EMBSTR)编码方式的使用情景:如果值为字符串对象,保存的是一个字符串并且这个字符串的长度小于32字节,那么就将使用编码方式为embstr的简单动态字符串保存。我们还是用OBJECT ENCODING命令查看编码方式:
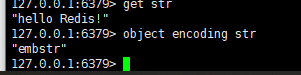
4,embstr编码和raw编码的简单动态字符串的区别
embstr和raw都是简单动态字符串的编码方式,两者有什么不同吗?
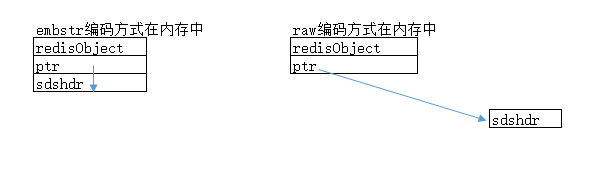
(1)、首先从保存的字符串长度由就可见不同。embstr是专门用于保存短字符串的一种优化编码方式。
(2)、采用内存分配方式不同,虽然raw和embstr编码方式都是使用redisObject结构和sdshdr结构。但是raw编码方式采用两次分配内存的方式,分别创建redisObject和sdshdr,而embstr编码方式则是采用一次分配,分配一个连续的空间给redisObject和sdshdr。(embstr一次性分配内存的方式:1,使得分配空间的次数减少。2、释放内存也只需要一次。3、在连续的内存块中,利用了缓存的优点。)
5,创建一个字符串对象(raw编码和embstr编码)源码(这里没介绍int编码源码,后面会解释)
robj *createObject(int type, void *ptr) { //创建一个默认的对象
robj *o = zmalloc(sizeof(*o)); //分配空间
o->type = type; //设置对象类型
o->encoding = OBJ_ENCODING_RAW; //设置默认的编码方式
o->ptr = ptr; //设置
o->refcount = 1; //引用计数为1
/* Set the LRU to the current lruclock (minutes resolution). */
o->lru = LRU_CLOCK(); //计算设置当前LRU时间
return o;
}
/* Create a string object with encoding OBJ_ENCODING_EMBSTR, that is
* an object where the sds string is actually an unmodifiable string
* allocated in the same chunk as the object itself. */
//创建一个embstr编码的字符串对象
robj *createEmbeddedStringObject(const char *ptr, size_t len) {
robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr8)+len+1); //分配空间
struct sdshdr8 *sh = (void*)(o+1); //o+1刚好就是struct sdshdr8的地址
o->type = OBJ_STRING; //类型为字符串对象
o->encoding = OBJ_ENCODING_EMBSTR; //设置编码类型OBJ_ENCODING_EMBSTR
o->ptr = sh+1; //指向分配的sds对象,分配的len+1的空间首地址
o->refcount = 1; //设置引用计数
o->lru = LRU_CLOCK(); //计算设置当前LRU时间
sh->len = len; //设置字符串长度
sh->alloc = len; //设置最大容量
sh->flags = SDS_TYPE_8; //设置sds的类型
if (ptr) { //如果传了字符串参数
memcpy(sh->buf,ptr,len); //将传进来的ptr保存到对象中
sh->buf[len] = '\0'; //结束符标志
} else {
memset(sh->buf,0,len+1); //否则将对象的空间初始化为0
}
return o;
}3.2、列表对象
列表对象的底层实现在3.2之前的版本采用的是ziplist和linkedlist编码方式,在3.2后的版本采用的是quicklist编码方式。我这里使用的是(Redis5.0已经是quicklist为底层实现了)
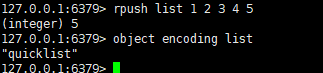
1、redisObject和quicklist和关系图:
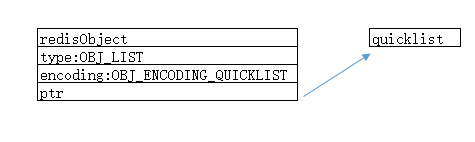
2、创建一个quicklist编码的列表对象源码
//创建一个quicklist编码的列表对象
robj *createQuicklistObject(void) {
quicklist *l = quicklistCreate(); //创建一个quicklist
robj *o = createObject(OBJ_LIST,l); //创建一个对象,对象的数据类型为OBJ_LIST
o->encoding = OBJ_ENCODING_QUICKLIST; //对象的编码类型OBJ_ENCODING_QUICKLIST
return o;
}3.3、哈希对象
哈希对象的编码可以是ziplist(OBJ_ENCODING_ZIPLIST)或者hashtable(OBJ_ENCODING_HT)。两种编码方式可以相互转换。
1、ziplist编码方式使用情景:哈希对象所保存的所有键值对的键和值的字符串长度不能大于64字节。并且哈希对象所保存的键值对数量小于512个。
图例:
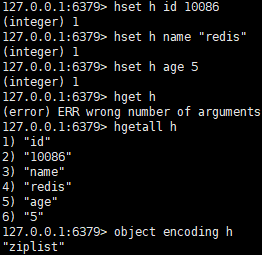
2,redisObject和ziplist编码的哈希对象的关系

3、创建一个ziplist编码的哈希对象的源码:
//创建一个ziplist编码的列表对象
robj *createZiplistObject(void) {
unsigned char *zl = ziplistNew(); //创建一个ziplist
robj *o = createObject(OBJ_LIST,zl); //创建一个对象,对象的数据类型为OBJ_LIST
o->encoding = OBJ_ENCODING_ZIPLIST; //对象的编码类型OBJ_ENCODING_ZIPLIST
return o;
}4,hashtable编码的使用情景:当不符合ziplist编码情景的时候就用hashtable编码。
图例:(演示了一个值的长度超过64的情况)

5,redisObject和hashtable编码的哈希对象的关系
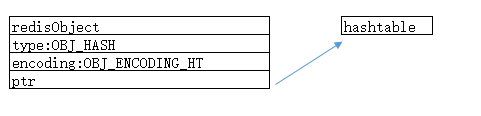
6、创建一个hashtable编码的哈希对象源码
//创建一个ht编码的集合对象
robj *createSetObject(void) {
dict *d = dictCreate(&setDictType,NULL);//创建一个字典
robj *o = createObject(OBJ_SET,d); //创建一个对象,对象的数据类型为OBJ_SET
o->encoding = OBJ_ENCODING_HT; //对象的编码类型OBJ_ENCODING_HT
return o;
}3.4、集合对象
集合对象的编码方式有inset(OBJ_ENCODING_INSET)和hashtable(OBJ_ENCODING_HT),可以转换。但一般都是inset编码方式转为hashtable编码方式。
1、inset编码方式使用情景:集合对象使用整数集合作为底层实现,集合包含的所有元素都被保存在整数集合中。并且集合对象保存的元素数量不得超过512个。
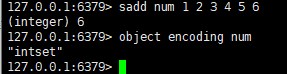
2、redisObject和intset编码的集合对象的关系
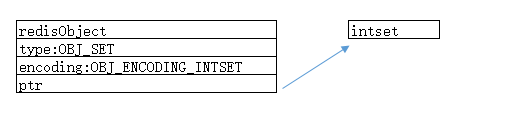
3、创建inset编码方式的集合对象源码:
//创建一个intset编码的集合对象
robj *createIntsetObject(void) {
intset *is = intsetNew(); //创建一个整数集合
robj *o = createObject(OBJ_SET,is); //创建一个对象,对象的数据类型为OBJ_SET
o->encoding = OBJ_ENCODING_INTSET; //对象的编码类型OBJ_ENCODING_INTSET
return o;
}4,hashtable编码使用情景:当不满足inset编码方式时就采用hashtable编码方式,当然还会出现由inset编码转为hashtable的情景。

5,redisObject和hashtable编码的集合对象的关系
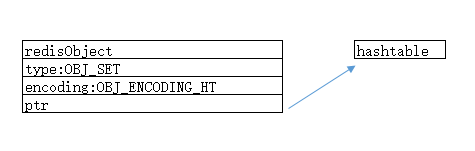
6,创建一个以hashtable编码的集合对象源码
//创建一个ht编码的集合对象
robj *createSetObject(void) {
dict *d = dictCreate(&setDictType,NULL);//创建一个字典
robj *o = createObject(OBJ_SET,d); //创建一个对象,对象的数据类型为OBJ_SET
o->encoding = OBJ_ENCODING_HT; //对象的编码类型OBJ_ENCODING_HT
return o;
}3.5、有序集合对象
有序集合采用的编码方式为ziplist和skiplist。两者可以转换。
1,ziplist编码方式使用情景:有序集合保存元素小于128时,并且集合中保存的元素长度小于64字节。
当然,不满足上述情况就使用skiplist编码方式。

2、创建一个使用ziplist或者skiplist编码的集合对象源码
//创建一个skiplist编码的有序集合对象
robj *createZsetObject(void) {
zset *zs = zmalloc(sizeof(*zs));
robj *o;
zs->dict = dictCreate(&zsetDictType,NULL); //创建一个字典
zs->zsl = zslCreate(); //创建一个跳跃表
o = createObject(OBJ_ZSET,zs); //创建一个对象,对象的数据类型为OBJ_ZSET
o->encoding = OBJ_ENCODING_SKIPLIST; //对象的编码类型OBJ_ENCODING_SKIPLIST
return o;
}
//创建一个ziplist编码的有序集合对象
robj *createZsetZiplistObject(void) {
unsigned char *zl = ziplistNew(); //创建一个ziplist
robj *o = createObject(OBJ_ZSET,zl); //创建一个对象,对象的数据类型为OBJ_ZSET
o->encoding = OBJ_ENCODING_ZIPLIST; //对象的编码类型OBJ_ENCODING_ZIPLIST
return o;
}4,编码转换
什么是编码转换呢?
前面我们知道每一个对象都有不同的编码方式实现。而每个对象之间的不同的编码方式之间可以转换,这就是编码转换。
至于什么时候进行编码转换呢?
当然就是不满足某一个编码方式的使用情景时,就进行编码转换。
如:字符串对象有三种编码方式(int,embstr,raw)。而其中int、embstr编码会在不满足其使用条件时转为raw编码方式。我们知道,int(OBJ_ENCODING_INT)编码方式的使用情景:如果字符串对象保存的是整数值,且这个整数值可以用long类型表示就使用int编码方式。而通过APPEND命令在保存整数值的字符串对象后面加一个字符串,程序就会将原本的保存的整数变为字符串保存,编码方式也由int编码变为了raw编码。
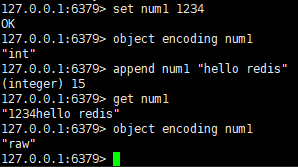
同理,其他类型的编码方式在不满足其使用情景时也将进行编码转换。
5,内存回收机制
我们知道,C语言本身不想Java有内存自动回收机制。但是,在开始的时候曾说到Redis的对象系统采用计数技术实现了内存回收机制。Redis也通过这一机制通过跟进对象的引用计数信息,在适当的时候进行内存回收。而计数信息在redisObject结构中由refcount属性记录。
typedef struct redisObject {
//对象的数据类型,占4bits,共5种类型
unsigned type:4;
//对象的编码类型,占4bits,共10种类型
unsigned encoding:4;
//least recently used
//实用LRU算法计算相对server.lruclock的LRU时间
unsigned lru:LRU_BITS; /* lru time (relative to server.lruclock) */
//引用计数
int refcount;
//指向底层数据实现的指针
void *ptr;
} robj;- 当新建一个对象时,refcount的值被初始化为1.
- 当对象被一个新程序引用时,refcount+1.
- 当对象不再被一个程序引用时,refcount-1.
最终当refcount为0时,对象占的内存被释放。
6,对象共享
通过计数技术实现的不仅仅是内存回收机制,还有对象共享。
何为对象共享?
对象共享指的是,当创建了一个键A时,它的值对象保存整数100。而这时再创建一个键B时,同样值对象保存为1整数100。这时Redis就会让键A,B共享保存100的值对象。
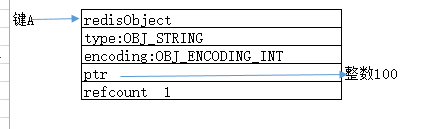
键A,B共有值对象100

Redis中实现对象共享步骤
- 将数据库键的值指针指向一个现有的值对象
- 将被共享的值对象的refcount属性+1.
对象共享能够节约内存。共享对象越多节约效果越显著。
在Redis服务器启动时,会创建一万个字符串对象,这些字符串对象包含了0—9999的整数,因此这也解释了前面为何没有in编码的字符串对象的创建,因为已经创建好了,只需要共用即可。