最长回文子串——马拉车算法详解
马拉车算法(Manacher‘s Algorithm)是用来解决求取一个字符串的最长回文子串问题的。此算法充分利用了回文字符串的性质,将算法复杂度降到了线性,非常值得一学。
我将网上所有讲解马拉车算法的文章基本看了一遍,总结出了最通俗易懂的介绍,同时用 python 进行了实现。
题目
给定一个字符串s,找到s中最长的回文子字符串。
所谓回文字符串,指的是无论从左往右读还是从右往左读,结果都是一样的,也叫做对称字符串。
比如 “google” 的最长回文子串为 “goog”。
马拉车算法
这个算法的总框架是,遍历所有的中心点,寻找每个中心点对应的最长回文子串,然后找到所有中心点对应的最长回文子串,与求取一个字符串的最长回文子串中的第4个方法思想类似。
但是,第4个方法的复杂度为 O(n2) O ( n 2 ) ,而马拉车算法对其进行了改进,将复杂度变为了线性。
1、字符之间插入特殊字符
回文串的中心点有两种,如果长度为奇数,则回文串中心为最中间的那个字符,如 “aba” 的 “b”;如果长度为偶数,则回文串中心为最中间的两个字符的分界,如 “abba” 的 “bb”。为了统一,马拉车算法首先将字符串的每个字符之间(包括首尾两端)插入一个特殊符号,如#,这个符号必须是原字符串中所没有的。
比如我们的原字符串为
s = "google"
那么插入#号之后,变为了
ss = "#g#o#o#g#l#e#"
这样做之后,字符串的长度肯定是奇数,因为插入的#号的个数一定等于字符个数+1,因此总长度是偶数+奇数=奇数。这样,循环时便不用考虑原字符串长度的奇偶性了。
2、计算半径数组 p
接下来,我们需要想办法计算出一个数组 p,这个数组的长度与处理后的字符串 ss 等长,其中 p[i] 表示以 ss[i] 为中心的最长回文子串的半径(不包括 p[i] 本身),暂且把它成为半径数组。如果 p[i] = 0,则说明回文子串就是 ss[i] 本身。
比如 “#a#b#” 的半径数组为 [0, 1, 0, 1, 0]。
为了在搜索回文子串时避免总是判断是否越界,我们在 ss 的首尾两端加上两个不同的特殊字符,保证这两个特殊字符不会出现在 ss 中。比如为 $ 和 ^。则 ss 变为了
ss = "$#g#o#o#g#l#e#^"
数组 p 的最大半径,就是我们要寻找的最长回文子串的半径。因此只要计算出了数组 p,最后答案就呼之欲出了。
如何计算数组 p
一般的方法,是以中心点为中心,挨个将半径逐步扩张,直至字符串不再是回文字符串。但是这样做,整体的算法复杂度为 O(n2) O ( n 2 ) 。马拉车算法的关键之处,就在于巧妙的应用了回文字符串的性质,来计算数组 p。
马拉车算法在计算数组 p 的整个流程中,一直在更新两个变量:
id:回文子串的中心位置mx:回文子串的最后位置
使用这两个变量,便可以用一次扫描来计算出整个数组 p,关键公式为:
p[i] = min(mx-i, p[2 * id - i])
我们用图示来理解这个公式,如下图:
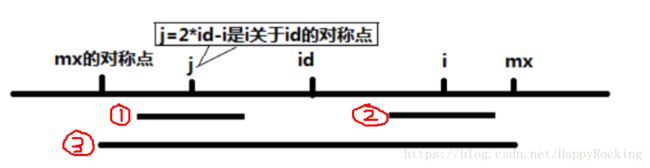
当前,我们已经得到了 p[0…i-1],想要计算出 p[i] 来。红1为以 j 为中心的回文子串,红2为以 i 为中心的回文子串,红3为以 id 为中心的回文子串(首尾两端分别为mx的对称点和mx)。
那么,如果 mx 在 i 的右边,则我们可以通过已经计算出的 p[j] 来计算 p[i],其中 j 与 i 的中心点为 id。这里分两种情况:
- 先直接令 p[i] 的回文子串就等于 p[j] 的回文子串,即红2长度等于红1,然后判断红2的末尾是否超过了 mx,如果没有超过,则说明 p[i] 就等于 p[j]。
为什么呢?
因为以 id 为中心的回文子串为红3,包含了红1和红2,而且红1和红2以 id 为中心,那么一定有红2=红1。并且已经知道,红1是以 j 为中心的最长子串,那么红2也肯定是以 i 为中心的最长子串。 - 如果红2的末尾超过了 mx,那么就只能让 p[i] = mx - i了,即我可以保证至少半径到 mx 这个位置,是可以回文的,但是一旦往右超出了 mx,就不能保证了,剩下的只能用笨方法慢慢扩张来得到最长回文子串。
那如果红2的左边超出了mx的对称点,怎么办?不会出现这种情况的,因为红1的右边不会超过mx。如果超过了mx,那么在上一次迭代中,id应该更新为j,mx应该更新为 j+p[j]。在迭代中,会始终保证 mx 是所有已经得到的回文子串末端最靠右的位置。
另外,如果 mx 不在 i 的右边呢?那就利用不了红3的对称性了,只能使用笨方法慢慢扩张了。
3、数组 p 中的最大值,即为最长回文子串的半径
根据半径数组 p 的定义,如果最大值对应位置为 i,则最大回文子串为 ss[i - p[i] : i + p[i] + 1]。
python 实现
马拉车的代码如下,其中 center 即为 id,且特殊字符使用的是 \0,\1,\2。
def longestPalindrome5(s):
"""
:type s: str
:rtype: str
马拉车算法。Manacher发明出来的。
时间复杂度为O(n)。
"""
if len(s) <= 1:
return s
# 每个字符之间插入 \1
ss = '\0\1' + '\1'.join([x for x in s]) + '\1\2'
p = [0] * len(ss)
center = 0
mx = 0
max_str = ''
for i in range(1, len(p)-1):
if i < mx:
j = 2 * center - i # i 关于 center 的对称点
p[i] = min(mx-i, p[j])
# 尝试继续向两边扩展,更新 p[i]
while ss[i - p[i] - 1] == ss[i + p[i] + 1]: # 不必判断是否溢出,因为首位均有特殊字符,肯定会退出
p[i] += 1
# 更新中心
if i + p[i] > mx:
mx = i + p[i]
center = i
# 更新最长串
if 1 + 2 * p[i] > len(max_str):
max_str = ss[i - p[i] : i + p[i] + 1]
return max_str.replace('\1', '')