SpringCloud,Sleuth+Zipkin
一、介绍
SpringCloud Sleuth为微服务提供了调用链路追踪解决方案,并且兼容支持了Zipkin,只需要引入相应的依赖,配置,即可实现对链路的监控。
SpringCloud Sleuth可以追踪10种组件:async、Hystrix、messaging、websocket、rxjava、scheduling、web(Spring MVC Controller, Servlet)、webclient(Spring RestTemplate)、Feign、Zuul 。可以参考 Spring Cloud Sleuth消息追踪原理,该博客介绍了Sleuth对8中常用组件的追踪原理。
SpringCloud对Zipkin进行了有效的集成,Zipkin是Twitter开源的轻量级分布式链路调用监控系统。Zipkin易于搭建,但是监控的东西很简单。pinpoint以及skywalking不仅仅提供了分布式服务的跟踪能力,还提供了其他性能监控,是一个APM解决方案。
分布式服务追踪系统主要有一下三个关键点:
1. Span。一个基础工作单元(例如服务调用)。为了统计各处理单元的时间延迟,当请求到达各服务组件时,也通过一个唯一标识(Span ID)标记它的开始、具体过程、结束。通过Span的开始和结束的时间戳,就能统计这个Span的时间延迟,获取事件名称、请求信息等元数据。
2. Trace。 一系列Span组成的树状结构。所有Span通过相同的Trace串联组成。为了实现请求跟踪,当请求到一个分布式系统的入口端点时,只需要服务跟踪框架为该请求创建一个唯一的跟踪标识(Trace ID),同时在服务内部流转时始终保持传递该唯一标识,直到请求返回为止。框架通过它将请求过程中的日志关联起来。
3. Annotation。用来及时记录一个事件的存在,一些核心Annotation用来定义请求的开始和结束。
● cs(Client Sent):客户端发出一个请求,这个Annotation描述了这个Span的开始。
● sr(Server Received):服务端收到请求并开始处理。timestampsr-timesampcs=网络延迟。
● ss(Server Sent):服务器处理完并准备返回给客户端。timestampss-timesampsr=服务器处理时间。
● cr(Client Received):客户端收到响应,表明Span的结束。timestampcr-timestampcs=请求总时间。

二、Zipkin结构与传输
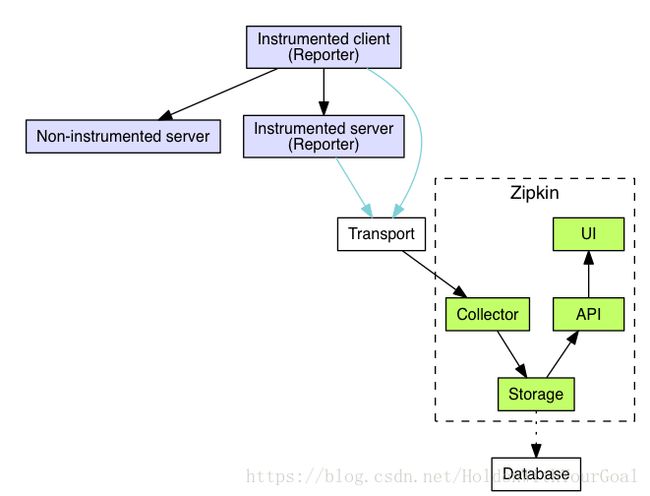
下图更能体现Zipkin的工作流程。
跟踪工具报告是异步的,避免跟踪系统对服务造成延时或故障。
Client收到服务的响应后,异步发送给Zipkin,Zipkin Collecter守护程序收到追踪数据,Zipkin Collecter就会对追踪数据进行验证、存储、索引。
Transport
追踪数据要从Span传输到Zipkin Collector服务,有三种主要的传输方式:Http,MQ(kafka),Scribe。
Components
Collector:一旦数据到达了Zipkin Collector的守护程序,就会被收集。
Storage:默认内存。Cassandra最初是为了存Zipkin数据而建立的,因为Cassandra可拓展。Cassandra可插拔,所以通常用ES,Mysql等替代。
Query Service:一旦数据被存储或者索引,我们就要用一种方法提取数据。查询守护进程提供一个简单的JSON API用于查找和检索跟踪。这个API的主要使用者是Web UI。
Web UI:提供了基于服务、时间、注释查看跟踪的方法。(没有内置的身份验证机制)
三、创建一个Zipkin Server
1. 导入web依赖,以及Zipkin Server、Zipkin UI的依赖
io.zipkin.java
zipkin-server
io.zipkin.java
zipkin-autoconfigure-ui
@SpringBootApplication
@EnableZipkinServer
public class ZipkinApplication {
public static void main(String[] args) {
SpringApplication.run(ZipkinApplication.class, args);
}
}spring.application.name=sleuth-service
server.port=8770四、创建service-1,service-2, service-1通过RestTemplate调用service-2
1. 引入web、Sleuth、Zipkin依赖
org.springframework.cloud
spring-cloud-sleuth-zipkin
org.springframework.cloud
spring-cloud-starter-sleuth
2. 两个工程创建两个接口,service-1的接口调用service-2的接口
service-1:
@SpringBootApplication
@RestController
public class Service1Application {
public static void main(String[] args) {
SpringApplication.run(Service1Application.class, args);
}
@Autowired
RestTemplate restTemplate;
@Bean
RestTemplate getRestTemplate(){
return new RestTemplate();
}
@RequestMapping("/service2")
public String callService2(){
return restTemplate.getForObject("http://localhost:8772/call", String.class);
}
}
@SpringBootApplication
@RestController
public class Service2Application {
@Autowired
RestTemplate restTemplate;
@Bean
RestTemplate getRestTemplate() {
return new RestTemplate();
}
public static void main(String[] args) {
SpringApplication.run(Service2Application.class, args);
}
@RequestMapping("/call")
public String call(){
return "service-2 called..";
}
}
3. 增加配置
service-1:
server.port=8771
spring.application.name=service-1
spring.zipkin.base-url=http://localhost:8770
spring.sleuth.sampler.percentage=1server.port=8772
spring.application.name=service-2
spring.zipkin.base-url=http://localhost:8770
spring.sleuth.sampler.percentage=1
★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★
注意:这里要配置采样率spring.sleuth.sampler.percentage=1,如果不配置这里默认为0.1,如果调大值为1,可以在Web UI上更及时看到信息。但是调大会影响服务调用速率。
★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★
五、测试
先启动Zipkin Server,访问 http:localhost:8770/

启动两个服务, 访问service-1中调用service-2的接口 localhost:8771/service2
再刷新Zipkin UI的Dependencies

trace:
