sql Service 海量数据查询,如何提高查询效率--数据库分区
转:原文地址 https://www.51baidu.com.cn/Home/Detail/2501
问题:有一个张销售表, 每天会插入数万条销售数据,随着数据的增加, 查询越来越慢,加上各种筛选条件,查询速度就更慢了,例如数据库分区可以有效解决这个问题。下面就来看一下如何实现sql service 数据库分区。
假设:有一张销售表,里面有两百万条数据(这个还算少了, 怎么也得千万级以上),查询条件, 往年的数据按照年份来查询, 当年的数据按照季度来查询。
根据假设, 我们先弄出一个测试环境吧,
首先我创建了一个数据库, 名字叫 FenQuDemo , 建了一张销售表, 名字叫 FF_SellTable,然后往表里插入了两百万行数据
我们右键查看FF_SellTable的属性, 应该是下图标注的那样
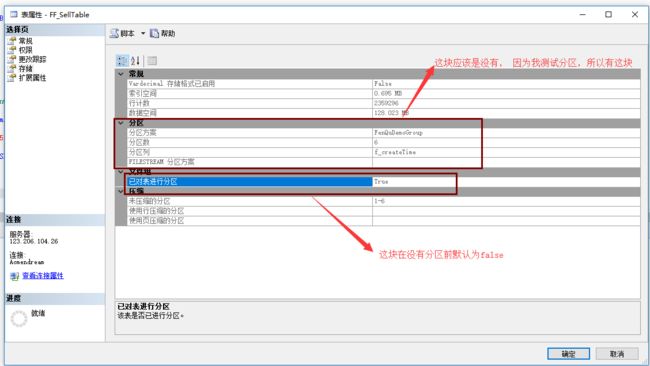
创建分区
数据库FenQuDemo 右键 -> 属性 ->文件

新建5个文件组,对应5个数据库文件,Y2017存放2017年的数据,Q1,Q2,Q3,Q4存放4个季度的数据,这里我们将文件都放在了同一个文件夹,如果条件允许,放在不同的磁盘上会增加读写效率。
建立分区函数
建立分区函数就是在当前数据库中创建一个函数,该函数可根据指定列的值将表或索引的各行映射到分区。 使用 CREATE PARTITION FUNCTION 是创建已分区表或索引的第一步
CREATE PARTITION FUNCTION [FenQuDemoFunc](DATETIME)
AS RANGE RIGHT
FOR VALUES
(N'2018-01-01T00:00:00',N'2018-04-01T00:00:00', N'2018-07-01T00:00:00',N'2018-10-01T00:00:00',N'2019-01-01T00:00:00');具体语法和参数请看:使用CREATE PARTITION FUNCTION 建立分区函数,以及参数介绍
注:如果运行上面的sql语句报错, 错误信息为:“消息 7736,级别 16,状态 1,第 1 行只能在 SQL Server Enterprise Edition 中创建分区函数。只有 SQL Server Enterprise Edition 支持分区。”这是因为你安装的sql不是企业版,数据库分区是企业版才有的功能, 这里是企业版数据库的安装地址,可以去下载安装:SQL Server Management Studio(2012,简体中文企业版)
建立分区方案
在当前数据库中创建一个将已分区表或已分区索引的分区映射到文件组的方案。 已分区表或已分区索引的分区的个数和域在分区函数中确定
CREATE PARTITION SCHEME [FenQuDemoGroup] AS PARTITION [FenQuDemoFunc] TO ([year2017], [Q1],[Q2],[Q3],[Q4])具体语法和参数请看:使用 CREATE PARTITION SCHEME 建立分区方案,以及参数介绍
建好的分区函数和分区方案如下:分区方案和分区函数下会多出一个文件
建立分区索引
CREATE CLUSTERED INDEX [ClusteredIndex_CreateDate] ON [dbo].[FF_SellTable]
(
[f_createTime]
)WITH (SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF) ON [FenQuDemoGroup]([f_createTime])
参数:
ClusteredIndex_CreateDate 索引名称
FF_SellTable 表名(要对那张表进行分区)
f_createTime 列名(要根据哪一列进行分区)
FenQuDemoGroup 分区方案名称
这样表分区就完成了
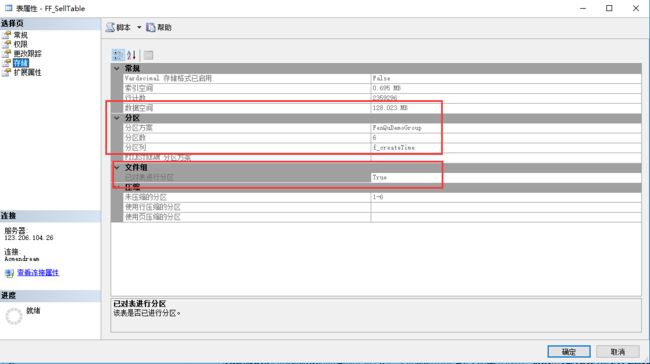
接下来我们就可以对数据库进行分区查询了,
select $PARTITION.FenQuDemoFunc(f_createTime) as 分区编号,count(ID) as 记录数 from FF_SellTable group by $PARTITION.FenQuDemoFunc(f_createTime)运行结果如下:
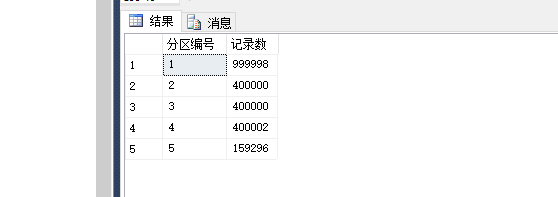
查询具体的分区语法为:
SELECT TOP 100 * from FF_SellTable WHERE $PARTITION.FenQuDemoFunc(f_createTime) = 5
至于参数具体意思,以及其他的语法,可以参考 $PARTITION (Transact-SQL)
分区新增和合并
现在如果是2019年,需要将2018年的四个季度(Q1,Q2,Q3,Q4)合并成一个新的文件组 year2018,而之前的Q1,Q2,Q3,Q4存放2019年四个季度的数据。
1.新建2018文件组
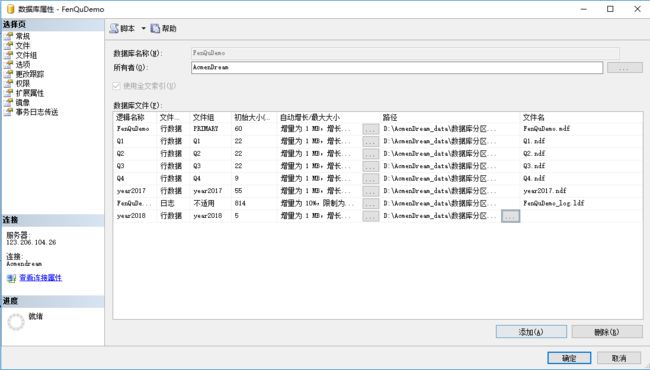
2.合并分区
先将所有季度文件组都合并,这样2019年数据之前都在2017文件组
ALTER PARTITION FUNCTION FenQuDemoFunc() MERGE RANGE (N'2018-01-01T00:00:00');
ALTER PARTITION FUNCTION FenQuDemoFunc() MERGE RANGE (N'2018-04-01T00:00:00');
ALTER PARTITION FUNCTION FenQuDemoFunc() MERGE RANGE (N'2018-07-01T00:00:00');
ALTER PARTITION FUNCTION FenQuDemoFunc() MERGE RANGE (N'2018-10-01T00:00:00');
可以在分区方案上查看创建SQL语句,这时的分区方案已经更改为:
CREATE PARTITION SCHEME [FenQuDemoGroup] AS PARTITION [FenQuDemoFunc] TO ([Y2017], [PRIMARY])
3.分区新增
首先将2018年的数据放在year2018文件组
--选择文件组
ALTER PARTITION SCHEME FenQuDemoGroup
NEXT USED [year2018] ;
--修改分区函数
ALTER PARTITION FUNCTION FenQuDemoFunc()
SPLIT RANGE (N'2018-01-01T00:00:00.000') ;
同理将2019年的数据分别放在2019年的各个季度中
ALTER PARTITION FUNCTION FenQuDemoFunc() MERGE RANGE (N'2018-01-01T00:00:00');
ALTER PARTITION SCHEME FenQuDemoGroup NEXT USED [Q1];
ALTER PARTITION FUNCTION FenQuDemoFunc() SPLIT RANGE (N'2018-01-01T00:00:00.000');
ALTER PARTITION SCHEME FenQuDemoGroup NEXT USED [Q2];
ALTER PARTITION FUNCTION FenQuDemoFunc() SPLIT RANGE (N'2018-04-01T00:00:00.000');
ALTER PARTITION SCHEME FenQuDemoGroup NEXT USED [Q3];
ALTER PARTITION FUNCTION FenQuDemoFunc() SPLIT RANGE (N'2018-07-01T00:00:00.000');
ALTER PARTITION SCHEME FenQuDemoGroup NEXT USED [Q4];
ALTER PARTITION FUNCTION FenQuDemoFunc() SPLIT RANGE (N'2018-10-01T00:00:00.000');
创建分区方案
CREATE PARTITION FUNCTION [FenQuDemoFunc](datetime)
AS RANGE RIGHT
FOR VALUES (
N'2017-01-01T00:00:00.000',
N'2018-01-01T00:00:00.000',
N'2019-04-01T00:00:00.000',
N'2019-07-01T00:00:00.000',
N'2019-10-01T00:00:00.000'
)
创建分区函数
CREATE PARTITION SCHEME [FenQuDemoGroup] AS PARTITION [FenQuDemoFunc] TO ([year2017], [year2018], [Q1], [Q2], [Q3], [Q4])上述语法,参数可以参考:ALTER PARTITION FUNCTION (Transact-SQL)
除了合并分区还有一个其他的办法, 就是现将分区转换为普通表,然后在进行分区,步骤为:先删除表中的索引,然后在重新创建索引,创建索引如下
CREATE CLUSTERED INDEX [index_sellTable] ON dbo.FF_SellTable(f_createTime) ON [Primary]
创建完之后刷新一下, 查看表的属性:
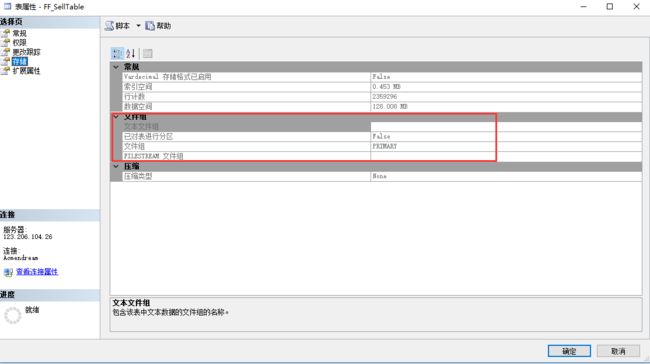
原文地址:白码驿站