【python】爬虫获取全国各个城市的历史天气、温度、风向和风力
输入:
年份:target_year_list = ["2013", "2014", "2015", "2016", "2017"]
城市信息(城市名 城市拼音):http://yinter.iteye.com/blog/575549
北京 BEIJING
上海 SHANGHAI
天津 TIANJIN
重庆 CHONGQING
阿克苏 AKESU
安宁 ANNING
安庆 ANQING
鞍山 ANSHAN
安顺 ANSHUN
安阳 ANYANG
白城 BAICHENG
白山 BAISHAN
白银 BAIYIN
输出:每个城市的历史数据
源源不断地获取每个城市对应的历史数据:
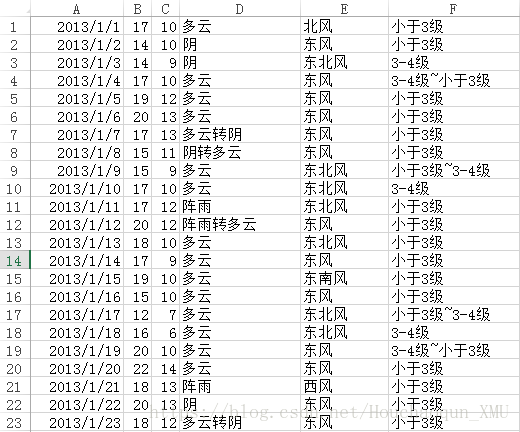
每个城市对应的历史数据,如下所示:
python 写入(write)文件时,出现乱码问题:
## 以下方式在mac上出现中文内容乱码
file = open('./weather_result/{}_weather.csv'.format(city_dict[city]), 'w')
## encoding='gb18030' 以这种方式创建文件即可
file = open('./weather_result/{}_weather.csv'.format(city_dict[city]), 'w', encoding='gb18030')部分城市的“风级”数据缺失:以北京市2016年7月份为例

字段缺失,会导致程序报错,具体细节看代码(有注释)。
_str += li.string + ','
## li.string 不能为空,否则报错,如下:
TypeError: unsupported operand type(s) for +: 'NoneType' and 'str'
源代码-1:历史天气网址好像出问题,详见源代码-2
#encoding:utf-8
import requests
from bs4 import BeautifulSoup
target_year_list = ["2013", "2014", "2015", "2016", "2017"]
target_month_list = ["01", "02", "03", "04", "05", "06", "07", "08", "09", "10", "11", "12"]
def get_urls(city_pinyin):
urls = []
for year in target_year_list:
for month in target_month_list:
date = year + month
urls.append("http://lishi.tianqi.com/{}/{}.html".format(city_pinyin, date))
return urls
## author: chulei
## date: 20180803
def get_city_dict(file_path):
city_dict = {}
with open(file_path, 'r') as file:
# line_list = f.readline()
for line in file:
line = line.replace("\r\n", "")
city_name = line.split(" ")[0]
city_pinyin = (line.split(" ")[1]).lower()
## 赋值到字典中...
city_dict[city_pinyin] = city_name
return city_dict
# =============================================================================
# main
# =============================================================================
file_path = "./city_pinyin_list.txt"
city_dict = get_city_dict(file_path)
for city in city_dict.keys():
file = open('./weather_result/{}_weather.csv'.format(city_dict[city]), 'w', encoding='gb18030')
urls = get_urls(city)
for url in urls:
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
weather_list = soup.select('div[class="tqtongji2"]')
try:
for weather in weather_list:
weather_date = weather.select('a')[0].string.encode('utf-8')
ul_list = weather.select('ul')
i=0
for ul in ul_list:
li_list= ul.select('li')
str=""
for li in li_list:
try:
## TypeError: unsupported operand type(s) for +: 'NoneType' and 'str'
_str += li.string + ','
except:
pass
if i!=0:
file.write(str+'\n')
i+=1
except:
print("except {}".format(url))
file.close()
print("Done {}".format(city))源代码-2:感谢蒋同学提供的代码
# -*- coding: utf-8 -*-
"""
Spyder Editor
This is a temporary script file.
"""
# coding=gbk
import io
import sys
import requests
import bs4
from bs4 import BeautifulSoup
import numpy as np
import pandas as pd
#sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') #改变标准输出的默认编码, 防止控制台打印乱码
target_year_list = ["2011","2012","2013", "2014","2015", "2016","2017", "2018"]
target_month_list = ["01", "02", "03", "04", "05", "06", "07", "08", "09", "10", "11", "12"]
def get_city_dict(file_path):
city_dict = {}
with open(file_path, 'r') as file:
# line_list = f.readline()
for line in file:
line = line.replace("\r\n", "")
city_name = (line.split(" ")[0]).strip()
city_pinyin = ((line.split(" ")[1]).strip()).lower()
## 赋值到字典中...
city_dict[city_pinyin] = city_name
return city_dict
def get_urls(city_pinyin):
urls = []
for year in target_year_list:
for month in target_month_list:
date = year + month
urls.append("http://www.tianqihoubao.com/lishi/{}/month/{}.html".format(city_pinyin, date))
return urls
#url = "http://www.tianqihoubao.com/lishi/beijing/month/201812.html"
file_path = "./city_pinyin_list.txt"
city_dict = get_city_dict(file_path)
def get_soup(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status() #若请求不成功,抛出HTTPError 异常
#r.encoding = 'gbk'
soup = BeautifulSoup(r.text, "html.parser")
return soup
#except HTTPError:
# return "Request Error"
except Exception as e:
print(e)
pass
def saveTocsv(data, city):
'''
将天气数据保存至csv文件
'''
fileName='./' + city_dict[city] + '_weather.csv'
result_weather = pd.DataFrame(data, columns=['date','tq','temp','wind'])
# print(result_weather)
result_weather.to_csv(fileName, index=False, encoding='gb18030')
print('Save all weather success!')
def saveToMysql(data):
'''
将天气数据保存至MySQL数据库
'''
#建立连接
conn = pymysql.connect(host="localhost", port=3306, user='root', passwd='pass', database='wea', charset="utf8")
#获取游标
cursor = conn.cursor()
sql = "INSERT INTO weather(date,tq,temp,wind) VALUES(%s,%s,%s,%s)"
data_list = np.ndarray.tolist(data) #将numpy数组转化为列表
try:
cursor.executemany(sql, data_list)
print(cursor.rowcount)
conn.commit()
except Exception as e:
print(e)
conn.rollback()
cursor.close()
conn.close()
def get_data(url):
print(url)
try:
soup = get_soup(url)
all_weather = soup.find('div', class_="wdetail").find('table').find_all("tr")
data = list()
for tr in all_weather[1:]:
td_li = tr.find_all("td")
for td in td_li:
s = td.get_text()
# print(s.split())
data.append("".join(s.split()))
# print(data)
# print(type(data))
res = np.array(data).reshape(-1, 4)
# print(res)
# print(type(res[0]))
# print(res[0][1])
return res
except Exception as e:
print(e)
pass
if __name__ == '__main__':
for city in city_dict.keys():
print(city, city_dict[city])
data_ = list()
urls = get_urls(city)
for url in urls:
try:
data_.extend(get_data(url)) #列表合并,将某个城市所有月份的天气信息写到data_
except Exception as e:
print(e)
pass
saveTocsv(data_, city)#保存为csv