HttpMessageConveter: 将请求消息(如Json、xml等数据)转换成一个对象,将对象转换为指定的响应信息。 数据转换:对请求消息进行数据转换。如String转换成Integer、Double等。 数据根式化:对请求消息进行数据格式化。 如将字符串转换成格式化数字或格式化日期等。 数据验证: 验证数据的有效性(长度、格式等),验证结果存储到BindingResult或Error中。
java开发网易电话面试 一面总结
java开发网易电话面试 一面总结
晚上八点多自己在看视频的时候突然接到杭州来的一个电话,当时觉得很奇怪,突兀,接通之后被告知是杭州网易打来的,没有简单的自我介绍,没有多余的废话,直接入主题,吓得我心里怪紧张的,完全没有准备,但是也没有办法,还是得硬上!
1、项目结构。
没有缓和的时间,面试官直接问我简历上某个项目的情况,简要的说了下算是缓解心情,问了下使用的相关的技术,比如用了spring mvc框架没 数据库是用的什么 这些可能就是面试官给的缓和时间吧,但是,我是这样越缓和越紧张了,悲催。。。
2、用过mybatis没?因为没怎么用过,所以面试官就没怎么问了。。。
3、集合框架hashtable、hashmap、list、list初始化大小、hashmap自动增长
答:一开始是直接问了解常用的集合框架么,这个一听到肯定说了解咯,于是就让说说hashtable、hashmap、list的区别,所以就大致展开说了下:
ArrayList和Vector的区别:
共同点:这两个类都实现了List接口(List接口继承了Collection接口),他们都是有序集合,即存储在这两个集合中的元素的位置都是有顺序的,相当于一种动态的数组,我们以后可以按位置索引号取出某个元素,并且其中的数据是允许重复的,这是与HashSet之类的集合的最大不同处,HashSet之类的集合不可以按索引号去检索其中的元素,也不允许有重复的元素。
接着说ArrayList与Vector的区别,这主要包括两个方面:.
同步性:Vector是线程安全的,也就是说是它的方法之间是线程同步的,而ArrayList是线程序不安全的,它的方法之间是线程不同步的。如果只有一个线程会访问到集合,那最好是使用ArrayList,因为它不考虑线程安全,效率会高些;如果有多个线程会访问到集合,那最好是使用Vector,因为不需要我们自己再去考虑和编写线程安全的代码。
注意:这里谈到线程安全,同步问题,面试官少不了会多嘴说一句,让你讲讲线程安全是咋回事,如果不考虑,你听到这个问题估计会是一脸懵逼,我当初就是这样子的!所以这里我补充下线程安全的问题: java中的线程安全就是线程同步的意思,就是当一个程序对一个线程安全的方法或者变量进行访问的时候,其他的程序不能再对他进行操作了,必须等到这次访问结束以后才能对这个线程安全的方法进行访问,否则将会造成错误发生;线程安全就是说,如果你的代码所在的进程中有多个线程在同时运行,而这些线程可能会同时运行这段代码。如果每次运行结果和单线程运行的结果是一样的,而且其他的变量的值也和预期的是一样的,就是线程安全的。 线程安全问题都是由全局变量及静态变量引起的,定义在方法内部的局部私有变量是没有线程安全与否一说的。
备注:对于Vector&ArrayList、Hashtable&HashMap,要记住线程安全的问题,记住Vector与Hashtable是旧的,是java一诞生就提供了的,它们是线程安全的,ArrayList与HashMap是java2时才提供的,它们是线程不安全的。所以,我们讲课时先讲老的。
数据增长:ArrayList与Vector都有一个初始的容量大小,当存储进它们里面的元素的个数超过了容量时,就需要增加ArrayList与Vector的存储空间,每次要增加存储空间时,不是只增加一个存储单元,而是增加多个存储单元,每次增加的存储单元的个数在内存空间利用与程序效率之间要取得一定的平衡。Vector默认增长为原来两倍,而ArrayList的增长策略在文档中没有明确规定(从源代码看到的是增长为原来的1.5倍)。ArrayList与Vector都可以设置初始的空间大小,Vector还可以设置增长的空间大小,而ArrayList没有提供设置增长空间的方法。
总结:即Vector增长原来的一倍,ArrayList增加原来的0.5倍。 PS:因为在上面讲区别的时候提到了自动增长的问题,所以面试官顺带问了句,hashmap自动增长为多少,这个问题说实话,自己没有关注过,平时也没注意过,所以只能老实的说不知道咯,面后网上查了下,不确定是否正确,有说1.6版本的是增长2倍!
ArrayList,Vector, LinkedList的存储性能和特性:
ArrayList和Vector都是使用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,它们都允许直接按序号索引元素,但是插入元素要涉及数组元素移动等内存操作,所以索引数据快而插入数据慢,Vector由于使用了synchronized方法(线程安全),通常性能上较ArrayList差,而LinkedList使用双向链表实现存储,按序号索引数据需要进行前向或后向遍历,但是插入数据时只需要记录本项的前后项即可,所以插入速度较快。LinkedList也是线程不安全的,LinkedList提供了一些方法,使得LinkedList可以被当作堆栈和队列来使用。
List和Map的区别:
一个是存储单列数据的集合,另一个是存储键和值这样的双列数据的集合,List中存储的数据是有顺序,并且允许重复;Map中存储的数据是没有顺序的,其键(key)是不能重复的,它的值(value)是可以有重复的,存值采用 put(key,value)。Map中取值:value=m.get(key)(这个面试官常问,虽然不难,但也得注意)
HashMap和Hashtable的区别:
HashMap把Hashtable的contains方法去掉了,改成containsvalue和containsKey。因为contains方法容易让人引起误解。
一.历史原因:Hashtable是基于陈旧的Dictionary类的,HashMap是Java 1.2引进的Map接口的一个实现
二.同步性:Hashtable是线程安全的,也就是说是同步的,而HashMap是线程序不安全的,不是同步的
三.值:只有HashMap可以让你将空值作为一个表的条目的key或value,即HashMap允许将null作为一个entry的key或者value,而Hashtable不允许。
PS:最后面试官有问到list初始化大小为多少,也就是说默认是多少,这个其实问的是 List list = new ArrayList() 这里初始化 数组的大小是多少,根据源码我们知道,默认大小为10.
4、多线程 wait()sleep()
答:聊到多线程,大致先问了多线程的实现方式,这个问题不用多说,很简单,java提供了两种方式,一个是继承Thread类,另一个是实现Runnable接口,由于java不支持多继承,所以在多继承的时候,我们得优先选用 实现 Runnable接口,因为我们可以通过实现接口的办法,间接的实现多继承!【问了实现方式之后面试官又问了这两种方法的使用】,其次问到了wait()和sleep()的区别,这两个方法区别在于:sleep()是Thread类的,而wait()是Object类的,sleep是睡眠,指定时间后线程会继续执行,不放弃对cpu资源的占用(即不放弃对象锁),相当于暂停指定t,wait()是等待,需要唤醒,它会释放对cpu资源的占用(即会放弃对象锁),调用notify()和notifyAll()唤醒。
5、spring mvc框架结构 spring过滤器、登录过滤 spring mvc分层 spring注解
答:首先问到的是spring mvc框架,让我讲下其组成及功能,由于当时思路有点凌乱,我主动提出这个问题留到最后讲!接下来面试官问了,spring过滤器,就简单问了下我一般用过滤器做什么,我回答一般处理字符以及编码,显然这不是面试官要的结果,于是面试官提示,加入你在做一个登陆注册系统,怎么用过滤器来验证是否匹配,我直接脱口而出查数据库啦,说完后自己都笑了,至于最后要问的是什么这里我好想也忘了,好想提到什么controller 我说是的,然后应该没答错了,接下来就问到了spring的注解问题,说自己常用的注解有哪些,这里我大致讲了一些,总结摘录如下:
Spring自带依赖注入注解
1 @Required:依赖检查;
2 @Autowired:自动装配2 自动装配,用于替代基于XML配置的自动装配 基于@Autowired的自动装配,默认是根据类型注入,可以用于构造器、字段、方法注入
3 @Value:注入SpEL表达式 用于注入SpEL表达式,可以放置在字段方法或参数上
@Value(value = "SpEL表达式")
@Value(value = "#{message}")
4 @Qualifier:限定描述符,用于细粒度选择候选者
@Qualifier限定描述符除了能根据名字进行注入,但能进行更细粒度的控制如何选择候选者
@Qualifier(value = "限定标识符")
JSR-250注解
1 @Resource:自动装配,默认根据类型装配,如果指定name属性将根据名字装配,可以使用如下方式来指定
@Resource(name = "标识符")
字段或setter方法
2 @PostConstruct和PreDestroy:通过注解指定初始化和销毁方法定义
JSR-330注解
1 @Inject:等价于默认的@Autowired,只是没有required属性
2 @Named:指定Bean名字,对应于Spring自带@Qualifier中的缺省的根据Bean名字注入情况
3 @Qualifier:只对应于Spring自带@Qualifier中的扩展@Qualifier限定描述符注解,即只能扩展使用,没有value属性
JPA注解
@PersistenceContext
@PersistenceUnit用于注入EntityManagerFactory和EntityManager
具体这里不详细展开,大家可以参考一些专门针对注解的文章!
好了,接下来就提到spring mvc的分层了,总结如下:
使用Java spring进行MVC模式开发时,往往将数据模型分为两部分,即DAO(Data Access Object,数据访问对象)和Service(业务逻辑模型)。在第2步中,控制器向模型请求数据时,并不是直接向DAO请求数据,而是通过Service向DAO请求数据。这样做的好处是,可以将业务逻辑与数据库访问独立开,为将来系统更换数据保存介质(如目前系统使用文件系统存储数据,将来可以更换为使用数据库存储,又或者是现在使用了MSSQL存储数据,将来更换为MySQL等)提供了很大的灵活性。控制器只需要调用Service接口中的方法获取或是处理数据,Service层对控制器传入的数据进行业务逻辑处理封装后,传给DAO层,由DAO层负责将处理后的数据写入数据库中。在Service层使用了抽象工厂模式来实现Service层与DAO层的低耦合,Service层并不知道DAO层是如何实现的,实际上也不需要知道系统使用了哪种数据库或是文件系统。
action(控制器)、Dao(数据访问层)、Service(业务逻辑)!view层(视图 jsp之类的)!
最后就得言归正传了,回到spring mvc框架的结构上来,大概是照着下面总结的:
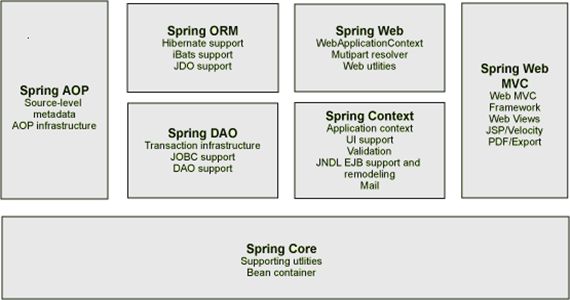
核心容器 核心容器提供 Spring 框架的基本功能。核心容器的主要组件是 BeanFactory,它是工厂模式的实现。BeanFactory 使用控制反转 (IOC) 模式将应用程序的配置和依赖性规范与实际的应用程序代码分开。
Spring 上下文 Spring 上下文是一个配置文件,向 Spring 框架提供上下文信息。Spring 上下文包括企业服务,例如 JNDI、EJB、电子邮件、国际化、校验和调度功能。
Spring AOP 通过配置管理特性,Spring AOP 模块直接将面向方面的编程功能集成到了Spring 框架中。所以,可以很容易地使 Spring 框架管理的任何对象支持 AOP。Spring AOP 模块为基于 Spring 的应用程序中的对象提供了事务管理服务。通过使用 Spring AOP,不用依赖 EJB 组件,就可以将声明性事务管理集成到应用程序中。
Spring DAO JDBC DAO 抽象层提供了有意义的异常层次结构,可用该结构来管理异常处理和不同数据库供应商抛出的错误消息。异常层次结构简化了错误处理,并且极大地降低了需要编写的异常代码数量(例如打开和关闭连接)。Spring DAO 的面向 JDBC 的异常遵从通用的 DAO 异常层次结构。
Spring ORM Spring 框架插入了若干个 ORM 框架,从而提供了 ORM 的对象关系工具,其中包括 JDO、Hibernate 和 iBatis SQL Map。所有这些都遵从 Spring 的通用事务和 DAO 异常层次结构。
Spring Web 模块 Web 上下文模块建立在应用程序上下文模块之上,为基于 Web 的应用程序提供了上下文。所以,Spring 框架支持与 Jakarta Struts 的集成。Web 模块还简化了处理多部分请求以及将请求参数绑定到域对象的工作。
Spring MVC 框架 MVC 框架是一个全功能的构建 Web 应用程序的 MVC 实现。通过策略接口,MVC 框架变成为高度可配置的,MVC 容纳了大量视图技术,其中包括 JSP、Velocity、Tiles、iText 和 POI。
Spring 框架的功能可以用在任何 J2EE 服务器中,大多数功能也适用于不受管理的环境。Spring 的核心要点是:支持不绑定到特定 J2EE 服务的可重用业务和数据访问对象。毫无疑问,这样的对象可以在不同 J2EE 环境 (Web 或 EJB)、独立应用程序、测试环境之间重用。
PS:题外要知道的:SpringMVC工作流程描述
-
向服务器发送HTTP请求,请求被前端控制器 DispatcherServlet 捕获。
-
DispatcherServlet 根据
-servlet.xml 中的配置对请求的URL进行解析,得到请求资源标识符(URI)。 然后根据该URI,调用 HandlerMapping 获得该Handler配置的所有相关的对象(包括Handler对象以及Handler对象对应的拦截器),最后以 HandlerExecutionChain 对象的形式返回。 -
DispatcherServlet 根据获得的Handler,选择一个合适的 HandlerAdapter。(附注:如果成功获得HandlerAdapter后,此时将开始执行拦截器的preHandler(…)方法)。
-
提取Request中的模型数据,填充Handler入参,开始执行Handler(Controller)。 在填充Handler的入参过程中,根据你的配置,Spring将帮你做一些额外的工作:
-
Handler(Controller)执行完成后,向 DispatcherServlet 返回一个 ModelAndView 对象;
-
根据返回的ModelAndView,选择一个适合的 ViewResolver(必须是已经注册到Spring容器中的ViewResolver)返回给DispatcherServlet。
-
ViewResolver 结合Model和View,来渲染视图。
-
视图负责将渲染结果返回给客户端。
6、连表查询方法、笛卡尔积通过什么连接得到 sql对‘a’,‘b’,‘c’,‘d’排序,排成自己指定的顺序
答:连表查询方法,我大致说了三个,引入之前的答案:说句实在话,自从辞职读研以来很久没有用过sql语句了,关于这几个连接光靠记忆的话,完全会是懵逼,幸亏自己还不算蠢,很自然的根据字面理解,我很好的回答了出来,left join就是返回包括左表中所有记录和右表中联结字段相等的记录,好了面试官会问你,那么如果A表中,有甲丙丁3条记录,B表中有甲乙丙丁4条记录,那么如果条件都满足的情况,A left join B 丙记录是否会被查出,答案是否定的!好了,right join就是和left join 相反的,inner join等值联结 只返回2表中联结字段相等的行!讲到这里我就戛然而止,可能是面试官觉得我回答的还不够全面,所以又提醒我那么笛卡尔积怎么实现的,我想了想,突然脑子中冒出了个Cross join,于是脱口而出,交叉连接,然后面试官嗯了下,于是接着往下走问我一般用什么排序,我就回答,order by啦,然后就是提了下 desc 和ASC的含义,一个降序一个升序没什么好说的,最后话锋一转,问我,给我 a b c d 四个字符让我按照自定义的方式排序怎么实现,比如排序成 b a c d 我实话实说不知道。。。
7、分布式
最后一个问题是问我了解分布式不,我说稍微看了下,不怎么了解,这段时间正打算看看。。。
PS:spring mvc模块及功能是最后回答的,所以回答完这些,面试官让我自己提了些问题,随便问了些,就是后悔没用问我那几个没答出来的题目,本来是要问的,最后竟然忘了!。。。。
2017年2月22日22:44:18总结
转载自:http://www.cnblogs.com/chenzhouchou/p/6431420.html