通过sklearn 实现LabelEnconder 编码,之后进行xgboost预测。
通过sklearn 实现babel 编码,之后进行xgboost预测。
LabelEncoder()
更多编码操作可以参考:链接直通车
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
import xgboost as xgb
import pandas as pd
def GitdataCate():
df=pd.read_csv("Training.csv")
one_hot_feature=["prognosis"]
lbc = LabelEncoder()
for feature in one_hot_feature:
try:
df[feature] = lbc.fit_transform(df[feature].apply(int))
except:
df[feature] = lbc.fit_transform(df[feature])
# X=df.as_matrix(),此方法后面回去删除,可以使用df.values
X=df.values
print(X)
#返回映射后的classes_的编码
terminal_type1 = {index: label for index, label in enumerate( lbc.classes_)}
print(terminal_type1)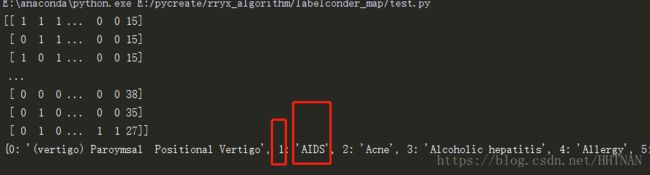
注意:上面的代码只能返回最后的一列的特征编码字典,通过过下下方式可以打印出每一个特征的特征编码。
for feature in one_hot_feature:
try:
df[feature] = lbc.fit_transform(df[feature].apply(int))
except:
df[feature] = lbc.fit_transform(df[feature])
# X=df.as_matrix(),此方法后面回去删除,可以使用df.values
terminal_type1 = {index: label for index, label in enumerate( lbc.classes_)}
print(terminal_type1)两个特征的特征编码:

把文件json,写入:
with open('terminal_type', 'w') as json_file:
json_file.write(json.dumps(terminal_type1))更多操作:
from sklearn.preprocessing import LabelEncoder
包初始化
gle = LabelEncoder()
建立映射
terminal_type= gle.fit_transform(data1[‘terminal_type’])
映射后的对应值
terminal_type1 = {index: label for index, label in enumerate(gle.classes_)}
添加映射后的列
data1[‘terminal_type1’] = terminal_type
删除映射前对的列
data1 = data1.drop([‘terminal_type’],axis=1)
data1.head()klearn.preprocessing.LabelEncoder():标准化标签,将标签值统一转换成range(标签值个数-1)范围内
以数字标签为例:
In [1]: from sklearn import preprocessing
...: le = preprocessing.LabelEncoder()
...: le.fit([1,2,2,6,3])
...:
Out[1]: LabelEncoder()获取标签值
In [2]: le.classes_
Out[2]: array([1, 2, 3, 6])将标签值标准化
In [3]: le.transform([1,1,3,6,2])
Out[3]: array([0, 0, 2, 3, 1], dtype=int64)将标准化的标签值反转
In [4]: le.inverse_transform([0, 0, 2, 3, 1])
Out[4]: array([1, 1, 3, 6, 2])非数字型标签值标准化:
In [5]: from sklearn import preprocessing
...: le =preprocessing.LabelEncoder()
...: le.fit(["paris", "paris", "tokyo", "amsterdam"])
...: print('标签个数:%s'% le.classes_)
...: print('标签值标准化:%s' % le.transform(["tokyo", "tokyo", "paris"]))
...: print('标准化标签值反转:%s' % le.inverse_transform([2, 2, 1]))
...:标签个数:[‘amsterdam’ ‘paris’ ‘tokyo’]
标签值标准化:[2 2 1]
标准化标签值反转:[‘tokyo’ ‘tokyo’ ‘paris’]