HIbernate总结
Hibernate


数据库语言分类:
下边是实体类的基本配置
<hibernate-mapping package="com.wbs.domain">
<class name="Customer"table="cust_customer">
<id name="cusID" column="cust_id">
<generator class="native">generator>
id>
<property name="cusname" column="cust_cusname">property>
<property name="cusSource" column="cust_cusSource">property>
<property name="cusIndustry" column="cust_cusIndustry">property>
<property name="cusLevel" column="cust_cusLevel">property>
<property name="cusAddress" column="cust_cusAddress">property>
<property name="cusPhone" column="cust_cusPhone">property>
class>
hibernate-mapping>
这是session factory的配置
<hibernate-configuration>
<session-factory>
<property name="hibernate.connection.driver_class">oracle.jdbc.driver.OracleDriverproperty>
<property name="hibernate.connection.url">jdbc:oracle:thin:@localhost:1521:ORCLproperty>
<property name="hibernate.connection.username">systemproperty>
<property name="hibernate.connection.password">wbs19950305property>
<property name="hibernate.dialectt">org.hibernate.dialect.Oracle8iDialecproperty>
<property name="hibernate.show_sql">trueproperty>
<property name="hibernate.format_sql">trueproperty>
<property name="hibernate.hbm2ddl.auto">updateproperty>
<mapping resource="com/wbs/domain/Customer.xml"/>
session-factory>
hibernate-configuration>
Configuration对象
Configuration cfg=new Configuration();//只是创建,并非加载xml文件
加载文件的方式有3种
1. cfg.configure();//加载默认位置的名称和配置文件
2. cfg.addResource("com/wbs/domain/Customer.xml");、、这样加载配置文件也可的
3. cfg.addClass(Customer.class);
SessionFactory对象
线程安全的
一个应用应该有一个sessionFactory,在应用加载时候创建,在应用卸载时候销毁

Session对象
负责操作数据库
一个线程只能有一个对象


Transaction对象
C3p0连接池的配置
需要在SessionFactory的配置中加入下边这句话:
org.hibernate.connection.C3P0ConnectionProvider
这个配置在hibernate.properties这个配置文件中可以找到。
Hibernate一个查询的方法
* hibernate中查询的方法
* get方法
* get(Classclass,Serializable id)
* load方法
* load(Classclass,Serializable id)
* 共同点:
* 都是根据ID查询一个实体
* 区别:
* 1:查询的时机不一样,
* get的时机,每次调用get方法时候,马上发起查询, 立即加载
* load查询时机,每次真正使用的时候,发起查询,,延迟加载,懒加载,惰性加载
* 2:返回的结果不一样
* get方法返回的实体类类型
* load返回的结果是实体类类型的代理对象
* load的方法默认是延迟,可以通过修改配置的方式改为立即加载
笔记2
1. 实体类的编写规范
应该遵循javabean的编写规范
Bean是软件开发中的可重用组件
Javabean值的是Java语言编写的可重用的组件,domain、service、dao都可以看成是JavaBean
编写规范:
1类都是public的
2一般都实现序列化接口
3类成员都是私有的
4私有成员都有set/get方式
5类都有默认的无参构造方法
细节:
数据类型的选择问题(选择包装类(Long))
2. Hibernate中的对象标识符
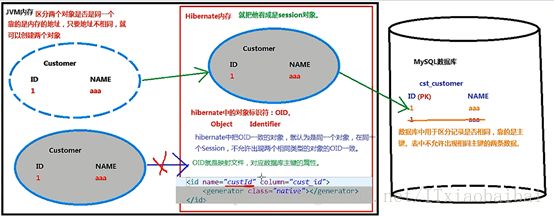
3. Hibernate的主键的生成策略
Native



Sequence用于Oracle数据库,assigned一般不用,Hilo是高低位算法,如下:

4. Hibernate的一级缓存和快照技术
1)什么缓存:内存中的临时数据
2)为什么使用缓存:减少和数据库交互的次数,从而提高效率
3)什么样的数据适用于缓存:经常查询的、并且不经常修改的、同时数据一旦出现问题,对结果影响不大的
4)不适用缓存的数据:不经常查询,经常修改的,如果使用缓存产生了异常,对结果产生了很大的影响,如:股市的牌价,银行的汇率,商品的库存等等
5)Hibernate的一级缓存:它是值Session对象的缓存,一旦Session对象销毁了,一级缓存也就消失了
publicvoid test1(){
Session s=HibernateUtils.openSession();
Transaction tx=s.beginTransaction();
//根据ID查询客户
Customer c=s.get(Customer.class, 8L);//先去数据库查询,并把结果存入一级缓存
System.out.println(c);
//根据ID再次查询客户
Customer c1=s.get(Customer.class,8L);//先去一级缓存中看有没有,有的话直接拿过来,没有的话再去查询
System.out.println(c1);
System.out.println(c==c1);//true
tx.commit();
s.close();//Session关闭,缓存消失
}
其原理如下:根据Session找到对应的类字符串,在根据OID找到所需的对象。

6如果下边这个代码,当查找后继续修改,在此时并未用代码明确写出update,但是在提交的时候,它会去快照区查看是否和一级缓存区的一致(这个是根据OID来判断的),如果一致的话,不会对数据库进行修改,如果不一致的话,则对数据库进行修改
publicvoid test2(){
Session s=HibernateUtils.openSession();
Transaction tx=s.beginTransaction();
//根据ID查询客户
Customer c=s.get(Customer.class, 8L);//先去数据库查询,并把结果存入一级缓存
System.out.println("1111111111"+c.getCusAddress());//此时是西山校区
c.setCusAddress("甘肃省");
//没有写Update
tx.commit();
s.close();//Session关闭,缓存消失
System.out.println("22222222222"+c.getCusAddress());
}
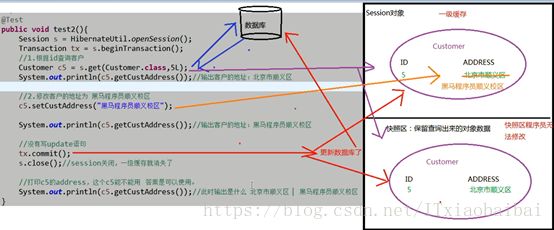
快照区都是Session对象的,当Session对象一消失,都会消失
5. Hibernate的对象状态(三种状态、四种状态)
1)瞬时状态(临时状态)
没有OID,和Session没有关系
2)持久化状态
有OID,和session有关系。只有持久化状态的对象才会有一级缓存,没有提交事务之前数据库没有记录,
3)脱管状态(游离状态)
有OID,和session没有关系
4)删除状态(了解)
标志:有OID,和Session有关系,同时已经调用了删除方法,即将从数据库把记录删除,但是事务还未提交,此时的对象状态是删除状态
publicclass HibernateDemo5 {
@Test
publicvoid test1(){
Customer c=new Customer();//瞬时状态
c.setCusname("练习题");
Session s1=HibernateUtils.openSession();
Transaction tx1=s1.beginTransaction();
c.setCusAddress("大连");//
s1.save(c);//持久化状态
tx1.commit();//没有提交事务之前数据库没有记录
s1.close();
c.setCusAddress("北京");//脱管状态(脱离了Session的管理)
Session s2=HibernateUtils.openSession();
Transaction tx2=s2.beginTransaction();
s2.update(c);//持久化状态
tx2.commit();
s2.close();
System.out.println(c);//脱管状态
}
目的:为了更好掌握
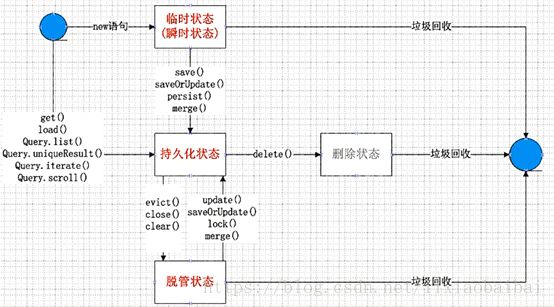
Close()之session不能用了,clear()之后session还是可以用的,下边写一些saveOrUpdate的方法的使用
@Test
publicvoid test2(){
Customer c=new Customer();//瞬时状态
c.setCusname("练习题2");
Session s=HibernateUtils.openSession();
Transaction tx=s.beginTransaction();
s.saveOrUpdate(c);//此时用save方法,因为是从瞬时状态转为持久状态
tx.commit();
s.close();
}
@Test
publicvoid test3(){
Session s=HibernateUtils.openSession();
Transaction tx=s.beginTransaction();
Customer c=s.get(Customer.class, 21L);//持久化状态
tx.commit();
s.close();
c.setCusAddress("更新");
System.out.println(c);//脱管状态
Session s1=HibernateUtils.openSession();
Transaction tx1=s1.beginTransaction();
s1.saveOrUpdate(c);//此时用update方法,因为是从持久状态转为脱管状态
tx1.commit();
s1.close();
}
6. Hibernate中的事物控制
解决问题:让Session对象也符合使用原则
Session对象的使用原则:一个线程只能有一个session
当我们把线程和session绑定之后,hibernate在提交或者回滚事务之后,会自动关闭Session
/**
* 从当前线程上边获取Session对象
* 当我们把线程和session绑定之后,hibernate在提交或者回滚事务之后,会自动关闭Session
*/
publicstatic Session getCurrentSession(){
returnfactory.getCurrentSession();//只有设置了把session和当前线程绑定了之后,才能使用此方法,不然的到的是null
}
怎么样实现session和线程的绑定(在hibernate配置文件中设置),如下:
<property name="hibernate.current_session_context_class">threadproperty>
但是也可以自己写一个函数实现。如下:
private static ThreadLocal
publicstatic Session openSession(){
Session s=tl.get();
if(s==null){
tl.set(factory.openSession());
}
s=tl.get();
returns;
}
7. Hibernate中的查询方式
Hibernate查询多条的方式,一共有五种
1.OID查询:get()和Load()方法
2.SQL查询:
SQLQuery()(一般不用);
Session的doWork()方法,它可以拿到Connection
publicvoid testFindAll(){//查询所有
Session s=HibernateUtils.openSession();
Transaction tx=s.beginTransaction();
//使用session对象,获取一个查询对象query
SQLQuery sqlquery=s.createSQLQuery("select * from CUST_CUSTOMER");
//使用sqlquery对象获取结果集
Listlist();//注意,这个查找到的是一个对象数组
for (Object[] o :list){
System.out.print("-----数组中的内容---------");
for( Object a:o){
System.out.println(a);
}
}
tx.commit();
s.close();
}
publicvoid test1(){
//doWork()方法
//获取session对象
Session s=HibernateUtils.openSession();
//调用doWork方法
s.doWork(new Work() {
@Override
publicvoid execute(Connection arg0) throws SQLException {
System.out.print(arg0.getClass().getName());
}
});
}
3.使用HQL查询(使用HQL语句查询数据库)
4.QBC查询(使用Criteria对象查询数据库)
5.对象导航查询
8. Hibernate中的query对象
它是hibernate中HQL查询方式(hibernate query Language)
1. 如何获取该对象:session对象的方法
2. 涉及的对象和方法:createQuery(Stringsql)
3. 方法中参数的含义
SQL:selectcust_id from customer
HQL:select custId from customer
HQL语句是吧sql语句的表明换成类名,把字段名换成实体类的属性名称
//基本查询
@Test
publicvoid test1(){
Session s=HibernateUtils.getCurrentSession();
Transaction tx=s.beginTransaction();
//查询所有的对象
//1获取Query对象
Query query=s.createQuery("from Customer");//注意此时的是实体类对象Customer
//2执行获取结果集
List list=query.list();
for(Object o:list){
System.out.println(o);
}
tx.commit();//此时不需要手动关闭session,因为hibernate会自动关闭
}
单条件查询:注意(在设置?占位符的时候,需要在问号后边加上相应的数字,在设置参数的时候,根据其设置的数字进行赋值)
//条件查询
@Test
publicvoid test2(){
Session s=HibernateUtils.getCurrentSession();
Transaction tx=s.beginTransaction();
//查询所有的对象
//1获取Query对象
//Query query=s.createQuery("from Customer wherecusLevel=?0");//传统的?占位符
//query.setString(0, "23");
Query query=s.createQuery("from Customer where cusLevel = :cusLevel");//hibernate的占位符,用分号开头
//query.setString("cusLevel","23");//可以用之前的jdbc的参数赋值方法
query.setParameter("cusLevel", "23");//hibernate的赋值方法
//2执行获取结果集
List list=query.list();
for(Object o:list){
System.out.println(o);
}
tx.commit();
}
多条件查询:
publicvoid test3(){
Session s=HibernateUtils.getCurrentSession();
Transaction tx=s.beginTransaction();
//查询所有的对象
//1获取Query对象
//Query query=s.createQuery("from Customer where cusLevel = ?0 and cusnamelike ?1");//注意此时的是实体类对象Customer
Query query=s.createQuery("from Customer where cusLevel =:cusLevel and cusnamelike :cusname");
/*query.setString(0, "23");
query.setString(1, "%大连%");*/
query.setParameter("cusLevel", "23");
query.setParameter("cusname", "%大连%");
//2执行获取结果集
List list=query.list();
for(Object o:list){
System.out.println(o);
}
tx.commit();
}
排序查询:默认是升序asc,desc是降序
publicvoid test4(){
Session s=HibernateUtils.getCurrentSession();
Transaction tx=s.beginTransaction();
//查询所有的对象
//1获取Query对象
Query query=s.createQuery("from Customer order by cusID desc");
//2执行获取结果集
List list=query.list();
for(Object o:list){
System.out.println(o);
}
tx.commit();
}
分页查询:
1.Hibernate提供了两个方法setFirstResult()à设置查询开始的记录(数字的设置是当前页减1,再乘以每页显示的条数)
2.setMaxResult()à设置每次查询的条数
不管使用什么数据库,都用的是这两个方法,依据是配置文件的数据库方言
publicvoid test5(){
Session s=HibernateUtils.getCurrentSession();
Transaction tx=s.beginTransaction();
//查询所有的对象
//1获取Query对象
Query query=s.createQuery("from Customer ");
query.setFirstResult(0);//数字的设置是当前页减1,再乘以每页显示的条数
query.setMaxResults(2);
//2执行获取结果集
List list=query.list();
for(Object o:list){
System.out.println(o);
}
tx.commit();
}
统计查询:count avg sum maxmin
注意:uniqueResult()方法只接受返回的结果是唯一的执行结果,若不唯一的话会抛出异常
//统计查询
/**
* 在HQL中使用聚合函数,count sum avg max min
*/
@Test
publicvoid test6(){
Session s=HibernateUtils.getCurrentSession();
Transaction tx=s.beginTransaction();
//查询所有的对象
//1获取Query对象
Query query=s.createQuery(" select count(*) from Customer ");
//2执行获取结果集
/*List list=query.list();
for(Object o:list){
System.out.println(o);
}*/
Long l=(Long) query.uniqueResult();//如果结果唯一的时候,用此方法接受参数,若返回的结果不唯一,会抛出异常
System.out.println(l);
tx.commit();
}
4. 常用的方法说明
9. Hibernate中的Criteria对象
用HQL可以实现的查询也可以通过Criteria实现,是更加面向对象的一种查询方式。把生成语句的过程融入到了方法之中
Criteria是QBC查询(Create By Criteria)
如何获取对象:session.cteateCriteria(Classclass)
涉及对象的方法:CreateCriteria(Classclass)
参数的含义:要查询的实体类字节码
1.基本查询:
//基本查询
@Test
publicvoid test1(){
Session s=HibernateUtils.getCurrentSession();
Transaction tx=s.beginTransaction();
//获取Criteria对象
Criteria criteria=s.createCriteria(Customer.class);
//获取结集
List list=criteria.list();
for(Object o:list){
System.out.println(o);
}
tx.commit();
}
2.条件查询,若有多个条件,直接再添加criteria.add();方法往里面 添加条件
//条件查询
@Test
publicvoid test2(){
Session s=HibernateUtils.getCurrentSession();
Transaction tx=s.beginTransaction();
//获取Criteria对象
Criteria criteria=s.createCriteria(Customer.class);
//添加条件
criteria.add(Restrictions.eq("cusLevel", "23"));
criteria.add(Restrictions.like("cusname", "%大连%"));
//获取结集
List list=criteria.list();
for(Object o:list){
System.out.println(o);
}
tx.commit();
}
笔记3
1. 数据库中的表关系
一对一、一对多(多对一)、多对一
2. 如何确立表中的表关系
一对多的关系如何实现:使用外键约束,一的方称为主表,多的方称为从表。
外键:从表中有一列,该列的取值除了null之外,只能来源于主表的主键,默认情况下,外键字段的值是可以重复的
多对多的表关系如何实现?
使用中间表,中间表只能有两个外键,引用两个多对多表的主键,不能有其他字段信息,中间表的主键采用联合主键
如果任何一个多方的表和中间表比较,都是一对多的关系。
一对一的表关系在数据库中如何实现?两种
1.建立外键的方式:
使用外键约束、唯一约束、非空约束,他是把外键约束加了唯一约束和非空约束,从而实现一对一。
2.使用主键的方式:
让其中一张表既是主键,又是外键
如何确定两张表之间的关系:找外键
3. 多表映射遵循的步骤
第一步:确立两张表之间的关系
第二步:在数据库中实现多对多的表关系的建立
第三步:在实体类中描述出两个实体类之间的关系
第四步:在映射配置中建立两张表和两个实体之间的关系
4. 一对多关系映射配置及其操作
实例:客户和联系人两张表
第一步:确立两张表之间的关系
一个客户可以包含多个联系人,多个联系人可以属于同一个客户,所以客户和联系人是多对多的关系
第二步:在数据库中实现多对多的表关系的建立
实现一对多的关系靠的是外键,客户是主表,联系人是从表,需要在联系人表中添加外键
第三步:在实体类中描述出两个实体类之间的关系
主表的实体类包含从表实体类的集合引用
<set name="linkmans" table="cust_linkman">
<key column="lkm_cust_id" >key>
<one-to-many class="LinkMan">one-to-many>
set>
从表的实体类应该包含主表实体类的对象引用
xml version="1.0" encoding="UTF-8"?>
DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/HibernateMapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="com.wbs.domain">
<class name="LinkMan"table="cust_linkman">
<id name="lkmId" column="lkm_id">
<generator class="native">generator>
id>
<property name="lkmName" column="cust_lkmName">property>
<property name="lkmGender" column="cust_lkmGender">property>
<property name="lkmPhone" column="cust_lkmPhone">property>
<property name="lkmMobile" column="cust_lkmMobile">property>
<property name="lkmEmail" column="cust_lkmEmail">property>
<property name="lkmPosition" column="cust_lkmPosition">property>
<property name="lkmMemo" column="cust_lkmMemo">property>
<many-to-one name="customer" class="Customer"column="lkm_cust_id">many-to-one>
class>
第四步:在映射配置中建立两张表和两个实体之间的关系
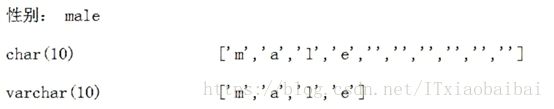
字符在数据库中用char或者varchar,但是在实体类中用String或者Criteria
5. 多对多关系映射配置及其操作
1. 确定两张表之间的关系
一个用户可以有多个角色
一个角色可以赋给多个角色
所以用于和角色之间是多对多
2. 数据库中两张表之间的关系建立
在数据库中实现多对多要靠中间表
中间表只能出现用户和角色的主键
3. 在实体类中描述出两个实体类之间的关系
各自包含对方一个集合引用
下边是多对多关系中的一个映射配置文件中的一部分
<set name="roles" table="user_role_ref">
<key column="user_id">key>
<many-to-many class="SysRole" column="role_id">many-to-many>
set>

上边是数据库里面创建联合主键的方式
6. 进行多对多之间的保存操作
需要在任何一个set配置inverse=true,让某个实体类放弃维护关系,才可以正常的执行保存功能。
publicclass HibernateDemo1 {
/**
* 保存操作;
* 创建两个用户和三个角色
* 让1号用户具备具备1号和2号角色
* 让2号用户具备具备3号和2号角色
* 保存用户和角色
*/
@Test
publicvoid test1(){
SysUser u1=new SysUser();
u1.setUserName("用户1");
SysUser u2=new SysUser();
u1.setUserName("用户2");
SysRole r1=new SysRole();
r1.setRoleName("角色1");
SysRole r2=new SysRole();
r1.setRoleName("角色2");
SysRole r3=new SysRole();
r1.setRoleName("角色3");
//建立双向关联关系
u1.getRoles().add(r1);
u1.getRoles().add(r2);
u2.getRoles().add(r2);
u2.getRoles().add(r3);
//再建立角色
r1.getUsers().add(u1);
r2.getUsers().add(u1);
r2.getUsers().add(u2);
r3.getUsers().add(u2);
Session s=HibernateUtils.getCurrentSession();
Transaction tx=s.beginTransaction();
s.save(r3);
s.save(r2);
s.save(r1);
s.save(u1);
s.save(u2);
tx.commit();
}
7. 删除操作(实际开发禁止使用)
但是需要级联删除的时候需要配置级联的任一个配置文件的inverse=true,需要在两个多对多的实体类的配置文件中写出cascade=delete,不然不会级联删除
<set name="users"table="user_role_ref" inverse="true"cascade="delete">
<key column="role_id">key>
<many-to-many class="SysUser" column="user_id">many-to-many>
set>
/**
* 删除操作
* 实际开发中多对多的双向级联删除是禁止的
*/
@Test
publicvoid test2(){
Session s=HibernateUtils.getCurrentSession();
Transaction tx=s.beginTransaction();
//查询ID为103的用户
SysUser u=s.get(SysUser.class, 115L);
System.out.println(u);
s.delete(u);
tx.commit();
}
笔记4
一对多关系映射的crud操作:
1.单项的保存操作
/**
* 保存操作
* 正常的保存:创建一个联系人,需要关联客户
*/
@Test
publicvoid test1(){
Session s=HibernateUtils.getCurrentSession();
Transaction tx=s.beginTransaction();
//1.查询一个客户
Customer c1=s.get(Customer.class,1L);
//2.创建一个联系人
LinkMan l=new LinkMan();
l.setLkmName("一对多的联系人");
//3.建立客户联系人的关联关系(让联系人知道他属于哪个客户)
l.setCustomer(c1);
//4.保存联系人
s.save(l);
tx.commit();
}
2.双向的保存操作:
/**
* 创建一个客户和一个联系人,创建客户和联系人的双向关系
* 使用符合原则的保存
* 先保存主表的实体,再保存从表的实体
* 此时保存会有问题:
* 保存应该只是两条insert语句,而执行结果是多了一条Update
*/
@Test
publicvoid test2(){
Session s=HibernateUtils.getCurrentSession();
Transaction tx=s.beginTransaction();
//1.创建一个客户
Customer c1=new Customer();//瞬时态对象
c1.setCusname("一对多别的客户2");
//2.创建一个联系人
LinkMan l=new LinkMan();//瞬时态对象
l.setLkmName("一对多的联系人2");
//3.建立客户联系人的关联关系(双向)
l.setCustomer(c1);
c1.getLinkmans().add(l);
//4.保存,要符合原则
s.save(c1);//持久态,会有一级缓存和快照,有OID,和session有关系
s.save(l);//持久态,会有一级缓存和快照,有OID,和session有关系
tx.commit();
}
注意:在此函数执行的时候,先执行了两条insert语句,然后执行了一条update语句,其原因如下:

是因为Hibernate的快照技术,使得先后执行的语句在快照区的内容不一样,只能在最后commit的时候重新刷新数据库,从而有了一条update语句。
解决办法:让客户在执行操作的时候,放弃维护关联关系的权利。
* 配置的方式,在customer的映射配置文件的set标签使用inverse属性
*inverse:是否放弃维护关联关系的权利,true:是,false:否(默认值)
<set name="linkmans"table="cust_linkman" inverse="true">
<key column="lkm_cust_id" >key>
<one-to-many class="LinkMan">one-to-many>set>
3.一对多的级联保存
加入有很多订单,一个一个保存太麻烦,直接用级联保存,就可以一次保存完,而不再用传统的方式一个一个去保存,方法如下:
/**
* 保存操作,级联操作
* 使用级联保存,配置的方式,
* 使用customer的set标签
* 在上面加入cascade属性
* cascade:配置级联操作
* 级联保存更新的保存:save-update
* 也可以配置在
*/
@Test
publicvoid test3(){
Session s=HibernateUtils.getCurrentSession();
Transaction tx=s.beginTransaction();
//1.创建一个客户
Customer c1=new Customer();//瞬时态对象
c1.setCusname("一对多别的客户4");
//2.创建一个联系人
LinkMan l=new LinkMan();//瞬时态对象
l.setLkmName("一对多的联系人4");
//3.建立客户联系人的关联关系(双向)
l.setCustomer(c1);
c1.getLinkmans().add(l);
//4.保存,要符合原则
s.save(c1);//只保存了c1
tx.commit();
}
@Test
publicvoid test4(){
Session s=HibernateUtils.getCurrentSession();
Transaction tx=s.beginTransaction();
//1.创建一个客户
Customer c1=new Customer();//瞬时态对象
c1.setCusname("一对多别的客户5");
//2.创建一个联系人
LinkMan l=new LinkMan();//瞬时态对象
l.setLkmName("一对多的联系人5");
//3.建立客户联系人的关联关系(双向)
l.setCustomer(c1);
c1.getLinkmans().add(l);
//4.保存,要符合原则
s.save(l);//只保存了l
tx.commit();
}
注意:在此时的实体类的映射配置中需要加入:
1,
<set name="linkmans"table="cust_linkman" inverse="true" cascade="save-update">
<key column="lkm_cust_id" >key>
<one-to-many class="LinkMan">one-to-many>
set>
2.<many-to-one name="customer" class="Customer"column="lkm_cust_id" cascade="save-update">many-to-one>
用这两种方式都可以实现只需要在代码中保存一个实体,即可保存所有级联实体,只不过配置时候注意要对应配置。
4.更新操作,双向的操作
/**
* 更新操作:创建一个联系人,查询一个已有客户
* 建立新联系人和已有客户的双向关联关系
* 更新联系人
*/
@Test
publicvoid test5(){
Session s=HibernateUtils.getCurrentSession();
Transaction tx=s.beginTransaction();
//1.查询一个客户
Customer c1=s.get(Customer.class,3L);
//2.创建一个联系人
LinkMan l=new LinkMan();
l.setLkmName("一对多的联系人1");
//3.建立客户联系人的关联关系(双向)
l.setCustomer(c1);
c1.getLinkmans().add(l);
//4.更新客户
s.update(c1);
tx.commit();
}
需要注意的是在此时如果set的配置标签里面如果配置了inverse="true"的话,会忽略更新的,这儿需要注意一下,但是cascade必须是save-update,因为在update之前是没有保存那个联系人l,如果不设置这个的话直接报错的。
5.删除操作
1.删除的时候如果是从表,则直接删除,若是主表,同时从表的外键可以为null的时候,删除主表的同时直接将其从表中的外键直接置为null
/**
* 删除操作
* 删除从表就是单表
* 删除主表数据
* 先看从表数据引用
* 有引用:hibernate会吧从表中的外键置位null,然后再删除
* 无引用:直接删
*/
@Test
publicvoid test6(){
//此时的外键允许为null
Session s=HibernateUtils.getCurrentSession();
Transaction tx=s.beginTransaction();
//1.查询一个客户
Customer c1=s.get(Customer.class,68L);
//删除ID为68的客户
s.delete(c1);
tx.commit();
}
2.若果从表中要删除某个主表的数据,并且要删除与它级联的从表中的数据,则需要配置级联删除,如下,但是不建议使用该级联删除,是一个很危险的操作
<set name="linkmans"table="cust_linkman" inverse="false" cascade="save-update,delete">
<key column="lkm_cust_id" >key>
<one-to-many class="LinkMan">one-to-many>
set>
若从表的外键约束为not null的话,想要在主表中删除某数据,并且此数据在从表中有对应的外键引用,则需要配置主表的额inverse=true,只有配置了这个才可以级联删除,因为只有这样的话,主表才不会维护他的约束,才可以允许级联删除不。
6.对象导航查询
一对多的查询操作:OID查询,QBC查询,SQL查询
hibernate中的最后一种查询方式,对象导航查询
当两个实体类之间有关联关系时候(可以是任一一种)
通过调用getXXX方法即可达到实现查询功能(是有hibernate提供的方法)
eg:customer.getLinkMans()就可以得到当前客户的所有联系人
通过linkman.getCustomer()就可以得到当前联系人的所属客户
1. 注意:一对多时候,根据一的一方查询多的一方是,需要使用延迟加载lazy=true(默认配置即可)
<set name="linkmans"table="cust_linkman" lazy="true">
<key column="lkm_cust_id" >key>
<one-to-many class="LinkMan">one-to-many>
set>
/**
*查询ID为1的客户下的所属联系人
*/
@Test
publicvoid test1(){
Session s=HibernateUtils.getCurrentSession();
Transaction tx=s.beginTransaction();
Customer c=s.get(Customer.class, 1L);//查询ID为1的客户
/*System.out.println(c);
System.out.println(c.getLinkmans());*/
Set
System.out.println(c);
System.out.println(linkmans);//注意此时是连查询带打印,而不是先查询,在打印
tx.commit();
}
2.多对一时候,根据多的一方查询一的一方时候,不需要使用延迟加载,而是立即加载,需要配置一下,需要找到联系人的
<class name="LinkMan"table="cust_linkman" lazy="false"><many-to-onename="customer" class="Customer"column="lkm_cust_id" lazy="proxy">many-to-one>
class>
/**
*查询ID为5的联系人属于哪个客户
*.多对一时候,根据多的一方查询一的一方时候,不需要使用延迟加载,而是立即加载,
*需要配置一下,需要找到联系人的
*使用lazy属性,
* 取值有:
* false(立即加载),
* proxy(看是load方法是延迟加载,还是立即加载)
*/ @Test
publicvoid test2(){
Session s=HibernateUtils.getCurrentSession();
Transaction tx=s.beginTransaction();
LinkMan l=s.get(LinkMan.class,5L);
System.out.println(l);
System.out.println(l.getCustomer());//注意此时是连查询带打印,而不是先查询,在打印
tx.commit();
}
4. 关于load方法的是否延迟加载
在多的一方配置文件里面的class属性设置lazy=false(这个地方的lazy只负责load方法的加载方式),即立即加载的时候,如果此时设置
/**
* 关于load方法改为立即加载的方式
* 找到查询实体类的映射配置文件,它的class属性上边也有一个lazy属性,是否延迟加载,
* true为延迟加载,false为立即加载
*/
@Test
publicvoid test3(){
Session s=HibernateUtils.getCurrentSession();
Transaction tx=s.beginTransaction();
Customer c=s.load(Customer.class, 1L);//查询ID为1的客户
System.out.println(c);
tx.commit();
}
Class标签的lazy;只能管load的方法是否是延迟加载
Set标签的lazy:管查询关联的集合对象是否延迟加载
Many-to-one标签的lazy:只管查询关联的主表实体是否是立即加载
笔记5
JPA单表操作
可以省去配置每个实体类的.xml文件,用注解的方式在实体类中直接说明就可以了
1.主要配置:
注意:此配置文件必须在src的根目录下边,文件名必须是perisistence.xml
其中的具体配置如下:
xml version="1.0" encoding="UTF-8"?>
<persistence xmlns="http://xmlns.jcp.org/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence
http://xmlns.jcp.org/xml/ns/persistence/persistence_2_1.xsd"
version="2.1">
<persistence-unit name="myJPAUnit"transaction-type="RESOURCE_LOCAL">
<provider>org.hibernate.jpa.HibernatePersistenceProviderprovider>
<class>com.wbs.domain.Customerclass>
<properties>
<property name="hibernate.connection.driver_class" value="oracle.jdbc.driver.OracleDriver"/>
<property name="hibernate.connection.url" value="jdbc:oracle:thin:@localhost:1521:ORCL"/>
<property name="hibernate.connection.username" value="system"/>
<property name="hibernate.connection.password" value="wbs19950305"/>
<property name="hibernate.dialectt" value="org.hibernate.dialect.Oracle8iDialec"/>
<property name="hibernate.show_sql" value="true" />
<property name="hibernate.format_sql" value="true"/>
<property name="hibernate.hbm2ddl.auto" value="update"/>
properties>
persistence-unit>
persistence>
2.获取JPA操作数据库的对象:
其中的createEntityManagerFactory()方法中的参数必须要和persistence.xml中的持久化单元名称一致。
//相当于SessionFactory
privatestatic EntityManagerFactory factory;
static {
factory=Persistence.createEntityManagerFactory("myJPAUnit");
}
//获取JPA操作数据库的对象
publicstatic EntityManagercreateEntityManager(){
returnfactory.createEntityManager();
}
3.具体的操作
/**
* JPA入门案例
* JPA单表操作
* @author bo
*
*/
publicclass JPAtest {
//保存
@Test
publicvoid test1(){
Customer c=new Customer();
c.setCusName("JPA客户1");
//1.获取EntityManager对象
EntityManager em=JPAUtils.createEntityManager();
//获取事务对象,并开启事务
EntityTransaction tx=em.getTransaction();
tx.begin();
//执行保存操作
em.persist(c);
//提交事务
tx.commit();
//关闭资源
em.close();
}
//查找操作,
@Test
publicvoid test2(){
//find是立即加载
//1.获取EntityManager对象
EntityManager em=JPAUtils.createEntityManager();
//获取事务对象,并开启事务
EntityTransaction tx=em.getTransaction();
tx.begin();
//需要把更新的数据查找出来
Customer c=em.find(Customer.class, 161L);
System.out.print(c);
//提交事务
tx.commit();
//关闭资源
em.close();
}
//更新操作
@Test
publicvoid test3(){
//1.获取EntityManager对象
EntityManager em=JPAUtils.createEntityManager();
//获取事务对象,并开启事务
EntityTransaction tx=em.getTransaction();
tx.begin();
//需要把更新的数据查找出来
Customer c=em.find(Customer.class, 161L);
//修改客户的地址为大连
c.setCusAddress("大连");
//提交事务
tx.commit();
//关闭资源
em.close();
}
//更新的另一种方式
//merge合并并更新
@Test
publicvoid test4(){
//1.获取EntityManager对象
EntityManager em=JPAUtils.createEntityManager();
//获取事务对象,并开启事务
EntityTransaction tx=em.getTransaction();
tx.begin();
//需要把更新的数据查找出来
Customer c=em.find(Customer.class, 162L);
//修改客户的地址为大连
c.setCusAddress("dlmu");
em.merge(c);
//提交事务
tx.commit();
//关闭资源
em.close();
}
//删除操作
@Test
publicvoid test5(){
//1.获取EntityManager对象
EntityManager em=JPAUtils.createEntityManager();
//获取事务对象,并开启事务
EntityTransaction tx=em.getTransaction();
tx.begin();
//需要把更新的数据查找出来
Customer c=em.find(Customer.class, 161L);
em.remove(c);
//提交事务
tx.commit();
//关闭资源
em.close();
}
//查询所有
/**
* 涉及的对象是:JPAQuery
* 如何获取该对象:
* EntityManager的createQuery(Stringjpql)方法
* 参数的含义:
* jpql:Java Persistence Query Language
* 写法和HQL相似,也是把表明换成类名,把字段名换成属性名,
* 它在写查询所有时候不能使用 "from 实体类名"
* 需要使用select关键字
* select c from Customer c //前一个c是别名
*/
@Test
publicvoid test6(){
//1.获取EntityManager对象
EntityManager em=JPAUtils.createEntityManager();
//获取事务对象,并开启事务
EntityTransaction tx=em.getTransaction();
tx.begin();
//获取JPA的QUERY对象
Query query=em.createQuery("selectc from Customer c where cusName like ?1 and cusLevel=?2");
//给占位符赋值
query.setParameter(1,"%大连%");
query.setParameter(2, "23");
//执行方法,获取结果集
List list=query.getResultList();
for(Object o:list){
System.out.println(o);
}
//提交事务
tx.commit();
//关闭资源
em.close();
}
说明:
1. persist()方法相当于是save()操作;
2. remove()对应的是delete();
3. find()方法对应get()方法;
4. getReference()是延迟加载;
5. find()是立即加载;
6. uniqueResult()对应getSingleResult(),返回唯一的结果。
7. merge()和update()相似,但是merge干的活update有些不能干;
8. 下边说明merge和update的不同:
当查询了一个对象,关闭了session,有查询了该对象,有修改了该对象,此时如果用update方法的时候会报错,因为第一次查完后对象的状态转变成了托管态,而在此查询该对象,修改的时候是持久态,此时对象的状态时不一样的,在一级缓存外边还有一个改对象,如果此时更新的话,因为两个的对象的OID是一样的,但是却发生了修改,此时若Update的话,两个对象是不能合并的,只能用merge()方法将其更新,即将两个对象合并了。
/**
* 查询ID为3的客户
* 关闭session(清空了一级缓存和快照)
* 修改id为1的客户的名称为英华5公寓
* 在此获取session
* 再次查询ID为1的客户
* 更新刚才修改的客户
*/
@Test
publicvoid test1(){
Session s=HibernateUtils.openSession();
Transaction tx=s.beginTransaction();
Customer c=s.get(Customer.class, 1L);//持久态
tx.commit();
s.close();
//修改客户信息
c.setCusname("英华5公寓");//托管态
Session s1=HibernateUtils.openSession();
Transaction tx1=s.beginTransaction();
//再次查询
Customer c1=s.get(Customer.class, 1L);//持久态
//更新操作
//s1.update(c);//将托管态转换为持久态,update方法是不行的,必须要用到merge方法才可以的
s1.merge(c);
tx1.commit();
s1.close();
}
JPA一对多表操作
1. 一对多实体类的注解写法:
/**
* 客户的实体类
* 使用的注解都是JPA规范下的,所以导包,都需要导入javax.persistence下的包
*/
@Entity//表明该类是一个实体类
@Table(name="jpa_cus_customer")//建立当前类和数据库表的对应关系
publicclass Customer implements Serializable {
@Id//表明当前字段是一个主键
@Column(name="cust_id")//表明对应的数据库的主键字段是cus_id
@GeneratedValue(strategy=GenerationType.SEQUENCE)//请指定主键生成策略.strategy:使用JPA提供的主键生成策略,此属性用不了。generator:可以使用hibernate中的主键生成策略
private Long cusId;
@Column(name="cust_name")
private String cusName;
@Column(name="cust_source")
private String cusSource;
@Column(name="cust_industry")
private String cusIndustry;
@Column(name="cust_level")
private String cusLevel;
@Column(name="cust_address")
private String cusAddress;
@Column(name="cust_phone")
private String cusPhone;
//一对的哟关系映射:一个客户可以有多个联系人
@OneToMany(targetEntity=LinkMan.class,mappedBy="customer")//mappedBy是映射来自,相当于inverse,即主表不在关心从表的信息,让联系人去维护
private Set
2. JPA实现一对多插入操作
JPA操作值插入了两条记录,而不会有update语句, 因为在主表中已经mappedBy="customer",放弃维护了
/**
* 保存操作
* 创建一个客户和一个联系人
* 建立客户和联系人之间的关系
* 先保存客户,再保存联系人
*/
@Test
publicvoid test1(){
Customer c=new Customer();
LinkMan l=new LinkMan();
c.setCusName("JPA One To ManyCustomer");
l.setLkmName("JPA Many To OneLinkMan");
c.getLinkmans().add(l);
l.setCustomer(c);
EntityManager em=JPAUtils.createEntityManager();
EntityTransaction tx=em.getTransaction();
tx.begin();
em.persist(c);
em.persist(l);
tx.commit();
em.close();
}
3. JPA的更新操作
此时必须要配置级联操作:想级联操作谁就应该在谁的上边进行注解配置cascade=CsacadeType.PERSIST属性,即保存或者更新客户的同时保存联系人,
但时cascade=CsacadeType.PERSIST只是级联更新
@OneToMany(targetEntity=LinkMan.class,mappedBy="customer",cascade=CascadeType.PERSIST)//mappedBy是映射来自,相当于inverse,即主表不在关心从表的信息,让联系人去维护
private Set<LinkMan> linkmans=new HashSet<LinkMan>(0);
/**
* 更新操作
* 新建联系人
* 查询ID为186的客户
* 为这个人分配联系人
* 更新客户
*/
@Test
publicvoid test2(){
LinkMan l=new LinkMan();
l.setLkmName("JPA Many To One LinkMan3333");
EntityManager em=JPAUtils.createEntityManager();
EntityTransaction tx=em.getTransaction();
tx.begin();
Customer c=em.find(Customer.class,185L);
c.getLinkmans().add(l);
l.setCustomer(c);
//em.merge(l);//这句可以不写,因为有快照机制,会自己更新的
tx.commit();
em.close();
}
4.JPA的删除操作
1.删除操作
删除主表:若在客户上边配置了放弃维护,即mappedBy="customer",直接删除指标会报错
此时还想要删除的话,需要配置cascade=CascadeType.DELET或者cascade=CascadeType.ALL就可以删除
需要注意的是:联系人那边(从表)也可以配置cascade=CascadeType.ALL这些东西
@Test
publicvoid test3(){
EntityManager em=JPAUtils.createEntityManager();
EntityTransaction tx=em.getTransaction();
tx.begin();
Customer c=em.find(Customer.class,185L);
em.remove(c);
tx.commit();
em.close();
}
JPA的查询操作
JPA中也可以使用对象导航查询,也可以设置查询的时机
延迟加载的特点:真正用到该对象的时候才开始查询改对象的属性
1.如果是立即加载,需要在Customer的set集合的注解中加入下边的语句:fetch=FetchType.EAGER,其原理是利用了左外连接查询的方式实现了立即加载。没写是EAGER,即默认是EAGER。LinkMan中也可是设置成立即加载。
@OneToMany(targetEntity=LinkMan.class,mappedBy="customer",cascade=CascadeType.ALL,fetch=FetchType.EAGER)//mappedBy是映射来自,相当于inverse,即主表不在关心从表的信息,让联系人去维护
private Set
下边的查询可以设置成立即加载,也可以设置成延迟加载
/**
* 根据客车讯客户下边的联系人
*/
@Test
publicvoid test1(){
EntityManager em=JPAUtils.createEntityManager();
EntityTransaction tx=em.getTransaction();
tx.begin();
//1.查询ID为1的客户
Customer c=em.find(Customer.class, 1L);
System.out.println(c);
System.out.print(c.getLinkmans());
tx.commit();
em.close();
}
/**
* 根据联系人查询客户
*/
@Test
publicvoid test2(){
EntityManager em=JPAUtils.createEntityManager();
EntityTransaction tx=em.getTransaction();
tx.begin();
//1.查询ID为1的客户
LinkMan l=em.find(LinkMan.class, 1L);
System.out.println(l);
Customer c=l.getCustomer();
System.out.print(c);
tx.commit();
em.close();
}
JPA的多对多
1.在角色实体对象中,如果配置了中间表的表名和在中间表中的列明,则在另外多的一方中只需要配置@ManyToMany(mappedBy="users")//谁写mappedBy谁就不在关心创建中间表了,即让另外一方不在关心创建中间表。
@Entity
@Table(name="jpa_sysrole")
publicclass SysRole implements Serializable {
@Id
@Column(name="role_id")
@GenericGenerator(name="aa",strategy="uuid")//声明一个主键生成策略的生成器name:给生成器起名字;strategy:指定Hibernate中包含的主键生成策略
@GeneratedValue(generator="aa")
private Long roleId;
@Column(name="role_name")
private String roleName;
@Column(name="role_memo")
private String roleMemo;
//多对多关系映射,一个角色可以赋给多个用户
@JoinTable(name="jpa_user_role",joinColumns={@JoinColumn(name="role_id",referencedColumnName="role_id")},//joinColumns写的是当前实体在中间表中的晚间字段
inverseJoinColumns={@JoinColumn(name="user_id",referencedColumnName="user_id")}//inverseJoinColumns写的是对方实体在中间表中的晚间字段
)
private Set
其中黄色标出的是多对多的关系中特殊的配置,需要注意。
SysUser的主要配置如下,即一方不再关心中间表的创建的事情,只交给一个多方去管。
@ManyToMany(mappedBy="users")//谁写mappedBy谁就不在关心创建中间表了
private Set
2.多对多的操作
/**
* JPA的多对多操作
* 保存操作
* 删除操作
*/
publicclass JPADemo1 {
/**
* 保存操作
* 常见两个用户
* 创建三个角色
* 让一号用户具有1,2号角色
* 让2号用户具备2,3号角色
* 保存用户和角色
*/
@Test
publicvoid test1(){
SysUser u1=new SysUser();
u1.setUserName("JPA Many To ManyUser1");
SysUser u2=new SysUser();
u2.setUserName("JPA Many To ManyUser2");
SysRole r1=new SysRole();
r1.setRoleName("JPA Many To ManyRole1");
SysRole r2=new SysRole();
r2.setRoleName("JPA Many To ManyRole2");
SysRole r3=new SysRole();
r3.setRoleName("JPA Many To ManyRole3");
//建立用户角色之间的关系
u1.getRoles().add(r1);
u1.getRoles().add(r2);
u2.getRoles().add(r2);
u2.getRoles().add(r3);
r1.getUsers().add(u1);
r2.getUsers().add(u1);
r2.getUsers().add(u2);
r3.getUsers().add(u2);
EntityManager em=JPAUtils.createEntityManager();
EntityTransaction tx=em.getTransaction();
tx.begin();
//保存操作
em.persist(u1);
/*em.persist(u2);//如果设置了级联保存,则只需保存一个,其他的与它级联的都会自动保存
em.persist(r1);
em.persist(r2);
em.persist(r3);*/
tx.commit();
em.close();
}
/**
* 删除操作
* 不管是Hibernate中还是JPA中,多对多都不能这样配置,这样会把所有的数据都删干净的
*/
@Test
publicvoid test2(){
EntityManager em=JPAUtils.createEntityManager();
EntityTransaction tx=em.getTransaction();
tx.begin();
//删除操作
SysUser s=em.find(SysUser.class,"asdfasdfasdfasd");//因为此时用的是UUID,必须要写清楚具体的那个用户ID,而不能写出第几个
tx.commit();
em.close();
}
注意:多对多的级联保存配置如下(需要在每一个实体类中配置),下边只写了一个实体类总的cascade的配置,另外的多表的cascade配置都应改如此
@ManyToMany(cascade=CascadeType.ALL)//多对多关系映射,一个角色可以赋给多个用户
//多对多关系映射,一个角色可以赋给多个用户
@JoinTable(name="jpa_user_role",joinColumns={@JoinColumn(name="role_id",referencedColumnName="role_id")},//joinColumns写的是当前实体在中间表中的晚间字段
inverseJoinColumns={@JoinColumn(name="user_id",referencedColumnName="user_id")})//inverseJoinColumns写的是对方实体在中间表中的晚间字段
private Set
3.JPA中的c3p0操作
@Test
publicvoid test1(){
//1.获取JPA中的操作对象
EntityManager em=JPAUtils.createEntityManager();
//2.将em转换成session
Session session=em.unwrap(Session.class);
//验证c3p0连接池是否配置成功
//3.执行session的doWork()方法
session.doWork(new Work(){
@Override
publicvoid execute(Connection conn) throws SQLException {
System.out.println(conn.getClass().getName());
}
});
}
但是要导入c3p0的JAR包,而且要在配置文件里面协商c3p0的供应商:
<property name="hibernate.connection.provider_class"
value="org.hibernate.connection.C3P0ConnectionProvider"/>
如果要从JPA中得到Session对象的话,需要对EntityManager进行unwrap()操作(解包装),就可以得到Session对象,而且用doWork()方法可以得到Connection对象,可以对它进行操作。
4. JPA中使用单线程
自己手写单线程代码,想要使用JPA自己的,需要配置Spring使用。
下边是写出单线程的代码:
publicclass JPAUtils {
//相当于SessionFactory
privatestatic EntityManagerFactory factory;
static {
factory=Persistence.createEntityManagerFactory("myJPAUnit");
tl=new ThreadLocal
}
//获取JPA操作数据库的对象
/*public static EntityManager createEntityManager(){
returnfactory.createEntityManager();//此时不是单线程的EntityManager
}*/
publicstaticvoid main(String[] args) {
createEntityManager();
}
//自己写代码让始终有一个EntityManager
privatestatic ThreadLocal
static{
factory=Persistence.createEntityManagerFactory("myJPAUnit");
tl=new ThreadLocal
}
publicstatic EntityManager createEntityManager(){
//1.从当前线程上获取EntityManager对象
EntityManager em=tl.get();
if(tl==null){
em=factory.createEntityManager();
tl.set(em);
}
returntl.get() ; //此时是单线程的EntityManager
}
}
下边是测试单线程的代码:
@Test
publicvoid test2(){
EntityManager em1=JPAUtils.createEntityManager();
EntityManager em2=JPAUtils.createEntityManager();
System.out.println(em1==em2);
}
其测试结果为true。说明是一个线程。
Hibernate总结
Hibernate的JPA配置了的话也可以用Hibernate的方式来增删改查