SQL学习之-2.5 基本的SQL知识
03:Parch & Posey 数据库
实体关系图
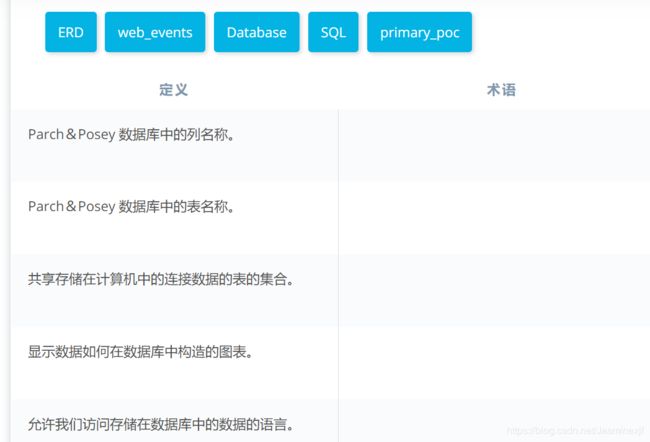
实体关系图 (ERD) 是查看数据库中数据的常用方式。下面是我们将用于 Parch & Posey 数据库的 ERD。这些图可帮助你可视化正在分析的数据,包括:
- 表的名称。
- 每个表中的列。
- 表配合工作的方式。
你可以将下面的每个框看作一个电子表格。

注意事项
在 Parch & Posey 数据库中,共有五个表(基本上是 5 个电子表格):
- web_events
- accounts
- orders
- sales_reps
- region
你可以将每个表视为一个单独的电子表格。然后将每个电子表格中的列放在表名下面。例如,region 表有两列: id 和 name,而 web_events 表有四列。

将这些表格连接在一起的 "crow's foot" 表示法显示了一个表中的列与另一个表中的列之间的关联。在第一课中,你将学习使用 SQL 与单个表进行交互的基础知识。在下一节课中,你将进一步了解这些连接对于使用 SQL 和关系数据库的重要性。
04 练习
05 接下来三节课的内容安排

08 数据库类型

14 查询格式的写法:
大写
你可能已经注意到,我们大写了 SELECT 和 FROM,而将表和列名称小写。这是一个常见的格式惯例。大写命令(SELECT、FROM),小写查询中的其他内容是常见做法。这使得查询更容易读取,这在编写更复杂的查询时更为重要。准备编写查询时,这是一个很好的习惯。
表和变量名中不需要空格
通常在列名中使用下划线,避免使用空格。 在 SQL 中使用空格有点麻烦。 在 Postgres 中,如果列或表名称中有空格,就需要使用双引号括住这些列/表名称(例如:FROM \"Table Name\",而不是 FROM table_name)。在其他环境中,可能会使用方括号(例如:FROM [Table Name])。
在查询中使用空格
SQL 查询忽略空格,因此可以根据需要在代码之间添加尽可能多的空格和空行,并且查询结果是相同的。我们来看下面这个查询
SELECT account_id FROM orders
等价于这个查询:
SELECT account_id
FROM orders
和这个查询(但是不要这样写,不符合规范,而且太丑了):
SELECT account_id
FROM orders
SQL 不区分大小写
如果你已经使用过其他语言编程,那么可能会熟悉编程语言,如果没有区分大小写键入正确的字符,那么会非常麻烦。 SQL 不区分大小写。 我们来看看下面的查询:
SELECT account_id
FROM orders
和这个相同:
select account_id
from orders
也和这个相同:
SeLeCt AcCoUnt_id
FrOm oRdErS
但是,我会再次提醒你遵循上面讲述的完全大写命令的惯例,而将其他代码片段小写。
分号
根据 SQL 环境,查询结尾可能需要一个执行的分号。 这个"要求"在其他环境中比较灵活。我们认为在每个语句的末尾添加一个分号是最好的做法,如果环境能够一次显示多个结果,那么这样做还可以一次运行多个命令。
最好的做法:
SELECT account_id
FROM orders;
因为,我们这里的环境不需要分号,你会看到没有分号的解决方案:
SELECT account_id
FROM orders16 练习LIMIT
#问题 编写一个查询,将响应限制在前 15 行,和包括 web_events 表中的 occurred_at、account_id 和 channel 字段,我们来试一下。
SELECT occurred_at,account_id,channel
FROM web_events
LIMIT 1519 练习ORDER BY partone
# 问题
使用 ORDER BY 进行练习:
编写查询,返回 orders 表的先下单的前 10 个订单。包含 id、occurred_at 和 total_amt_usd。
SELECT id, occurred_at, total_amt_usd
FROM orders
ORDER BY occurred_at
LIMIT 10;
编写一个查询,返回orders 表里 total_amt_usd 最高的5个 订单。包括 id、account_id 和 total_amt_usd。
SELECT id, account_id, total_amt_usd
FROM orders
ORDER BY total_amt_usd DESC
LIMIT 5;
编写一个查询,基于 total ,返回orders 表里的前 20 个 订单。包括 id、account_id 和 total。
SELECT id, account_id, total
FROM orders
ORDER BY total
LIMIT 20;22 练习ORDER BY parttwo
# 问题
查询orders表格,按照订单日期的从新到旧降序排列,同时每个日期下的订单按照total_amt_usd降序排列,显示前5行。
SELECT *
FROM orders
ORDER BY occurred_at DESC, total_amt_usd DESC
LIMIT 5;
查询orders表格,按照订单日期的从旧到新升序排列,同时每个日期下的订单按照total_amt_usd升序排列,显示前10行。
SELECT *
FROM orders
ORDER BY occurred_at, total_amt_usd
LIMIT 10;25 练习 WHERE
# 问题
编写一个查询
从 orders 表提取出gloss_amt_usd大于或等于 1000 美元的前五行数据(包含所有列)。
SELECT *
FROM orders
WHERE gloss_amt_usd >= 1000
LIMIT 5;
从 orders 表提取出total_amt_usd小于 500 美元的前十行数据(包含所有列)。
SELECT *
FROM orders
WHERE total_amt_usd < 500
LIMIT 10;28 练习WHERE
WHERE 与非数字数据一起使用的练习
- 从 accounts 表格中筛选出 Exxon Mobil 的
name(客户名称),同时包含website和primary point of contact(primary_poc) 等数据。SELECT name, website, primary_poc FROM accounts WHERE name = 'Exxon Mobil';31 练习算术运算符
使用 orders表:
创建一个用 standard_amt_usd 除以 standard_qty 的列,查找每个订单中标准纸张的单价。将结果限制到前 10 个订单,并包含 id 和 account_id 字段。
编写一个查询,查找每个订单海报纸的收入百分比。 只需使用以 _usd 结尾的列。 (在这个查询中试一下不使用总列)。包含 id 和 account_id 字段。
注意 1 - 对于这个问题,即使采用正确的解决方案,也会遇到一个问题。这就是除以零。 在后面的课程学习 CASE 语句时,我们会学习不让此查询发生错误的解决方案。
注意 2 - 上述运算符将信息合并在同一行的列中。如果要跨多行组合特定列的值,我们将使用聚合来进行此操作。稍后学习这部分内容。
下面是提供解决方案的查询。 你会注意到,由于除以零,所以出现了一个错误。在这节课结束之前,我们将具体学习 CASE语句,了解关于此错误的原因。一个简单(但不完全准确)的解决方案是将给分母加
1.
SELECT id, account_id, standard_amt_usd/standard_qty AS unit_price
FROM orders
LIMIT 10;
2.
SELECT id, account_id,
poster_amt_usd/(standard_amt_usd + gloss_amt_usd + poster_amt_usd) AS post_per
FROM orders;35 练习LIKE
使用 LIKE 运算符的问题
使用 accounts 表查找
所有以 'C' 开头公司名。
SELECT name
FROM accounts
WHERE name LIKE 'C%';
名称中包含字符串 'one' 的所有公司名。
SELECT name
FROM accounts
WHERE name LIKE '%one%';
所有以 's' 结尾的公司名。
SELECT name
FROM accounts
WHERE name LIKE '%one%';
SELECT name
FROM accounts
WHERE name LIKE '%s';38 练习 IN
使用 IN 运算符的问题
使用 accounts 表返回 Walmart、Target 和 Nordstrom 的name(客户名称), 同时包含primary_poc, 以及sales_rep_id。
SELECT name, primary_poc, sales_rep_id
FROM accounts
WHERE name IN ('Walmart', 'Target', 'Nordstrom');
使用 web_events 表查找所有通过 organic 或 adwords 渠道联系的个人的信息。
SELECT *
FROM web_events
WHERE channel IN ('organic', 'adwords');41 练习 NOT
使用 NOT 运算符的问题
我们可以使用这个新运算符来提取前两个练习中不属于查询内容的所有行。
使用accounts表查找除 Walmart、Target 和 Nordstrom 之外的所有商店的name(客户名称),primary_poc(主要联系人), 以及sales_rep_id(销售代表工号)。
使用 web_events 表查找不是通过 organic 或 adwords 渠道联系到的个人的信息
使用accounts表查找:
所有不以 'C' 开头的公司名。
所有名称中不包含字符串 'one' 的公司名。
所有不以 's' 结尾的公司名。
NOT IN 问题的解决方案
SELECT name, primary_poc, sales_rep_id
FROM accounts
WHERE name NOT IN ('Walmart', 'Target', 'Nordstrom');
SELECT *
FROM web_events
WHERE channel NOT IN ('organic', 'adwords');
NOT LIKE 问题的解决方案
SELECT name
FROM accounts
WHERE name NOT LIKE 'C%';
SELECT name
FROM accounts
WHERE name NOT LIKE '%one%';
SELECT name
FROM accounts
WHERE name NOT LIKE '%s';44 练习AND 与BETWEEN
使用 AND 和 BETWEEN 运算符的问题
编写一个查询,返回所有orders(订单),其中 standard_qty (标准纸数量)超过 1000,poster_qty(海报纸数量) 是 0,gloss_qty (铜板高光纸数量)也是 0。
使用accounts表查找所有不以 'C' 开始但以 's' 结尾的公司名。
使用 web_events 表查找通过 organic 或 adwords 渠道来联系的,并在 2016 年的任何时间开通帐户的个人全部信息,并按照从最新到最旧的顺序排列。
AND 和 BETWEEN 问题的解决方案
SELECT *
FROM orders
WHERE standard_qty > 1000 AND poster_qty = 0 AND gloss_qty = 0;
SELECT name
FROM accounts
WHERE name NOT LIKE 'C%' AND name LIKE '%s';
你可能会觉得对日期数据使用 BETWEEN 不太好理解。对于单纯的日期数据而言(只包含年月日不包含时间的数据,比如 '2016-12-31'),其默认时间为日期当天的 00:00:00(也就是午夜时分),而 BETWEEN 通常是不包含端点在内的,这也是为什么将右边的时间点设置为 '2017-01-01' 的原因。
SELECT *
FROM web_events
WHERE channel IN ('organic', 'adwords') AND occurred_at BETWEEN '2016-01-01' AND '2017-01-01'
ORDER BY occurred_at DESC;47 练习OR
使用 OR 运算符的问题
查找 orders表,其中 gloss_qty(铜版纸数量) 或 poster_qty (海报纸数量)大于 4000。只在结果表中包含 id 字段。
查找 orders表,其中普通纸数量 (standard_qty)为零,铜版纸数量 (gloss_qty) 或海报数量 (poster_qty)超过 1000,返回相关订单的所有信息。
查找 accounts表,返回符合条件的信息:name 以 'C' 或 'W' 开头,主要联系人 (primary contact) 包含 'ana' 或 'Ana',但不包含 'eana'。
OR 问题的解决方案
SELECT id
FROM orders
WHERE gloss_qty > 4000 OR poster_qty > 4000;
SELECT *
FROM orders
WHERE standard_qty = 0 AND (gloss_qty > 1000 OR poster_qty > 1000);
SELECT *
FROM accounts
WHERE (name LIKE 'C%' OR name LIKE 'W%')
AND ((primary_poc LIKE '%ana%' OR primary_poc LIKE '%Ana%')
AND primary_poc NOT LIKE '%eana%');