【论文解读】 FPGA实现卷积神经网络CNN(三) 深鉴科技: Going Deeper with Embedded FPGA Platform for CNN
博主评论:深鉴科技是国内做FPGA实现CNN的高端玩家,2018年被Xilinx收购,现在专做移动端的深度学习加速,开发了端到端的深度学习加速框架DNNDK,博主实测加速效果(ZCU102开发板;计算能力>1.2Tops/s,引入ARM多线程可进一步达到>2Tops/s)。这篇2016年的文章是深鉴科技早期实现卷积神经网络加速的一篇硬核论文,文章写得很深入,这里只做个简要解读~
论文地址:https://nicsefc.ee.tsinghua.edu.cn/media/publications/2016/FPGA2016_None_6tAJnDW.pdf
目录
摘要:
1,介绍
2,CNN背景
3,已有的相关工作
3.1 模型压缩
3.2 数据量化
3.3 CNN加速器
4,CNN复杂性分析
5,数据量化
5.1 量化流程
5.2 不同量化策略的分析
6,系统设计
6.1 整体结构
6.2 PE结构
6.3 运行细节
6.3.1 Workloads Schedule
6.3.2 Controller System
7,内存系统
7.1 缓存设计
7.2 卷积层数据安排策略
7.3 全连接层数据安排策略
8,系统评估
8.1 理论评估
8.2 表现分析
摘要:
指出FPGA用作CNN加速器有很好的前景,但是有限的带宽和片上内存大小限制了FPGA的表现。我们对当前最先进的CNN进行深度分析,发现卷积层占用大量计算资源,全连接层占用大量内存资源。我们使用动态精度数据量化方法,并且提出一个对CNN中所有层有效的通用卷积器。我们采用4位或8位动态量化精度在深层VGG16网络上只下降了0.4%的精度。为了更好地利用外部储存带宽,我们提出了一个data-arrange method。最终我们使用16位精度在ZCU706上推断VGG-SVD网络获得了4.45fps,top-5 accuracy为86.66%;卷积层和全部层的算力表现分别为:187.8Gop/s和137Gop/s,使用150MHz工作频率。
1,介绍
当前先进的CNN模型都极其复杂,模型大多都只能放在外部储存中,因此,在嵌入式系统上加速CNN,外部储存与片上存储间的带宽变成了一个严重的问题。并且以前的研究只专注于卷积层,在全连接层仍有很多可以改进的地方。
我们的工作包括:
1. 对VGG16进行深入分析,发现其有1.38亿个权重,需要超过30G运算量,卷积层占用大量计算资源,全连接层占用大量内存资源。
2. 我们第一次提出动态精度数据量化的自动流程,并考察不同的数据量化配置。我们对VGG16模型使用8/4位动态定点量化只带来了0.4%的精度损失。对于动态精度量化,我们使用了特别的硬件设计。
3. 我们对第一层全连接层权重使用奇异值分解(SVD),降低了85.8%的存储资源消耗,设计可以用于计算全连接层的卷积器,减少资源消耗,提出了一种数据管理策略来加速全连接层。
2,CNN背景
3,已有的相关工作
软件方面在尽量少得损失精度下压缩网络;硬件方面设计特有模块和结构提供数据重用,增强数据“本地性”,加速卷积计算。
3.1 模型压缩
剪枝可以减少模型复杂度,可以避免过拟合。
3.2 数据量化
使用更少位数的定点数表示权重可以减少内存占用与计算资源占用,在【7】的工作中,将32位数用16位数代替,在mnist数据集上只引入了0.26%的精度损失。
在FPGA上,数据量化策非常重要。
3.3 CNN加速器
设计CNN加速器主要关注两个方面,一是优化计算引擎,二是优化内存系统。
4,CNN复杂性分析
在CNN推断过程中,我们使用计算一个卷积层所需要的乘法次数来评估时间复杂度。
假设一个具体的卷积层,卷积核大小![]() ,输入/出特征图大小R*C,输入通道数
,输入/出特征图大小R*C,输入通道数![]() ,,输出通道数
,,输出通道数![]() ,则时间复杂度:
,则时间复杂度:
![]() ,
,
池化层的时间复杂度:
![]() ,
,
全连接层的时间复杂度:
![]() ;
;
空间复杂度代表权重参数所占用内存大小,具体的:
卷积层空间复杂度:![]() ;
;
全连接层空间复杂度:![]() ;
;
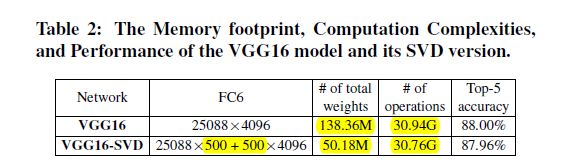
下图是对当前先进CNN模型的计算量与参数统计:

采用矩阵奇异值分解(SVD)的方法降低全连接层的内存占用,降低了7倍参数量,只引入了0.04%的损失。
5,数据量化
在FPGA上使用短的定点数(short fixed-point numbers)代替长的浮点数(long floating-point numbers)可以显著降低内存占用和带宽占用,我们提出动态-精度数据量化策略,并与已经广泛使用的静态-精度数据量化策略做对比。
5.1 量化流程
将定点数转换为十进制数的公式为:
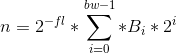 ,其中
,其中![]() 是定点数的位宽,
是定点数的位宽,![]() 是小数位的长度(量化精度),可以为负数。(为什么可以为负数?) 关于定点数与浮点数的转换,大家不了解的可以点这里。
是小数位的长度(量化精度),可以为负数。(为什么可以为负数?) 关于定点数与浮点数的转换,大家不了解的可以点这里。
![]() 是动态精度量化的关键,作者指出在CNN不同层之间,不同特征图之间使用动态的
是动态精度量化的关键,作者指出在CNN不同层之间,不同特征图之间使用动态的![]() 值;而在同一层中,同一特征图之内使用静态的
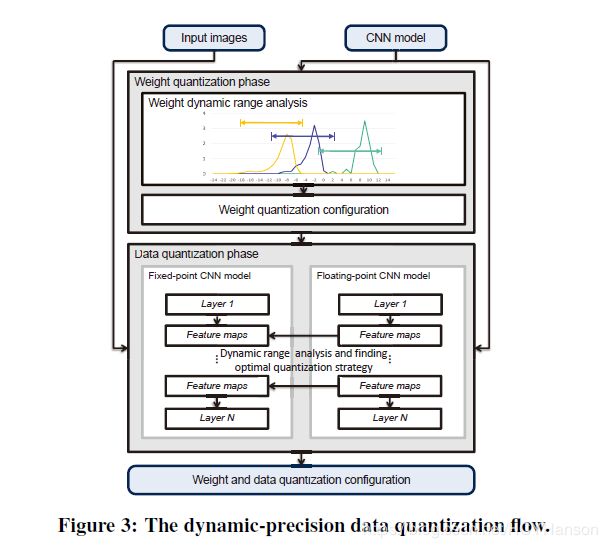
值;而在同一层中,同一特征图之内使用静态的![]() ,从而最小化每一层/特征图之内的截断误差。权重与特征图量化流程如图:
,从而最小化每一层/特征图之内的截断误差。权重与特征图量化流程如图:
权重量化是找到在一层中最优的![]() ,公式:
,公式:

![]() 为浮点权重,
为浮点权重,![]() 是量化后权重,求一层内量化误差之和的最小值所对应的
是量化后权重,求一层内量化误差之和的最小值所对应的![]() ;初始
;初始![]() 应避免数据溢出,并且我们从初始
应避免数据溢出,并且我们从初始![]() 的邻域开始查找最优解。
的邻域开始查找最优解。
特征图量化是为两层之间的特征图找到最优的![]() ,使用贪婪算法一层层的比较原始浮点模型与定点模型的中间数据,以减少精度损失,公式:
,使用贪婪算法一层层的比较原始浮点模型与定点模型的中间数据,以减少精度损失,公式:


(这一段解释不是很明白,![]() ,A是什么?)
,A是什么?)
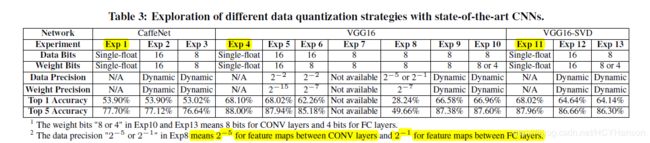
动态精度量化与其它静态精度量化的比较:
5.2 不同量化策略的分析
作者指出在VGG16中,采用8位量化至少要用2位量化精度,否则精度衰减的很厉害。
最终分析得出动态精度量化比静态精度量化更有利。
6,系统设计
6.1 整体结构
先来一张总览图(非常精细的设计):

在图4(a)中,DMA作为PS(CPU+DDR)端与PL(FPGA)端通信的中介,担起传输计算数据与控制指令的任务;
整体推断过程包括数据准备,数据处理,结果输出三个阶段;尤其数据处理部分:DMA每一次加载数据和指令给controller,就会触发PL上的一次计算进程,在PS端每一次DMA中断被断言,就会将buffer descriptors(BD)的指针增加一位(也就是每次在PS端将DDR里面的地址指针指向新的数据段进行传送),直到所有的BD都被传送完。
6.2 PE结构
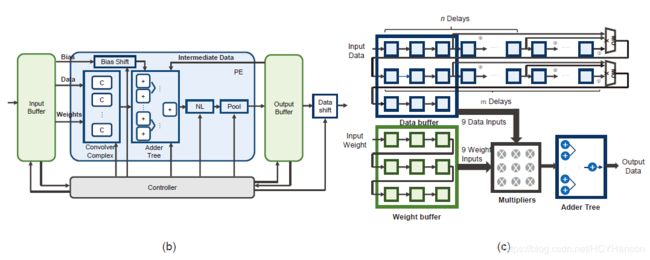
PE图(b)由五部分组成,包括Convolver 复合体,Adder Tree,Nonlinearity模块,Max-Pooling模块和Bias Shift。
- 对于convolver复合体,使用经典的line buff设计,当输入图像以行优先模式通过line buff时,line buff在输入图像上产生窗口选择函数。跟在窗口后面的乘法树和加法树将会计算卷积结果,每个时钟周期出一个数据。因为全连接层的瓶颈是带宽,即使在对全连接层计算效果一般的情况下,我们仍然使用这个模块计算矩阵向量乘法。为了实现窗口选择函数,通过每个line buff后面的数据选择器(MUX)来设置:每个line buff每一行的延迟和filter size一样大,当前方案filter size=3。当输入数据通过line buff时,每9个时钟周期我们在一个被挑选的窗里面得到新的向量,并做向量内积。因此一个convolver做向量大小为9的矩阵乘法,也就是3*3的矩阵乘法。(这一段翻译不太准,贴上原文)

- 加法树(AD)汇总了卷积器的所有结果。如果需要, 它可以从输出缓冲区添加中间数据或从输入缓冲区添加偏置数据。
- 非线性(NL)模块应用非线性激活函数输入数据流。
- Max-Pooling模块利用行缓冲区来应用特定的2×2窗口到输入数据流,并输出其中最大的值。
- 偏移模块(Bias Shift)和数据移位模块(Data Shift)旨在实现支持动态量化。 根据一层的量化结果通过Bias Shift对输入偏差进行移位。 对于一个16位的运行,为了和卷积结果相加到一起,Bias Shift将偏差扩展到32位。 输出数据将被移位通过Data Shift并切回原始宽度。(贴上原文)

在VGG16里面,所有的卷积核大小都为3*3.
6.3 运行细节
6.3.1 Workloads Schedule
CNN工作负载中的三种并行性:操作符级并行性(精细并行,即计算单个3*3卷积运算的内部并行 ),输出内并行性(多输入特征图谱结合以创建单个输出,即计算一个卷积核内不同维度卷积运算的并行),和输出间平行(多个独立特征同时计算 ,即计算多个卷积核之间的卷积并行) ; 在我们的实现中,所有三种类型的并行性都被考虑。 使用2D-convolver完成操作符级并行, 在一个PE中同时使用多个2D-convolver完成输出内并行,使用多个PE完成输出间并行。
分片和重用:由于片上存储器有限,分片是必要的。 对于CONV层中的分片,我们对图像按照每个输入行(列)中的因子Tr(Tc)分片。 我们对特征图谱按照输入(输出)Nin(Nout)的因子Ti(To)分片。 对于FC我们将每个矩阵拼贴成Ti×To的分块。 为了重用,每个输入分块(向量)的重复次数是reuse_times。 下图显示此工作负载计划机制如何应用于CONV层和FC层。

6.3.2 Controller System
主要介绍了一些特有的指令,从而对整个系统进行控制,也可以给系统不同的参数进行运行。(体现了深鉴科技早期就想要做一套灵活的深度学习加速工具链而不是只针对某个算法做硬件上的优化)
7,内存系统
我们将介绍其中的内存系统设计,旨在有效地为PE提供数据。 首先是设计buffer介绍。 之后,给出了CONV层和FC层的有效数据安排机制。
7.1 缓存设计
如图4(a)所示,有两个片上缓冲器在PL侧,输入缓冲器和输出缓冲器。 输入缓冲区存储偏差,图像数据和权重。 输出缓冲区保存
从PE生成的结果并在适当的时间提供中间结果给PE。 为简单起见,定义了三个参数如图7所示:
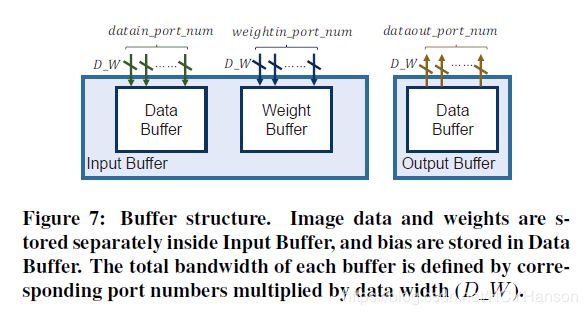
- datain_port_num。 每个周期可以通过DMA传输的最多输入特征图数据。
- weightin_port_num。 每个周期可以通过DMA传输的最多权重数据。
- dataout_port_num。 每个周期可以通过DMA传输的最多输出特征图数据。
在CONV层中,每阶段所需的权重数据总量远小于图像数据,而在FC层中,每阶段权重数据量远远超过输入数据量。 因此,我们将FC层的权重保存在数据缓冲区中(data buffer),其存储能力大于权重缓冲区(weight buffer),并保存输入数据向量到权重缓冲区。
7.2 卷积层数据安排策略
为了减少外部内存不必要的访问延迟,我们优化了内存中数据的存储模式。 原理是最大化每个DMA的数据传输量。 图8显示了我们如何组织具有最大池化的一个CONV层中的输入和输出数据。对于每个图片,我们将分片存储在连续的相对位置, 因此,在每个阶段,我们都可以同时加载所有输入分片用于连续计算。 输出特征图将是下一层的输入特征图,因此,对于下一层来说相同存储模式也适用。
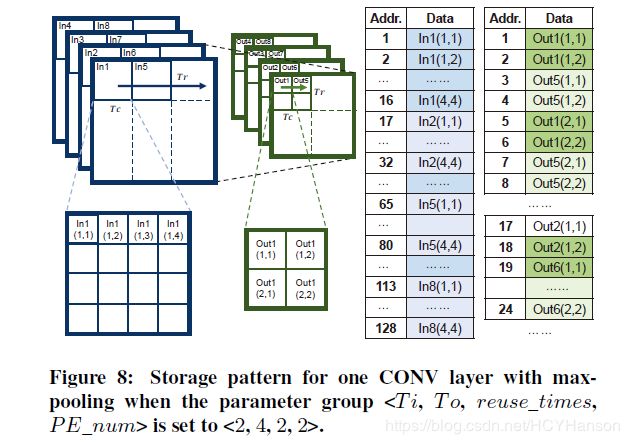
包含池化的CONV层和其它卷积层存在细微差别。 在2×2池化后,结果是原来分片的1/4大小。 在图8中,在Out(1,1)之后,先计算Out(2,1)而不是Out(1,2)。 这意味着相邻的结果分块不是连续存储在外部存储器中。 如果我们在每个结果分块计算完成后就写出到储存器,burst length将仅为Tr/ 2。 这将显着降低外部存储器的利用率。为了解决这个问题,我们增加了芯片上的内存预算。 我们在生成Out(1,2)之前先缓冲Out(1,1)到Out(4,1),然后再将Out(1,1)和Out(1,2)一起写出到储存器,这种策略增加了burst length为Tr×Tc / 2。
7.3 全连接层数据安排策略
计算FC层的速度主要受限于带宽。 以这种方式,使用特定硬件来加速FC层是无效的。 考虑到这一点,建对于FC层议系统在其中一个PE中使用Convolver Complex进行计算。 在这种情况下,我们需要充分利用当前PL结构的外部存储器的带宽。
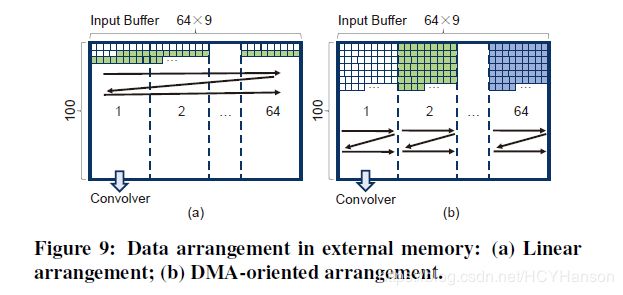
在我们的系统中,我们分配一个长度为900的缓冲区,与在一个PE的64个计算复合体中每一个Tr×Tr相同。 缓冲区是在计算CONV层时逐个填充。 为了减少用于填充缓冲区的额外数据布线逻辑,同时保持较长的burst length,当获取用于计算FC层的数据时,我们安排权重外部存储器中的矩阵。 我们首先划分整个矩阵具有64×9列和100行的块,使得一个阶段可以处理一个块。 在每个块中,数据排列为如图9(b)所示。 如图9(a)所示,在没有FC层的数据排列时,burst length 只有9,我们需要64×100 次的DMA transaction加载一个块,而通过在图9(b)之后排列数据,我们只需要一次DMA transaction就能加载整个块,long burst length确保了外部存储器带宽的高利用率。
8,系统评估
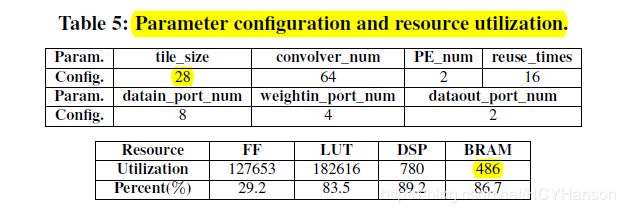
参数配置及资源使用情况:
8.1 理论评估
经过一系列公式变换(原文有详细推导过程),作者得出:
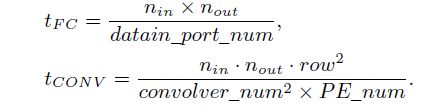
从公式上证明了FC的运行时间受限于带宽,而CONV的运行时间受限于带宽和计算资源。
8.2 表现分析
和cpu,mgpu,GPU做对比

与其它FPGA加速器进行比较
