Hadoop3.1.1结合Ranger1.1.0、Ranger-KMS1.1.0创建加密区存储
文章目录
- HDFS加密
- AES加密算法(对称加密)
- RangerKMS管理
- HDFS“静态数据”加密
- HDFS加密概述
- 配置和使用HDFS“静态数据”加密
- 准备环境
- 创建加密密钥
- 创建加密区域
- 上传、下载、读取加密区中文件
HDFS加密
静态加密的HDFS数据实现了对HDFS读取和写入数据的端到端加密。端到端加密意味着数据仅由客户端加密和解密。其中的加/解密过程对于客户端来说是完全透明的。数据在客户端读操作的时候被解密,当数据被客户端写的时候被加密,所以HDFS服务端本身并不是一个主要的参与者。形象地说,在HDFS服务端,你看到的只是一堆加密的数据流。HDFS无法访问未加密的数据或密钥。
AES加密算法(对称加密)
HDFS加密方式:AES加密算法

密钥K: 用来加密明文的密码,在对称加密算法中,加密与解密的密钥是相同的。密钥为接收方与发送方协商产生,但不可以直接在网络上传输,否则会导致密钥泄漏,通常是通过非对称加密算法加密密钥,然后再通过网络传输给对方,实际中,一般是通过RSA加密AES的密钥,传输到接收方,接收方解密得到AES密钥,然后发送方和接收方用AES密钥来通信。或者直接面对面商量密钥。密钥是绝对不可以泄漏的,否则会被攻击者还原密文,窃取机密数据。
AES加密函数: 设AES加密函数为E,则 C = E(K, P),其中P为明文,K为密钥,C为密文。也就是说,把明文P和密钥K作为加密函数的参数输入,则加密函数E会输出密文C。
AES解密函数: 设AES解密函数为D,则 P = D(K, C),其中C为密文,K为密钥,P为明文。也就是说,把密文C和密钥K作为解密函数的参数输入,则解密函数会输出明文P。
RangerKMS管理
Ranger密钥管理服务(Ranger KMS)是一种开源,可扩展的加密密钥管理服务,支持HDFS“静态数据”加密。
Ranger KMS基于最初由Apache社区开发的Hadoop KMS。默认情况下,Hadoop KMS将密钥存储在基于文件的Java密钥库中。Ranger允许您将密钥存储在安全的数据库中,从而扩展了本机Hadoop KMS功能。
Ranger通过Ranger管理门户提供密钥管理服务器的集中管理。
Ranger KMS有三个主要功能:
1. 密钥管理: Ranger admin提供使用Web UI或REST API创建、更新或删除密钥的功能。所有Hadoop KMS API都使用密钥管理员用户名和密码与Ranger KMS配合使用。
2. 访问控制策略: Ranger admin还提供了在Ranger KMS中管理访问控制策略的功能。访问策略控制生成或管理密钥的权限,为在Hadoop中加密的数据添加另一层安全性。
3. 审计: Ranger提供Ranger KMS执行的所有操作的完整审计跟踪。
HDFS“静态数据”加密
Hadoop提供了几种加密存储数据的方法:
- 最低级别的加密是
卷加密,可在物理被盗或意外丢失磁盘卷后保护数据。整个卷都是加密的;此方法不支持对特定文件或目录进行更细粒度的加密。此外,卷加密不能防止系统运行时发生的病毒或其他攻击。 应用程序级加密(在Hadoop之上运行的应用程序内加密)支持更高级别的粒度并防止“恶意管理”访问,但为应用程序架构增加了一层复杂性。静态加密的HDFS数据,加密HDFS中存储的(“静止”)所选文件和目录。此方法使用专门指定的HDFS目录,称为“加密区域”。
HDFS加密概述
HDFS加密涉及以下几个要素:
1. 加密密钥: 除标准HDFS权限外,还提供基于权限的新级别访问保护。
2. HDFS加密区: 一种特殊的HDFS目录,其中所有数据在写入时加密,并在读取时解密。
- 每个加密区域都与创建区域时指定的加密密钥相关联。
- 加密区域内的每个文件都有一个唯一的加密密钥,称为“数据加密密钥”(DEK)。
- HDFS无权访问DEK。HDFS DataNodes仅查看加密字节流。HDFS将“加密数据加密密钥”(EDEK)存储为NameNode上文件元数据的一部分。
- 客户端解密EDEK并使用关联的DEK在写入和读取操作期间加密和解密数据。
3. Ranger密钥管理服务(Ranger KMS): 基于Hadoop KeyProviderAPI的开源密钥管理服务 。
对于HDFS加密,Ranger KMS有三个基本职责:
- 提供对存储的加密区密钥的访问。
- 生成并管理加密区密钥,并创建要存储在Hadoop中的加密数据密钥。
- 审核Ranger KMS中的所有访问事件。
配置和使用HDFS“静态数据”加密
工作流程如下:
- 创建HDFS加密区密钥,该密钥将用于加密加密区中每个文件的文件级数据加密密钥。该密钥由Ranger KMS存储和管理。
- 创建一个新的HDFS文件夹。指定文件夹的所需权限,所有者和组。
- 使用新的加密区域密钥,将文件夹指定为加密区域。
- 配置客户端访问。与客户端应用程序关联的用户需要足够的权限才能访问加密数据。在加密区域中,用户需要文件/目录访问(通过Posix权限或Ranger访问控制),以及某些键操作的访问权限。设置权限后,具有足够HDFS和Ranger KMS访问权限的Java API客户端和HDFS应用程序可以对加密区中的文件进行写入和读取。
准备环境
# 验证客户端主机是否已准备好使用AES-NI指令集优化进行HDFS加密
[root@manager241 ~]# yum install openssl-devel -y
[root@manager241 ~]# hadoop checknative
19/08/27 00:52:56 INFO bzip2.Bzip2Factory: Successfully loaded & initialized native-bzip2 library system-native
19/08/27 00:52:56 INFO zlib.ZlibFactory: Successfully loaded & initialized native-zlib library
19/08/27 00:52:56 WARN erasurecode.ErasureCodeNative: Loading ISA-L failed: Failed to load libisal.so.2 (libisal.so.2: cannot open shared object file: No such file or directory)
19/08/27 00:52:56 WARN erasurecode.ErasureCodeNative: ISA-L support is not available in your platform... using builtin-java codec where applicable
Native library checking:
hadoop: true /usr/hdp/3.0.0.0-1634/hadoop/lib/native/libhadoop.so.1.0.0
zlib: true /lib64/libz.so.1
zstd : false
snappy: true /usr/hdp/3.0.0.0-1634/hadoop/lib/native/libsnappy.so.1
lz4: true revision:10301
bzip2: true /lib64/libbz2.so.1
openssl: true /lib64/libcrypto.so
ISA-L: false Loading ISA-L failed: Failed to load libisal.so.2 (libisal.so.2: cannot open shared object file: No such file or directory
验证 “openssl: true ” Hadoop的检测的正确版本libcrypto.so
如果 “openssl: false ” 则表示没有正确的版本。
创建加密密钥
- 以用户keyadmin,密码(安装ranger时设置的admin)登录Ranger,进入RangerKMS

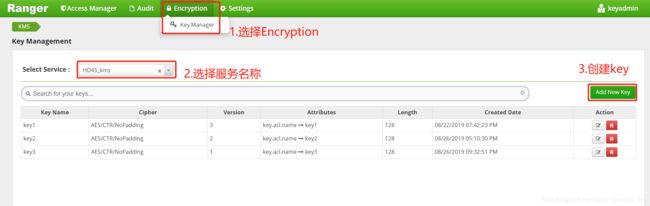
- 选择Encryption,选择服务名称,创建新密钥。

创建加密区域
[root@manager241 ~]# su - hdfs
1. 验证密钥的创建
[hdfs@manager241 ~]$ hadoop key list -metadata
Listing keys for KeyProvider: org.apache.hadoop.crypto.key.kms.LoadBalancingKMSClientProvider@2892dae4
key3 : cipher: AES/CTR/NoPadding, length: 128, description: , created: Mon Aug 26 21:32:51 CST 2019, version: 1, attributes: [key.acl.name=key3]
key2 : cipher: AES/CTR/NoPadding, length: 128, description: , created: Mon Aug 26 17:10:30 CST 2019, version: 2, attributes: [key.acl.name=key2]
key1 : cipher: AES/CTR/NoPadding, length: 128, description: , created: Thu Aug 22 19:42:23 CST 2019, version: 3, attributes: [key.acl.name=key1]
2. 作为HDFS管理员,创建一个新的空目录
[hdfs@manager241 ~]$ hdfs dfs -mkdir /zone_encr
3. 使用加密密钥,使目录成为加密区域,完成后,NameNode会将该文件夹/zone_encr识别为HDFS加密区域
[hdfs@manager241 ~]$ hdfs crypto -createZone -keyName key1 -path /zone_encr
Added encryption zone /zone_encr
4. 查看加密区及密钥
[hdfs@manager241 ~]$ hdfs crypto -listZones
/zone_encr key1
上传、下载、读取加密区中文件
具有足够HDFS和Ranger KMS权限的客户端和HDFS应用程序可以从/向加密区读取和写入文件。
客户端写入过程概述
- 客户端写入加密区域。
- NameNode检查以确保客户端具有足够的写访问权限。如果是这样,NameNode要求Ranger KMS创建一个文件级密钥,使用加密区域主密钥加密。
- Namenode存储Ranger KMS生成的文件级加密数据加密密钥(EDEK)作为文件元数据的一部分,并将EDEK返回给客户端。
- 客户端要求Ranger KMS解码EDEK(到DEK),并使用DEK写入加密数据。Ranger KMS在解密EDEK并为客户端生成DEK之前检查用户的权限。
客户端读取过程概述
- 客户端在加密区域中发出文件的读取请求。
- NameNode检查以确保客户端具有足够的读取访问权限。如果是这样,NameNode将返回文件的EDEK和用于加密EDEK的加密区密钥版本。
- 客户要求Ranger KMS解密EDEK。Ranger KMS检查为最终用户解密EDEK的权限。
- Ranger KMS解密并返回(未加密的)数据加密密钥(DEK)。
- 客户端使用DEK来解密和读取文件。
HDFS加密组件

1. 上传文件到加密区
修改该目录用户和用户组
[hdfs@manager241 ~]$ hdfs dfs -chown -R hive:hive /zone_encr
切换hive用户,hive用户权限(Decrypt EEK)
[root@manager241 ~]# su - hive
在/home/hive目录下新建文件test.txt
hello world
hello zhengzhou
hello ranger
[hive@manager241 ~]$ hdfs dfs -copyFromLocal test.txt /zone_encr
2. 从加密区下载文件
[hive@manager241 ~]$ hdfs dfs -copyToLocal /zone_encr/test.txt test_down.txt
[hive@manager241 ~]$ ll
-rw-r--r--. 1 hive hadoop 41 Aug 27 03:04 test_down.txt
-rw-r--r--. 1 hive hadoop 41 Aug 27 03:02 test.txt
3. 读取加密区文件数据内容
[hive@manager241 ~]$ hdfs dfs -cat /zone_encr/test.txt
hello world
hello zhengzhou
hello ranger
[root@manager241 ~]# su - ranger
[ranger@manager241 ~]$ hdfs dfs -cat /zone_encr/test.txt
cat: User:ranger not allowed to do 'DECRYPT_EEK' on 'key1'
参考资料:
- https://docs.hortonworks.com/HDPDocuments/HDP3/HDP-3.1.0/configuring-hdfs-encryption/content/install_ranger_kms_hsm_manually.html
- https://blog.csdn.net/weixin_42348333/article/details/81951562