聪哥哥教你学Python之基础
本章学习建议:
问:请问聪哥哥有什么好的建议?
答:建议初学者最好还是一个例子一个例子的练习,当然了,最好的话,相关的理论也看看,还有就是有相关的编程经验人士,在学习过程中最好联系自己常用的编程语言,对比学习中你会学的更快更顺。
本章主要围绕这么几个方面来讲Python:
1.数据类型与变量
2.字符串和编码
3.使用list与tuple
4.条件判断
5.循环
6.使用dict与set
一、数据类型与变量
Python的数据类型主要有:
1.整数
age=18
print(age)2.浮点
height=1.8
weight=0.5
print(height)
print(weight)3.字符串
name="聪哥哥520"
print(name)4.布尔值
isGoodBoy=1
isBadBoy=2
print(isGoodBoy==isBadBoy)5.空值
空值是Python里一个特殊的值,用None表示。None不能理解为0,因为0是有意义的,而None是一个特殊的空值。
常见错误:
图一

图二

图三
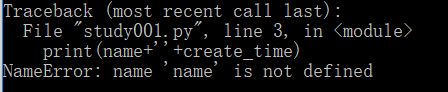
用中文该说,通常是类型错误比较多,当然了,还包括有些时候赋值问题等。
至于变量我不想说太多,因为觉得凡是懂JS,拿它和Python对比就一目了然了。
比如JS的变量除了每次在对应的变量前面加上var之外 实际上与Python这个变量机制并没有什么很大的区别。
另外再补充说一点,一个面试常见考题:
name='zhangsan'Python解释器在此期间干了两件事:
(1)在内存中创建了一个'zhangsan'的字符串;
(2)在内存中创建了一个名为name的变量,并把它指向'zhangsan'。
还有一个常量,常量一般都是大写表示,同Java一样。
二、字符串与编码
字符编码问题在任何一门编程语言都是一件挺头疼的事情。
一般情况为了避免乱码
我们会在对应的python文件最上面声明如下:
# -*- coding: utf-8 -*-再联系到html,绝大多数情况基本上都要在
之间声明如下:还有在jsp文件最上面都会声明一个这样的:
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>它们共同的目的就是为了统一编码为UTF-8。UTF-8是国际通用编码,不管是中文还是英文,还是其他国家语言,同样适用。当然了,国内也不乏有没有用UTF-8,直接编码为gbk,也就是中文的方式。
对字符串常见的操作:
print() 一般就是输出
ord() 将字符转化为数字形式
chr() 将数字转化为字符形式
encode() 指定对应的字符编码格式
len() 获取对应的字符串长度
常见的占位符:

三、使用list与tuple
1.list
Python内置的一种数据类型是列表:list。list是一种有序的集合,可以随时添加和删除其中的元素
(1)对集合遍历和单个获取操作,示例代码如下:
classmate=['A','B','C']
print(classmate)
print(classmate[2])
注意:一般集合索引是从0开始,超过集合对应的索引数是,会报相关的错误,如图所示:

(2)添加集合
list.append('D')
list.insert('4','E')append()方法,默认追加尾部
insert()方法,需要指定对应的索引值,而且该索引值必须是唯一的
另外你再联系下JS,发现也是一样的。
(3)删除集合
list.pop()
list.pop(1)前者和后者的区别是,前者默认会直接删除尾部,后者指定删除。
(4)获取集合长度
len()方法就可以
2.tuple
有序列表叫元组:tuple。tuple和list非常类似,但是tuple一旦初始化就不能修改。
不可变的tuple有什么意义?因为tuple不可变,所以代码更安全。如果可能,能用tuple代替list就尽量用tuple。
tuple所谓的“不变”是说,tuple的每个元素,指向永远不变。即指向'a',就不能改成指向'b',指向一个list,就不能改成指向其他对象,但指向的这个list本身是可变的。
示例代码:
# -*- coding: utf-8 -*-
classmates = ('A', 'B', 'C')
print('classmates =', classmates)
print('len(classmates) =', len(classmates))
print('classmates[0] =', classmates[0])
print('classmates[1] =', classmates[1])
print('classmates[2] =', classmates[2])
print('classmates[-1] =', classmates[-1])
# cannot modify tuple:
classmates[0] = 'N'结果如图:

list和tuple是Python内置的有序集合,一个可变,一个不可变。根据需要来选择使用它们。
四、条件判断
计算机之所以能做很多自动化的任务,因为它可以自己做条件判断。
条件判断倒没有什么好说的,这里需要注意的地方是,手动编写时,如果没有用对应的IDE工具的话,有些时候会因为排版导致的错误
示意代码:
# -*- coding: utf-8 -*-
age = 20
if age >= 6:
print('teenager')
elif age >= 18:
print('adult')
else:
print('kid')五、循环
记得曾经有位计算机老人对我说过,很多年前没有这么多的高级语言应运而生时,记得那个时候大学毕业,处于一个连一台像样的电脑都没有时,他学的是计算机专业,然后毕业了,他去面试,面试官问他会什么,他说他就会for循环。
可见,学习循环还是很重要的。‘
来段for循环代码(啪啪啪):
# -*- coding: utf-8 -*-
names = ['A', 'B', 'C']
for name in names:
print(name)
再来段while循环代码(计算100以内所有奇数之和):
sum = 0
n = 99
while n > 0:
sum = sum + n
n = n - 2
print(sum)
如果要提前结束循环,可以使用break终结:
n = 1
while n <= 100:
if n > 10: # 当n = 11时,条件满足,执行break语句
break # break语句会结束当前循环
print(n)
n = n + 1
print('END')如果只想打印奇数,可以用continue方式跳过:
n = 0
while n < 10:
n = n + 1
if n % 2 == 0: # 如果n是偶数,执行continue语句
continue # continue语句会直接继续下一轮循环,后续的print()语句不会执行
print(n)循环是让计算机做重复任务的有效的方法。
break语句可以在循环过程中直接退出循环,而continue语句可以提前结束本轮循环,并直接开始下一轮循环。这两个语句通常都必须配合if语句使用。
要特别注意,不要滥用break和continue语句。break和continue会造成代码执行逻辑分叉过多,容易出错。大多数循环并不需要用到break和continue语句,上面的两个例子,都可以通过改写循环条件或者修改循环逻辑,去掉break和continue语句。
有些时候,如果代码写得有问题,会让程序陷入“死循环”,也就是永远循环下去。这时可以用Ctrl+C退出程序,或者强制结束Python进程。
六、使用dict和set
1.dict
Python内置了字典:dict的支持,dict全称dictionary,在其他语言中也称为map,使用键-值(key-value)存储,具有极快的查找速度(从这个角度,你可以联系到非关系数据库,非关系数据库又称键值对数据库,从中你就可以明白了为什么非关系型数据库比关系型数据库要快的原因)
以我曾经在学校学习时写的一个博客系统为例:
那个博客系统对应的数据库我是用MySQL,设计了五张表,用户表,文章表,文章类型表,标签表,评论表等。
用户表和文章表关联,文章类型表与用户表也关联,用户表与评论表关联,文章也又与标签关联。说到这,你也许觉得怀疑人生了。
简单的归纳如下:
用户和文章,一对多关系
用户和文章,多对多关系
文章和标签,多对多关系
文章和文章类型,一对多关系
用关系型数据库实现这个虽然不难,但是后续扩展起来还是一件比较麻烦的事情。
但是如果用非关系型数据库,那就一切解决了。
举个例子,Y总和Z总、L总一起考试,考试完后查成绩,代码示例如下:
# -*- coding: utf-8 -*-
d = {'Y总': 95, 'Z总': 90, 'L总': 90.5}
print(d['Y总'])或print(d.get('Z总'))为什么dict查找速度这么快?
因为dict的实现原理和查字典是一样的。假设字典包含了1万个汉字,我们要查某一个字,一个办法是把字典从第一页往后翻,直到找到我们想要的字为止,这种方法就是在list中查找元素的方法,list越大,查找越慢。
请务必注意,dict内部存放的顺序和key放入的顺序是没有关系的。
和list比较,dict有以下几个特点:
- 查找和插入的速度极快,不会随着key的增加而变慢;
- 需要占用大量的内存,内存浪费多。
而list相反:
- 查找和插入的时间随着元素的增加而增加;
- 占用空间小,浪费内存很少。
所以,dict是用空间来换取时间的一种方法。
dict可以用在需要高速查找的很多地方,在Python代码中几乎无处不在,正确使用dict非常重要,需要牢记的第一条就是dict的key必须是不可变对象。
这是因为dict根据key来计算value的存储位置,如果每次计算相同的key得出的结果不同,那dict内部就完全混乱了。这个通过key计算位置的算法称为哈希算法(Hash)。
要保证hash的正确性,作为key的对象就不能变。在Python中,字符串、整数等都是不可变的,因此,可以放心地作为key。而list是可变的,就不能作为key
2.set
set和dict类似,也是一组key的集合,但不存储value。由于key不能重复,所以,在set中,没有重复的key。
要创建一个set,需要提供一个list作为输入集合(注意,Set是不可重复的)
示例代码如下:
# -*- coding: utf-8 -*-
s = set([1, 1, 2, 2, 3, 3])
print(s)输出代码结果如图:
![]()
set如何添加?
s.add() 即可添加 (注意,如果是添加重复的元素,无效,也不会报错)
s.remove() 可指定索引删除
set和dict的唯一区别仅在于没有存储对应的value,但是,set的原理和dict一样,所以,同样不可以放入可变对象,因为无法判断两个可变对象是否相等,也就无法保证set内部“不会有重复元素”。试试把list放入set,看看是否会报错。
使用key-value存储结构的dict在Python中非常有用,选择不可变对象作为key很重要,最常用的key是字符串。