Python遇见机器学习 ---- 梯度下降法法 Gradient Descent
综述
“譬如行远必自迩,譬如登高必自卑。”
本文采用编译器:jupyter
所谓梯度下降算法,本质上来讲并不能将其称作为机器学习算法,但是可以用于很多机器学习解决问题的领域,并且从数学上为我们解决一个复杂的问题提供了一个思路。
回顾上一文中所述线性回归算法的损失函数,我们完全可以使用梯度下降法来最小化,就像日常生活中我们在登山时一定会选择最近的路程,所谓“梯度”其实就是“山”最陡峭的那条路。
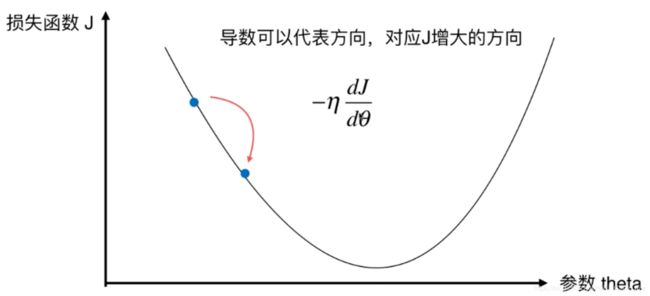
其中超参数![]() 称为学习率(learning rate),
称为学习率(learning rate),![]() 的取值将会影响获得最优解的速度,如果取了不合适的值可能无法得到最优解。
的取值将会影响获得最优解的速度,如果取了不合适的值可能无法得到最优解。
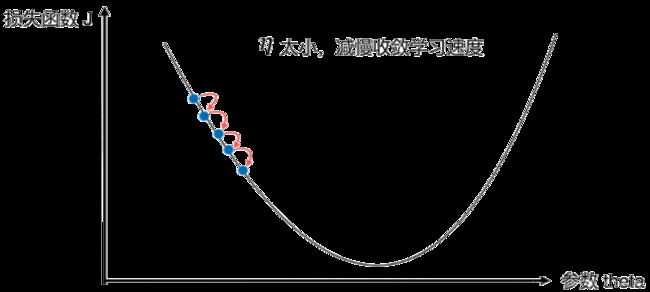
如果![]() 取值太小的话,会限制收敛学习的速度,如图
取值太小的话,会限制收敛学习的速度,如图
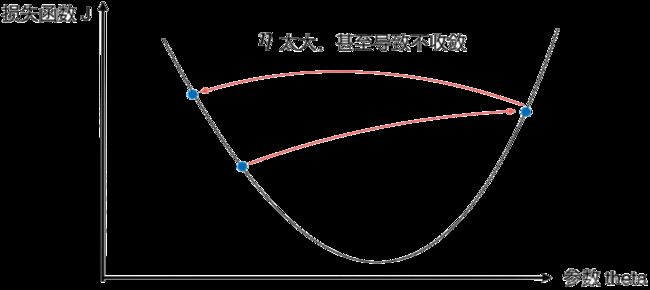
如果![]() 取值太大的话,可能会导致不收敛,如图
取值太大的话,可能会导致不收敛,如图
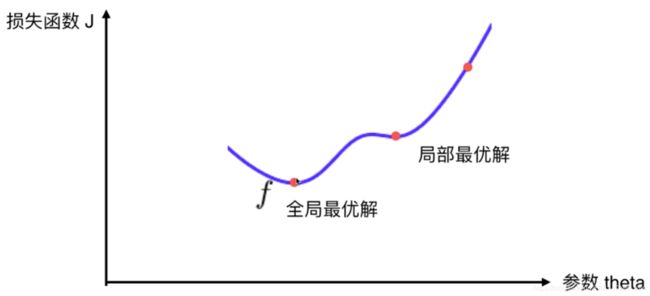
然鹅,并不是所有的函数都有唯一的极值点,如下。对此我们可以多次运行,随机化初始点,故梯度下降法的初始点也是一个超参数。
01 梯度下降法模拟
import numpy as np
import matplotlib.pyplot as plt
plot_x = np.linspace(-1, 6, 141) # 包括-1和6共141个点,采样点数为140
plot_x
"""
Out[2]:
array([-1. , -0.95, -0.9 , -0.85, -0.8 , -0.75, -0.7 , -0.65, -0.6 , -0.55, -0.5 ,
......
5.65, 5.7 , 5.75, 5.8 , 5.85, 5.9 , 5.95, 6. ])
"""
plot_y = (plot_x-2.5)**2-1 # 二次曲线
plt.plot(plot_x, plot_y)
plt.show() 
def dJ(theta): # 求导
return 2*(theta-2.5)
def J(theta):
return (theta-2.5)**2-1
eta = 0.1 # 学习率
epsilon = 1e-8 # 两次精度的差值如果小于这个说明到了极小值点
theta = 0.0
while True:
gradient = dJ(theta) # 梯度
last_theta = theta
theta = theta - eta*gradient
if(abs(J(theta) - J(last_theta)) < epsilon):
break
print(theta)
print(J(theta))
# 2.499891109642585
# -0.99999998814289
eta = 0.1 # 学习率
theta = 0.0
theta_history = [theta]
while True:
gradient = dJ(theta)
last_theta = theta
theta = theta - eta*gradient
theta_history.append(theta)
if(abs(J(theta) - J(last_theta)) < epsilon):
break
plt.plot(plot_x, J(plot_x), color='b')
plt.plot(np.array(theta_history), J(np.array(theta_history)), color='r', marker='+')
plt.show()

len(theta_history)
# Out[11]:
# 46
# 将函数进行封装
def gradient_descent(initial_theta, eta, epsilon=1e-8):
theta = initial_theta
theta_history.append(initial_theta)
while True:
gradient = dJ(theta)
last_theta = theta
theta = theta - eta*gradient
theta_history.append(theta)
if(abs(J(theta) - J(last_theta)) < epsilon):
break
def plot_theta_history():
plt.plot(plot_x, J(plot_x))
plt.plot(np.array(theta_history), J(np.array(theta_history)), color='r', marker="+")
plt.show()
eta = 0.01
theta_history = []
gradient_descent(0., eta)
plot_theta_history()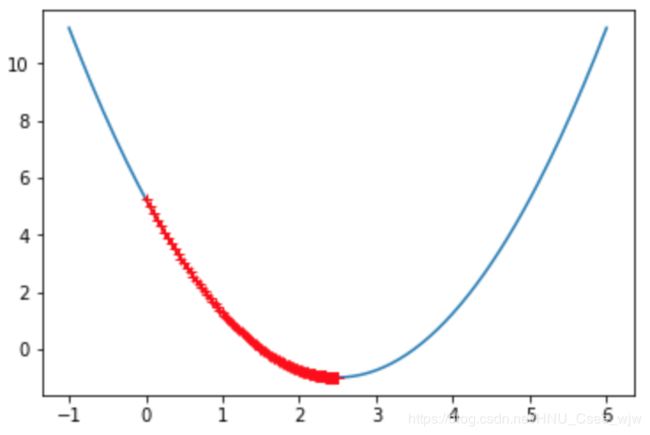
len(theta_history)
# Out[16]:
# 424
eta = 0.001 # 取值太小
theta_history = []
gradient_descent(0., eta)
plot_theta_history()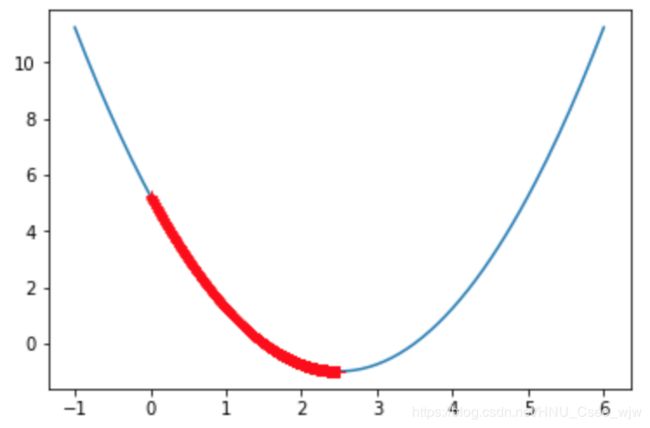
eta = 0.8 # 取值较大
theta_history = []
gradient_descent(0., eta)
plot_theta_history()
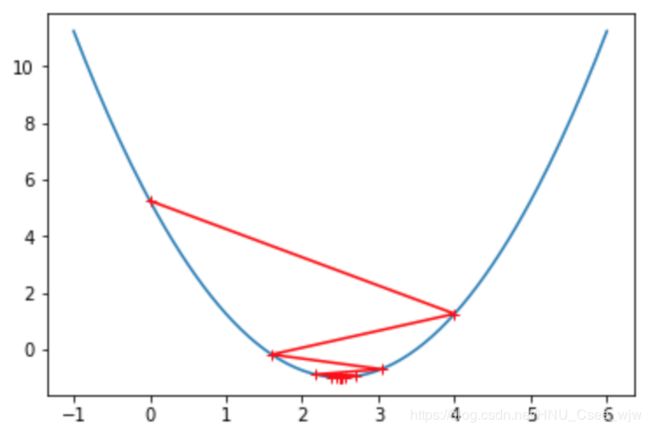
eta = 1.1 # 取值过大,无法找到极值点
theta_history = []
gradient_descent(0., eta)
plot_theta_history()
"""
---------------------------------------------------------------------------
OverflowError Traceback (most recent call last)
in ()
1 eta = 1.1
2 theta_history = []
----> 3 gradient_descent(0., eta)
4 plot_theta_history()
in gradient_descent(initial_theta, eta, epsilon)
9 theta_history.append(theta)
10
---> 11 if(abs(J(theta) - J(last_theta)) < epsilon):
12 break
13
in J(theta)
1 def J(theta):
----> 2 return (theta-2.5)**2-1
OverflowError: (34, 'Result too large')
""" def J(theta):
try: # 如果步长太大函数计算值过大则抛出异常
return (theta-2.5)**2 - 1.
except:
return float('inf') # 返回浮点数的最大值
# 限定最大循环次数
def gradient_descent(initial_theta, eta, n_iters = 1e4, epsilon=1e-8):
theta = initial_theta
theta_history.append(initial_theta)
i_iter = 0
while i_iter < n_iters:
gradient = dJ(theta)
last_theta = theta
theta = theta - eta*gradient
theta_history.append(theta)
if(abs(J(theta) - J(last_theta)) < epsilon):
break
i_iter += 1
eta = 1.1 # 取值过大,无法找到极值点
theta_history = []
gradient_descent(0., eta)
len(theta_history)
# Out[23]:
# 10001
theta_history[-1]
# Out[24]:
# nan
# 绘图观察eta太大会发生的结果
eta = 1.1 # 取值过大,无法找到极值点
theta_history = []
gradient_descent(0., eta, n_iters=10)
plot_theta_history()

02 在线性回归模型中使用梯度下降法
参考前一篇介绍线性回归的文章,我们完全可以应用梯度下降法来找到线性回归模型误差的最小值,求出对应的![]()
推导如下:
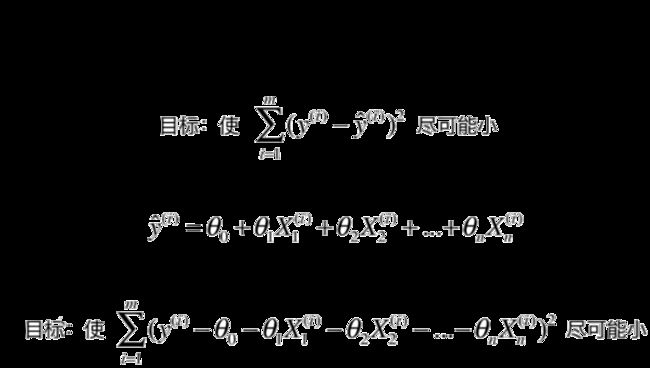
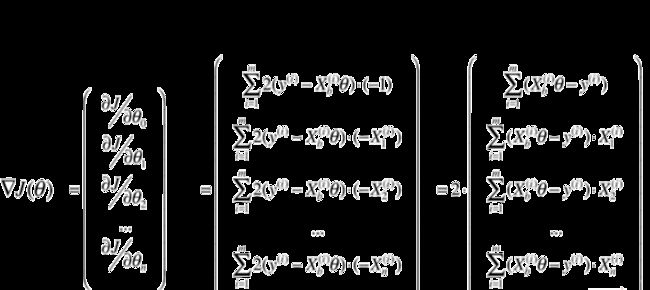
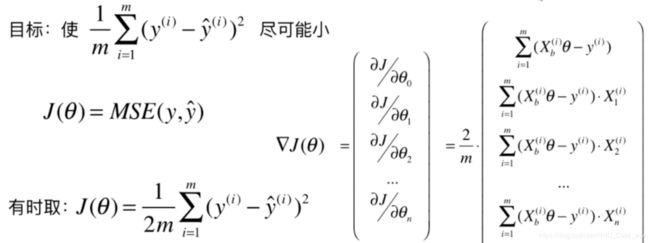
为了使计算结果与数据的个数m无关,将计算m个数据的均值
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(666)
x = 2 * np.random.random(size=100) # 定义成一维方便可视化操作
y = x * 3. + 4. + np.random.normal(size=100)
X = x.reshape(-1, 1) # 拓展到多维情况,共100个数据,每个数据由一个特征
X.shape
# Out[4]:
# (100, 1)
y.shape
# Out[5]:
# (100,)
plt.scatter(x, y)
plt.show()

使用梯度下降法训练
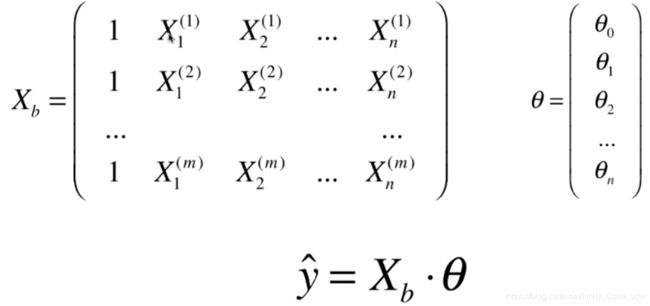
def J(theta, X_b, y):
try:
return np.sum((y - X_b.dot(theta))**2) / len(X_b)
except:
return float('inf')def dJ(theta, X_b, y):
res = np.empty(len(theta))
res[0] = np.sum(X_b.dot(theta) - y)
for i in range(1, len(theta)):
res[i] = (X_b.dot(theta) - y).dot(X_b[:,i])
return res * 2 / len(X_b) # 对于一个二维数组,len返回其行数
def gradient_descent(X_b, y, initial_theta, eta, n_iters = 1e4, epsilon=1e-8):
theta = initial_theta
i_iter = 0
while i_iter < n_iters:
gradient = dJ(theta, X_b, y)
last_theta = theta
theta = theta - eta*gradient
if(abs(J(theta, X_b, y) - J(last_theta, X_b, y)) < epsilon):
break
i_iter += 1
return theta
X_b = np.hstack([np.ones((len(x), 1)) , x.reshape(-1, 1)])
initial_theta = np.zeros(X_b.shape[1]) # 每个特征对应一个theta,(还应再多一个theta0)
eta = 0.01
theta = gradient_descent(X_b, y, initial_theta, eta)
theta # 结果对应截距和斜率
# Out[11]:
# array([ 4.02145786, 3.00706277])封装我们的线性回归算法
from playML.LinearRegression import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit_gd(X, y)
# Out[12]:
# LinearRegression()
lin_reg.coef_
# Out[13]:
# array([ 3.00574511])
lin_reg.intercept_
# Out[14]:
# 4.02302011280825503 梯度下降法的向量化


Xb是一个m✖️(n+1)的矩阵,括号里面是1✖️m的矩阵,最终乘积是一个行向量,但梯度是一个列向量所以在此进行转置操作变为
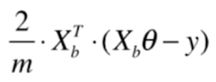
此时结果是列向量。
至此,梯度可以变成
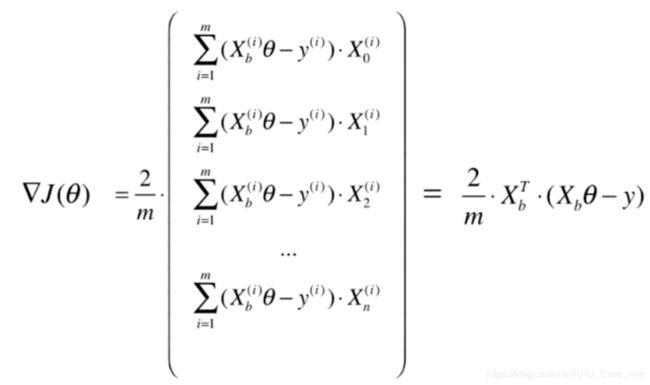
可以将代码中使用for循环的操作变成向量的乘积。
import numpy as np
from sklearn import datasets
boston = datasets.load_boston()
X = boston.data
y = boston.target
X = X[y < 50.0]
y = y[y < 50.0]
from playML.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, seed=666)
from playML.LinearRegression import LinearRegression
lin_reg1 = LinearRegression()
%time lin_reg1.fit_normal(X_train, y_train)
lin_reg1.score(X_test, y_test)
# 0.81298026026584913CPU times: user 130 ms, sys: 10.6 ms, total: 141 ms Wall time: 147 ms
使用梯度下降法
lin_reg2 = LinearRegression()
lin_reg2.fit_gd(X_train, y_train)
# Out[5]:
# LinearRegression()
lin_reg2.coef_ # 真实数据集中,每个特征所对应的数量级是不同的,可能计算出的步长还是过大
# Out[6]:
# array([ nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan,
# nan, nan])
lin_reg2.fit_gd(X_train, y_train, eta=0.000001)
# Out[7]:
# LinearRegression()
lin_reg2.score(X_test, y_test) # 结果不对,可能因为步长太小而需要更多的循环次数
# Out[8]:
# 0.27556634853389195
%time lin_reg2.fit_gd(X_train, y_train, eta=0.000001, n_iters=1e6)
CPU times: user 37 s, sys: 107 ms, total: 37.1 s
Wall time: 37.6 s
# Out[9]:
# LinearRegression()
lin_reg2.score(X_test, y_test) # 结果仍不令人满意
# 解决数据不在一个维度上的办法是先将数据进行归一化操作
# Out[10]:
# 0.75418523539807636
使用梯度下降法前进行数据归一化
from sklearn.preprocessing import StandardScaler
standardScaler = StandardScaler()
standardScaler.fit(X_train)
# Out[12]:
# StandardScaler(copy=True, with_mean=True, with_std=True)
X_train_standard = standardScaler.transform(X_train)
lin_reg3 = LinearRegression()
%time lin_reg3.fit_gd(X_train_standard, y_train)
CPU times: user 194 ms, sys: 3.7 ms, total: 198 ms
Wall time: 199 ms
# Out[14]:
# LinearRegression()
X_test_standard = standardScaler.transform(X_test)
lin_reg3.score(X_test_standard, y_test)
# Out[16]:
# 0.81298806201222351
梯度下降法的优势,在数据量较大时耗时比线性回归法小
m = 1000
n = 5000
big_X = np.random.normal(size=(m, n))
# 生成随机在0到100取值的5001个数
true_theta = np.random.uniform(0.0, 100.0, size=n+1)
big_y = big_X.dot(true_theta[1:]) + true_theta[0] + np.random.normal(0., 10., size=m)
big_reg1 = LinearRegression()
%time big_reg1.fit_normal(big_X, big_y)
CPU times: user 20.8 s, sys: 658 ms, total: 21.4 s
Wall time: 9.67 s
# Out[18]:
# LinearRegression()
big_reg2 = LinearRegression()
%time big_reg2.fit_gd(big_X, big_y)
CPU times: user 10.6 s, sys: 100 ms, total: 10.7 s
Wall time: 4.59 s
# Out[19]:
# LinearRegression()04 随机梯度下降法

样本i为一个随机变量,即每次取一个随机的梯度进行下降

学习率应当随着循环次数的增加应当逐渐缓慢减小,防止跳出误差最小值点的范围。
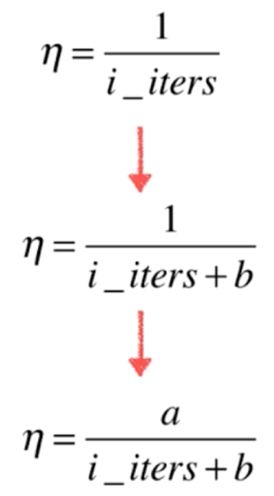
经验上a取5,b取50。(模拟退火的思想)
04 随机梯度下降法
import numpy as np
import matplotlib.pyplot as plt
m = 100000
x = np.random.normal(size=m)
X = x.reshape(-1,1) # 只有一个特征
y = 4.*x + 3. +np.random.normal(0, 3, size=m)
def J(theta, X_b, y):
try:
return np.sum((y - X_b.dot(theta))**2) / len(X_b)
except:
return float('inf')
def dJ(theta, X_b, y):
return X_b.T.dot(X_b.dot(theta) - y) * 2. / len(y)
def gradient_descent(X_b, y, initial_theta, eta, n_iters=1e4, epsilon=1e-8):
theta = initial_theta
i_iter = 0
while i_iter < n_iters:
gradient = dJ(theta, X_b, y)
last_theta = theta
theta = theta - eta*gradient
if(abs(J(theta, X_b, y) - J(last_theta, X_b, y)) < epsilon):
break
i_iter += 1
return theta
%%time
X_b = np.hstack([np.ones((len(X), 1)), X])
initial_theta = np.zeros(X_b.shape[1])
eta = 0.01
theta = gradient_descent(X_b, y, initial_theta, eta)
CPU times: user 864 ms, sys: 68 ms, total: 932 ms
Wall time: 646 ms
theta
# Out[5]:
# array([ 2.98747839, 4.00185783])
随机梯度下降法
def dJ_sgd(theta, X_b_i, y_i): #传入的是X_b,y的某一行
return X_b_i.T.dot(X_b_i.dot(theta) - y_i) * 2.
# 梯度下降法,学习率不断改变
def sgd(X_b, y, initial_theta, n_iters):
t0 = 5
t1 = 50
def learning_rate(t):
return t0 / (t + t1)
# 由于是随机梯度下降,不能按照前后两次函数值的变化多少来判断是否找到了最小值点
theta = initial_theta
for cur_iter in range(n_iters):
rand_i = np.random.randint(len(X_b))
gradient = dJ_sgd(theta, X_b[rand_i], y[rand_i])
theta = theta - learning_rate(cur_iter) * gradient
return theta
%%time
X_b = np.hstack([np.ones((len(X), 1)), X])
initial_theta = np.zeros(X_b.shape[1])
theta = sgd(X_b, y, initial_theta, n_iters=len(X_b)//3) # 循环次数设置为样本量的三分之一
CPU times: user 247 ms, sys: 4.24 ms, total: 252 ms
Wall time: 251 ms
theta
# Out[9]:
# array([ 2.95001259, 3.88694308])
05 使用我们自己的SGD
import numpy as np
import matplotlib.pyplot as plt
m = 10000
x = np.random.normal(size=m)
X = x.reshape(-1, 1)
y = 4.*x + 3. + np.random.normal(0, 3, size=m)
from playML.LinearRegression import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit_sgd(X, y, n_iters=2)
# Out[3]:
LinearRegression()
lin_reg.coef_
# Out[4]:
# array([ 4.02866416])
lin_reg.intercept_
# Out[5]:
# 3.0302884363039437真实使用我们自己的SGD
from sklearn import datasets
boston = datasets.load_boston()
X = boston.data
y = boston.target
X = X[y < 50.0]
y = y[y < 50.0]
from playML.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, seed=666)
from sklearn.preprocessing import StandardScaler
standardScaler = StandardScaler()
standardScaler.fit(X_train)
X_train_standard = standardScaler.transform(X_train)
X_test_standard = standardScaler.transform(X_test)
from playML.LinearRegression import LinearRegression
lin_reg = LinearRegression()
%time lin_reg.fit_sgd(X_train_standard, y_train, n_iters=2)
lin_reg.score(X_test_standard, y_test)
# 此时没有达到最好的结果(0.8129),可以适当增加n_iters
CPU times: user 8.04 ms, sys: 2 ms, total: 10 ms
Wall time: 9.77 ms
# Out[9]:
# 0.79233295554251493
%time lin_reg.fit_sgd(X_train_standard, y_train, n_iters=50)
lin_reg.score(X_test_standard, y_test)
CPU times: user 110 ms, sys: 2.17 ms, total: 112 ms
Wall time: 113 ms
# Out[10]:
# 0.81324404894409674
%time lin_reg.fit_sgd(X_train_standard, y_train, n_iters=100)
lin_reg.score(X_test_standard, y_test)
CPU times: user 205 ms, sys: 4.12 ms, total: 209 ms
Wall time: 212 ms
# Out[11]:
# 0.81316850059297174scikit-learn中的SGD
from sklearn.linear_model import SGDRegressor # 在linear_model包中,只能解决线性回归问题
sgd_reg = SGDRegressor()
%time sgd_reg.fit(X_train_standard, y_train)
sgd_reg.score(X_test_standard, y_test)
CPU times: user 881 µs, sys: 48 µs, total: 929 µs
Wall time: 1.04 ms
# Out[14]:
# 0.80584845142813721
sgd_reg = SGDRegressor(n_iter=100) # 遍历整个数据集100遍
%time sgd_reg.fit(X_train_standard, y_train)
sgd_reg.score(X_test_standard, y_test)
CPU times: user 7.05 ms, sys: 2.22 ms, total: 9.28 ms
Wall time: 6.44 ms
# Out[15]:
# 0.8131216351522008206 如何调试梯度
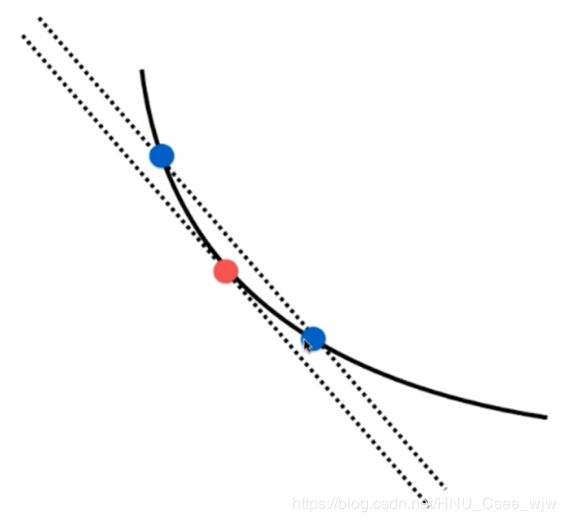
为了逼近曲线在某一点(红色)的梯度,可以在此点一前一后分别取两个点(蓝色)进行连线,则蓝色点连线的斜率就近似等于所要逼近的梯度,回顾《高等数学一》中,当蓝色点无限逼近红色点时的描述就是斜率的定义。

对于多维情况:

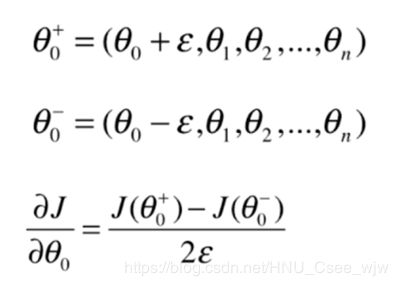
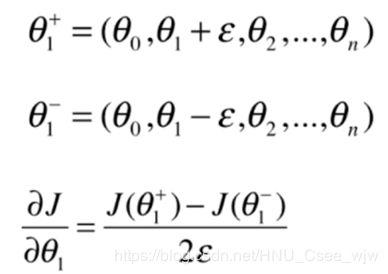
准备数据
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(666)
X = np.random.random(size=(1000, 10)) # 1000个样本,每个样本有10个特征值
true_theta = np.arange(1, 12, dtype=float) # 对应的theta应该有11个
X_b = np.hstack([np.ones((len(X), 1)), X]) # 样本
y = X_b.dot(true_theta) + np.random.normal(size=1000) # 标记
X.shape
# Out[5]:
# (1000, 10)
y.shape
# Out[6]:
# (1000,)
true_theta
# Out[7]:
# array([ 1., 2., 3., 4., 5., 6., 7., 8., 9., 10., 11.])
def J(theta, X_b, y):
try:
return np.sum((y - X_b.dot(theta))**2) / len(X_b)
except:
return float('inf')
def dJ_math(theta, X_b, y):
return X_b.T.dot(X_b.dot(theta) - y) * 2. / len(y)
def dJ_debug(theta, X_b, y, epsilon=0.01):
res = np.empty(len(theta))
for i in range(len(theta)):
theta_1 = theta.copy()
theta_1[i] += epsilon
theta_2 = theta.copy()
theta_2[i] -= epsilon
res[i] = (J(theta_1, X_b, y) - J(theta_2, X_b, y)) / (2*epsilon)
return res
def gradient_descent(dJ, X_b, y, initial_theta, eta, n_iters=1e4, epsilon=1e-8):
theta = initial_theta
i_iter = 0
while i_iter < n_iters:
gradient = dJ(theta, X_b, y)
last_theta = theta
theta = theta - eta*gradient
if(abs(J(theta, X_b, y) - J(last_theta, X_b, y)) < epsilon):
break
i_iter += 1
return theta
X_b = np.hstack([np.ones((len(X), 1)), X])
initial_theta = np.zeros(X_b.shape[1])
eta = 0.01
%time theta = gradient_descent(dJ_debug, X_b, y, initial_theta, eta)
theta
CPU times: user 4.09 s, sys: 12.4 ms, total: 4.11 s
Wall time: 4.13 s
"""
Out[12]:
array([ 1.1251597 , 2.05312521, 2.91522497, 4.11895968,
5.05002117, 5.90494046, 6.97383745, 8.00088367,
8.86213468, 9.98608331, 10.90529198])
"""
%time theta = gradient_descent(dJ_math, X_b, y, initial_theta, eta)
theta
CPU times: user 562 ms, sys: 6.68 ms, total: 568 ms
Wall time: 577 ms
"""
Out[13]:
array([ 1.1251597 , 2.05312521, 2.91522497, 4.11895968,
5.05002117, 5.90494046, 6.97383745, 8.00088367,
8.86213468, 9.98608331, 10.90529198])
"""结尾
本文还没有涉及到梯度下降法的小批量梯度下降法,待我慢慢整理。。。
最后再聊一下“随机”,没有固定模式的好处是,我们可以跳出局部最优解,并且意味着更快的运行速度。在机器学习中处处存在着,比如:随机搜索,随机森林。。。
附件:
LinearRegression.py
import numpy as np
from .metrics import r2_score
class LinearRegression:
def __init__(self):
"""初始化inear Regression模型"""
self.coef_ = None # 系数(即seita1...N)
self.intercept_ = None # 截距(即seita0)
self._theta = None # 私有向量
def fit_normal(self, X_train, y_train):
"""根据训练数据集X_train, y_train训练Linear Regression模型"""
# 样本数量必须等于标记数量,有多少样本就要多少标记
assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must be equal to the size of y_train"
# X_b为向量x_train左边添加一列1
X_b = np.hstack([np.ones((len(X_train), 1)), X_train])
self._theta = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y_train)
self.intercept_ = self._theta[0]
self.coef_ = self._theta[1:]
return self
def fit_gd(self, X_train, y_train, eta=0.01, n_iters=1e4):
"""根据训练数据集X_train, y_train, 使用梯度下降法训练Linear Regression模型"""
assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must be equal to the size of y_train"
def J(theta, X_b, y):
try:
return np.sum((y - X_b.dot(theta)) ** 2) / len(y)
except:
return float('inf')
def dJ(theta, X_b, y):
# res = np.empty(len(theta))
# res[0] = np.sum(X_b.dot(theta) - y)
# for i in range(1, len(theta)):
# res[i] = (X_b.dot(theta) - y).dot(X_b[:, i])
# return res * 2 / len(X_b)
return X_b.T.dot(X_b.dot(theta) - y) * 2. / len(X_b)
def gradient_descent(X_b, y, initial_theta, eta, n_iters=1e4, epsilon=1e-8):
theta = initial_theta
cur_iter = 0
while cur_iter < n_iters:
gradient = dJ(theta, X_b, y)
last_theta = theta
theta = theta - eta * gradient
if (abs(J(theta, X_b, y) - J(last_theta, X_b, y)) < epsilon):
break
cur_iter += 1
return theta
X_b = np.hstack([np.ones((len(X_train), 1)), X_train])
initial_theta = np.zeros(X_b.shape[1])
self._theta = gradient_descent(X_b, y_train, initial_theta, eta, n_iters)
self.intercept_ = self._theta[0]
self.coef_ = self._theta[1:]
return self
def fit_sgd(self, X_train, y_train, n_iters=5, t0=5, t1=50):
"""根据训练数据集X_train, y_train, 使用梯度下降法训练Linear Regression模型"""
# 数据个数必须与标记个数相同
assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must be equal to the size of y_train"
assert n_iters >= 1
def dJ_sgd(theta, X_b_i, y_i):
return X_b_i * (X_b_i.dot(theta) - y_i) * 2.
def sgd(X_b, y, initial_theta, n_iters, t0=5, t1=50):
def learning_rate(t):
return t0 / (t + t1)
theta = initial_theta
m = len(X_b)
# n_iters表示将样本循环多少遍
for cur_iter in range(n_iters):
# 对索引乱序处理,使每一遍的遍历更随机
indexes = np.random.permutation(m)
X_b_new = X_b[indexes]
y_new = y[indexes]
for i in range(m):
# rand_i = np.random.randint(m)
grandient = dJ_sgd(theta, X_b_new[i], y_new[i])
theta = theta - grandient * learning_rate(cur_iter * m + i) # 当前遍历次数为cur_iter * m + i
return theta
X_b = np.hstack([np.ones((len(X_train), 1)), X_train])
initial_theta = np.zeros(X_b.shape[1])
self._theta = sgd(X_b, y_train, initial_theta, n_iters, t0, t1) # 循环次数设置为样本量的三分之一
self.intercept_ = self._theta[0]
self.coef_ = self._theta[1:]
return self
def predict(self, X_predict):
"""给定待预测数据集X_predict,返回表示X_predict的结果向量"""
assert self.intercept_ is not None and self.coef_ is not None, \
"must fit before predict!"
# 传入数据的特征数量应该等于系数的个数,每一个特征对应一个系数
assert X_predict.shape[1] == len(self.coef_), \
"the feature number of X_predict must be equal to X_train"
X_b = np.hstack([np.ones((len(X_predict), 1)), X_predict])
return X_b.dot(self._theta)
def score(self, X_test, y_test):
"""根据测试数据集 X_test 和 y_test 确定当前模型的准确度"""
y_predict = self.predict(X_test)
return r2_score(y_test, y_predict)
def __repr__(self):
return "LinearRegression()"
最后,欢迎各位读者共同交流,祝好。
