BP 神经网络算法识别MNIST数据集
BP 神经网络算法识别MNIST手写数字数据集
人工神经网络的基本原理
生物神经元在结构上由:
- 细胞体(Cell body)
- 树突(Dendrite)
- 轴突(Axon)
- 突触(Synapse)
四部分组成。用来完成神经元间信息的接收、传递和处理。
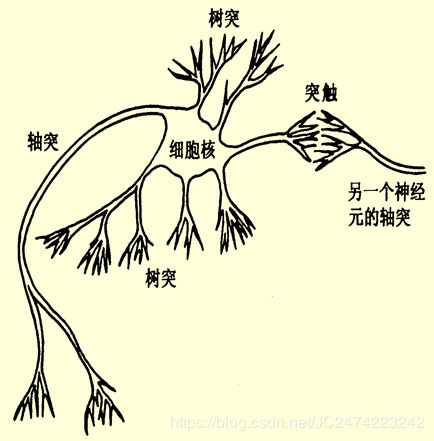
神经元及其突触是神经网络的基本器件。因此,模拟生物神经网络应首先模拟生物神经元, 人工神经元(节点)从三个方面进行模拟:
- 节点本身的信息处理能力
- 节点与节点之间连接(拓扑结构)
- 相互连接的强度(通过学习来调整)
神经元模型
一般地,将形式神经元模型表示为下图所示的一个具有多输入-单输出的非线性阈值器件。

x 1 , x 2 , … , x n x_1, x_2, \dots, x_n x1,x2,…,xn表示某一神经元的第n个输入; W i j W_{ij} Wij表示第 i i i个神经元与第 j j j个神经元的突触连接强度,其称为权值。神经元模型将这些输入加权后经激励函数 f f f输出。
A j = ∑ j = 1 n x i W i j − Θ j A_j = \sum_{j=1}^nx_iW_{ij} - \Theta_j Aj=j=1∑nxiWij−Θj
O j = f ( A j ) O_j = f(A_j) Oj=f(Aj)
几个常见的神经元模型
- 阈值型
该类型的神经元具有一个设定的阈值,是一种最简单的神经元,当加权后的输入大于阈值时,输出为1,否则为0。
激励函数一般表示为:
y i = f ( A i ) = { 1 , A i > Θ i 0 , A i ≤ Θ i y_i = f(A_i) = \begin{cases} 1, \quad A_i \gt \Theta_i \\\\ 0, \quad A_i \leq \Theta_i \end{cases} yi=f(Ai)=⎩⎪⎨⎪⎧1,Ai>Θi0,Ai≤Θi
对于阈值型神经元, 其输入权值 W i j W_{ij} Wij可在 ( − 1 , + 1 ) (-1, +1) (−1,+1)区间连续取值。负值表示抑制,正值表示加强。 - 线性饱和型
线性饱和型神经元在一定区间内,输入输出满足线性关系。激励函数为:
y i = f ( A i ) = { 0 , A i < 0 C A i , 0 ≤ A i ≤ A c 1 , A i > A c y_i = f(A_i) = \begin{cases} 0, \quad A_i \lt 0 \\\\ CA_i, \quad 0 \leq A_i \leq A_c \\\\ 1, \quad A_i \gt A_c \end{cases} yi=f(Ai)=⎩⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎧0,Ai<0CAi,0≤Ai≤Ac1,Ai>Ac
C C C为常量 - S(sigmoid)型
S型神经元是一类连续型神经元模型,采用S型函数(sigmoid 函数)。其激励函数为:
y i = f ( A i ) = 1 / ( 1 + e A i ) y_i = f(A_i) = 1/(1+ e^{A_i}) yi=f(Ai)=1/(1+eAi)
或
y i = f ( A i ) = 1 / ( 2 ( 1 + t h ( A i / A 0 ) ) ) y_i = f(A_i) = 1/(2(1+ th(A_i/A_0))) yi=f(Ai)=1/(2(1+th(Ai/A0))) - 子阈累积型
这类神经元的激活函数也是一个非线性的。当所产生的激活值超过 T T T值时,该神经元将被激活。在线性范围内,系统反响是线性的。子阈的一个作用是抑制噪声,即对小的随机输入不产生响应。 - 概率型
其输出状态的0或1将根据激活函数的大小按照一定的概率来确定。
假定神经元为1的概率为:
P ( S i = 1 ) = 1 / ( 1 + e A i T ) P(S_i = 1) = 1 / (1 + e^{\frac{A_i}{T}}) P(Si=1)=1/(1+eTAi)
则,状态为0的概率为:
P ( S i = 0 ) = 1 − P ( S i = 1 ) P(S_i = 0) = 1 - P(S_i = 1) P(Si=0)=1−P(Si=1)
玻尔兹曼神经元就是这一类神经元。
多层前向神经网络及BP学习算法
单层前向神经网络的缺点是只能解决线性可分的分类问题,要增强网络的分类能力唯一的方法是采用多层网络。也就是在输入层和输出层之间加入隐层,这就构成了多层感知机。
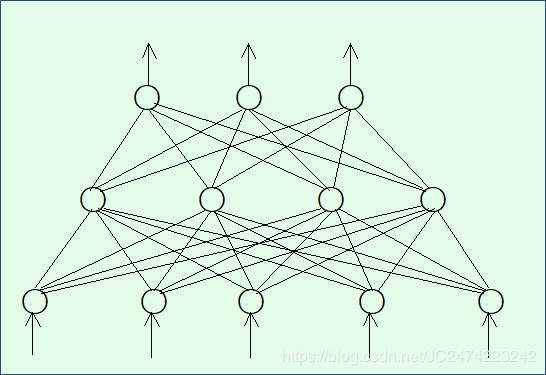
BP学习算法
在BP学习算法中:
- 工作信号正向传播;
- 误差信号反向传播。
BP算法的具体步骤如下(三层的BP学习算法):
- 设置变量和参量:
- 输入数据将被作为一个 n n n维的输入向量 x k = [ x k 1 , x k 2 , … , x k N ] ( k = 1 , 2 , … , N ) x_k = [x_{k1}, x_{k2}, \dots, x_{kN}] \quad (k = 1, 2, \dots, N) xk=[xk1,xk2,…,xkN](k=1,2,…,N)或称训练样本; N N N为训练样本的个数。设:
W I H ( n ) = [ w 11 ( n ) w 12 ( n ) … w 1 H ( n ) w 21 ( n ) w 22 ( n ) … w 2 H ( n ) ⋮ ⋮ ⋱ ⋮ w I 1 ( n ) w I 2 ( n ) … w I H ( n ) ] W_{IH}(n) = \begin{bmatrix} w_{11}(n) & w_{12}(n) & \ldots & w_{1H}(n) \\\\ w_{21}(n) & w_{22}(n) & \ldots & w_{2H}(n) \\\\ \vdots & \vdots & \ddots & \vdots \\\\ w_{I1}(n) & w_{I2}(n) & \ldots & w_{IH}(n) \end{bmatrix} WIH(n)=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡w11(n)w21(n)⋮wI1(n)w12(n)w22(n)⋮wI2(n)……⋱…w1H(n)w2H(n)⋮wIH(n)⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤
为第 n n n次迭代时,输入层和隐层之间的权值矩阵。
W H O ( n ) = [ w 11 ( n ) w 12 ( n ) … w 1 O ( n ) w 21 ( n ) w 22 ( n ) … w 2 O ( n ) ⋮ ⋮ ⋱ ⋮ w H 1 ( n ) w H 2 ( n ) … w H O ( n ) ] W_{HO}(n) = \begin{bmatrix} w_{11}(n) & w_{12}(n) & \ldots & w_{1O}(n) \\\\ w_{21}(n) & w_{22}(n) & \ldots & w_{2O}(n) \\\\ \vdots & \vdots & \ddots & \vdots \\\\ w_{H1}(n) & w_{H2}(n) & \ldots & w_{HO}(n) \end{bmatrix} WHO(n)=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡w11(n)w21(n)⋮wH1(n)w12(n)w22(n)⋮wH2(n)……⋱…w1O(n)w2O(n)⋮wHO(n)⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤
为第 n n n次迭代时,隐层和输出层之间的权值矩阵。 - Y k ( n ) = [ y k 1 ( n ) , y k 2 ( n ) , … , y k N ( n ) ] ( k = 1 , 2 , … , N ) Y_k(n) = [y_{k1}(n), y_{k2}(n), \dots ,y_{kN}(n)] \quad (k = 1, 2, \dots, N) Yk(n)=[yk1(n),yk2(n),…,ykN(n)](k=1,2,…,N)为第 n n n次迭代时网络的实际输出
- d k ( n ) = [ d k 1 ( n ) , d k 2 ( n ) , … , d k N ( n ) ] ( k = 1 , 2 , … , N ) d_k(n) = [d_{k1}(n), d_{k2}(n), \dots ,d_{kN}(n)] \quad (k = 1, 2, \dots, N) dk(n)=[dk1(n),dk2(n),…,dkN(n)](k=1,2,…,N)为第 n n n次迭代时网络的期望输出。由于在本次实验中使用的是S型神经元,其特性不能达到渐进值 + α +\alpha +α 和 − α -\alpha −α, 故期望输出应当取接近渐进值的值,而不是取 + α +\alpha +α 和 − α -\alpha −α。
- η \eta η 为学习效率, n n n为迭代次数。
- 输入数据将被作为一个 n n n维的输入向量 x k = [ x k 1 , x k 2 , … , x k N ] ( k = 1 , 2 , … , N ) x_k = [x_{k1}, x_{k2}, \dots, x_{kN}] \quad (k = 1, 2, \dots, N) xk=[xk1,xk2,…,xkN](k=1,2,…,N)或称训练样本; N N N为训练样本的个数。设:
- 初始化,赋给 W I H ( 0 ) , W H O ( 0 ) W_{IH}(0), W_{HO}(0) WIH(0),WHO(0)各一个较小的随机非零值,建议初始值分布在区间 ( − 2.4 / F , 2.4 / F ) (-2.4/F, 2.4/F) (−2.4/F,2.4/F)或 ( − 3 / F , 3 / F ) (-3/\sqrt{F}, 3/\sqrt{F}) (−3/F,3/F)之间。 F F F为所连单元的输入端个数。
- 输入随机样本 x k x_k xk,并置 n = 0 n=0 n=0
- 对输入样本 x k x_k xk,前向计算BP神经网络每层的输入信号 u u u 和输出信号 v v v。其中
v o O ( n ) = y k o ( n ) o = 1 , 2 , … , O v_o^O(n) = y_{ko}(n) \quad o = 1, 2 , \dots, O voO(n)=yko(n)o=1,2,…,O - 由期望输出 d k d_k dk和上一步求得的实际输出 Y k ( n ) Y_k(n) Yk(n)计算误差 E ( n ) E(n) E(n)判断其是否满足要求,如满足要求转至第8步。
- 判断 n + 1 n+1 n+1是否大于最大迭代次数,若大于转至第8步,否则对输入样本 x k x_k xk反向计算每层神经元的局部梯度 δ \delta δ。其中:
δ o O ( n ) = y o ( n ) ( 1 − y o ( n ) ) ( d o ( n ) − y o ( n ) ) o = 1 , 2 , … , O \delta_o^O(n) = y_o(n)(1-y_o(n))(d_o(n) - y_o(n)) \quad o= 1, 2, \dots, O δoO(n)=yo(n)(1−yo(n))(do(n)−yo(n))o=1,2,…,O
δ h H ( n ) = f ′ ( u h H ( n ) ) ∑ h = 1 H δ o O ( n ) w h o ( n ) h = 1 , 2 , … , H \delta_h^H(n) = f'(u_h^H(n))\sum_{h=1}^H\delta_o^O(n)w_{ho}(n) \quad h= 1, 2, \dots, H δhH(n)=f′(uhH(n))h=1∑HδoO(n)who(n)h=1,2,…,H - 按下式计算权值修正值 Δ w \Delta w Δw,并修正权值; n = n + 1 n = n + 1 n=n+1, 转至第4步:
Δ w h o ( n ) = η δ o O ( n ) v h H w h o ( n + 1 ) = w h o ( n ) + Δ w h o ( n ) \Delta w_{ho}(n) = \eta\delta_o^O(n)v_h^H \quad w_{ho}(n+1) = w_{ho}(n) + \Delta w_{ho}(n) Δwho(n)=ηδoO(n)vhHwho(n+1)=who(n)+Δwho(n)
Δ w i h ( n ) = η δ h H ( n ) v i I w i h ( n + 1 ) = w i h ( n ) + Δ w i h ( n ) \Delta w_{ih}(n) = \eta\delta_h^H(n)v_i^I \quad w_{ih}(n+1) = w_{ih}(n) + \Delta w_{ih}(n) Δwih(n)=ηδhH(n)viIwih(n+1)=wih(n)+Δwih(n) - 判断是否学完所有的训练样本,若是则结束,否则转回第3步。
注:
对于一个训练周期训练多个样本的的训练模式,修正值的计算函数方法如下:
E a v = 1 N ∑ k = 1 N E k = 1 2 N ∑ k = 1 N ∑ p = 1 P e k p 2 E_{av} = \frac{1}{N}\sum_{k=1}^NE_k = \frac{1}{2N}\sum_{k=1}^N\sum_{p=1}^Pe_{kp}^2 Eav=N1k=1∑NEk=2N1k=1∑Np=1∑Pekp2
其中, e k p 2 e_{kp}^2 ekp2为网络输入第 k k k个训练样本时输出神经元 p p p的误差。
学习步长 η \eta η值的选取比较重要, η \eta η值过大会引起网络震荡,过小则会导致收敛速度太慢
隐层个数的选取有两种:
- 大于 log 2 F \log_2 F log2F, F F F为该层的输入节点个数
- I + O + a \sqrt{I+O} + a I+O+a 其中, a a a为一个 1 − 10 1-10 1−10的修正值, I , O I, O I,O分别为输入层和输出层的节点个数
BP学习算法并不完善,它主要存在一下缺陷:学习收敛速度太慢,网络的学习记忆具有不稳定性。
python实现
class BPNet:
def train(self):
labels = []
with open(train_labels_idx1_ubyte_file, "rb") as file:
magicNumber, labelsSize = struct.unpack('>ii', file.read(8))
if magicNumber == 2049:
print("label")
else :
print("Can't recognized")
return 0
labels = file.read()
with open(train_images_idx3_ubyte_file, "rb") as file:
magicNumber, numOfImages, rowsNum, columnsNum = struct.unpack('>iiii', file.read(16))
if magicNumber == 2051:
print("image")
else :
print("Can't recognized")
return 0
# 神经元节点
# 输入层, 隐层, 输出层
inputLayerNodeNum, hideLayerNodeNum, outputLayerNodeNum = rowsNum * columnsNum, 120, 10
# 权值
self.weightIH, self.weightHO = [[] for i in range(inputLayerNodeNum)], [[] for i in range(hideLayerNodeNum)]
self.weightGenerator(self.weightIH, inputLayerNodeNum, hideLayerNodeNum)
self.weightIH = np.array(self.weightIH)
self.weightGenerator(self.weightHO, hideLayerNodeNum, outputLayerNodeNum)
self.weightHO = np.array(self.weightHO)
count, formatStr, yita = 0, '>' + str(inputLayerNodeNum) + 'B', 0.1
while count < numOfImages:
pixes = np.array([struct.unpack(formatStr, file.read(inputLayerNodeNum))])
Ioutput = 1 / (1 + np.exp(-1 * pixes))
Houtput = self.f(Ioutput, self.weightIH)
Ooutput = self.f(Houtput, self.weightHO)
EO = Ooutput * (1 - Ooutput) * (self.d(labels[count]) - Ooutput)
EH = Houtput * (1 - Houtput) * (self.weightHO @ EO.T).T
self.weightHO = self.weightHO + yita * Houtput.T @ EO
self.weightIH = self.weightIH + yita * Ioutput.T @ EH
count = count + 1
if np.mod(count, 1000) == 0:
print("已训练 " + str(count) + " 张图片")
self.test()