flume-ng命令
flume-ng命令帮助:
[root@hadoop01 apache-flume-1.6.0-bin]# ./bin/flume-ng help
Usage: ./flume-ngcommands:
help display this help textagent run a Flume agent
avro-client run an avro Flume client
version show Flume version info
global options:--conf,-c
--classpath,-C
--dryrun,-d do not actually start Flume, just print the command
--plugins-path
plugins.d section in the user guide for more details.
Default: $FLUME_HOME/plugins.d
-Dproperty=value sets a Java system property value
-Xproperty=value sets a Java -X option
agent options:
--name,-n
--conf-file,-f
--zkConnString,-z
--zkBasePath,-p
--no-reload-conf do not reload config file if changed
--help,-h display help text
avro-client options:
--rpcProps,-P
--host,-H
--port,-p
--dirname
--filename,-F
--headerFile,-R
--help,-h display help text
Either --rpcProps or both --host and --port must be specified.
Note that if
in the classpath.
测试flume操作
测试服务器
ip:192.168.226.151 主机名:hadoop01
ip:192.168.226.152 主机名:hadoop02
ip:192.168.226.153 主机名:hadoop03
source测试
1、netcat source
配置文件:example01.conf
#配置agent a1
a1.sources=r1
a1.channels=c1
a1.sinks=k1
#配置对应的sourcea1.sources.r1.type=netcat
a1.sources.r1.bind=0.0.0.0
a1.sources.r1.port=8888
#配置对应的sinka1.sinks.k1.type=logger
#配置对应的channel
a1.channels.c1.type=memorya1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
#配置绑定关系(一个sink对应一个channel)a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
启动angent命令(hadoop01)

.......

telnet 192.168.226.151 8888

agent端(hadoop01)接收到内容

2、avro source
配置文件:example02.conf
#配置agent a1
a1.sources=r1
a1.channels=c1
a1.sinks=k1
#配置对应的source
a1.sources.r1.type=avro
a1.sources.r1.bind=0.0.0.0
a1.sources.r1.port=8888
#配置对应的sink
a1.sinks.k1.type=logger
#配置对应的channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
#配置绑定关系(一个sink对应一个channel)
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
启动angent命令(hadoop01)

.......

启动avro客户端(hadoop01)

........

angent端接收到log1.txt文件内容

3、exec source
配置文件:example03.conf
#配置agent a1
a1.sources=r1
a1.channels=c1
a1.sinks=k1
#配置对应的source
a1.sources.r1.type=exec
a1.sources.r1.command=ls /usr/soft
#配置对应的sink
a1.sinks.k1.type=logger
#配置对应的channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
#配置绑定关系(一个sink对应一个channel)
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
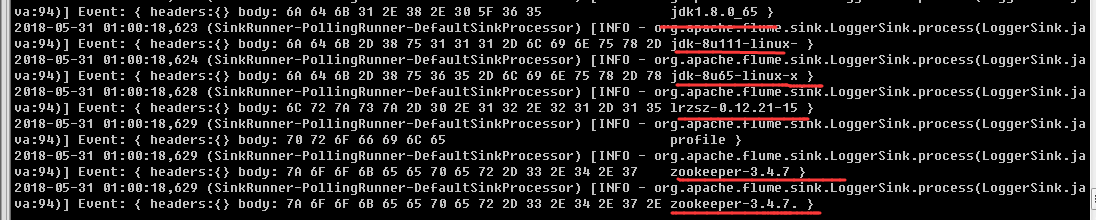
启动angent命令(hadoop01),启动成功后,直接输出exec中执行的命令结果

........
4、Spooling Directory Source
配置文件:example04.conf
#配置agent a1a1.sources=r1
a1.channels=c1
a1.sinks=k1
#配置对应的source
a1.sources.r1.type=spooldir
a1.sources.r1.spoolDir=/usr/soft/apache-flume-1.6.0-bin/mydata
#配置对应的sink
a1.sinks.k1.type=logger
#配置对应的channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
#配置绑定关系(一个sink对应一个channel)
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
启动angent命令(hadoop01)

......

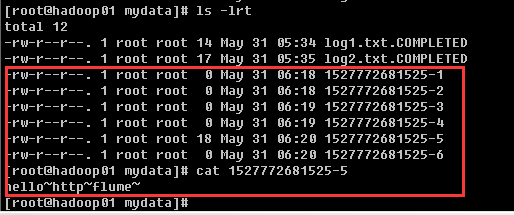
通过另外的连接,在flume目录下的mydata目录,创建log2.txt文件(hadoop01)
angent监听进程自动扫描并处理文件

5、Sequence GeneratorSource
配置文件:example05.conf
#配置agent a1
a1.sources=r1
a1.channels=c1
a1.sinks=k1
#配置对应的source
a1.sources.r1.type=seq
#配置对应的sink
a1.sinks.k1.type=logger
#配置对应的channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
#配置绑定关系(一个sink对应一个channel)
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
启动angent命令(hadoop01),不断的+1输出
[root@hadoop01 conf]# ../bin/flume-ng agent -c ./ -f ./example05.conf -n a1 -Dflume.root.logger=INFO,console
6、 HTTP Source
配置文件:example06.conf
#配置agent a1a1.sources=r1
a1.channels=c1
a1.sinks=k1
#配置对应的source
a1.sources.r1.type=http
a1.sources.r1.port=8888
#配置对应的sink
a1.sinks.k1.type=logger
#配置对应的channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
#配置绑定关系(一个sink对应一个channel)
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
启动angent命令(hadoop01)

.......

从另外的连接,通过命令发送HTTP请求到指定端口(hadoop01)
[root@hadoop01 mydata]# curl -X POST -d '[{ "headers" :{"a" : "a1","b" : "b1"},"body" : "hello~http~flume~"}]' http://0.0.0.0:8888
angent端接收到http请求信息

Sink 测试
1、file roll sink
配置文件:example07.conf
#配置agent a1
a1.sources=r1
a1.channels=c1
a1.sinks=k1
#配置对应的source
a1.sources.r1.type=http
a1.sources.r1.port=8888
#配置对应的sink
a1.sinks.k1.type=file_roll
a1.sinks.k1.sink.directory=/usr/soft/apache-flume-1.6.0-bin/mydata
#配置对应的channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
#配置绑定关系(一个sink对应一个channel)
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
启动angent命令(hadoop01)(与HTTP Source测试启动一样)
从另外的连接,通过命令发送HTTP请求到指定端口(hadoop01)(与HTTP Source测试一样)
查看接收到的信息,保存到指定目录
2、Avro Sink,多级流动
hadoop01(http,avro)->hadoop02(avro,logger)
hadoop01配置文件:example081.conf
#配置agent a1a1.sources=r1
a1.channels=c1
a1.sinks=k1
#配置对应的source
a1.sources.r1.type=http
a1.sources.r1.port=8888
#配置对应的sink
a1.sinks.k1.type=avro
a1.sinks.k1.hostname=hadoop02
a1.sinks.k1.port=9988
#配置对应的channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
#配置绑定关系(一个sink对应一个channel)
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
hadoop02配置文件:example082.conf
#配置agent a1
a1.sources=r1
a1.channels=c1
a1.sinks=k1
#配置对应的source
a1.sources.r1.type=avro
a1.sources.r1.bind=0.0.0.0
a1.sources.r1.port=9988
#配置对应的sink
a1.sinks.k1.type=logger
#配置对应的channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
#配置绑定关系(一个sink对应一个channel)
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
启动顺序,从后向前,
先启动hadoop02 agent

......

再启动hadoop01 agent

......

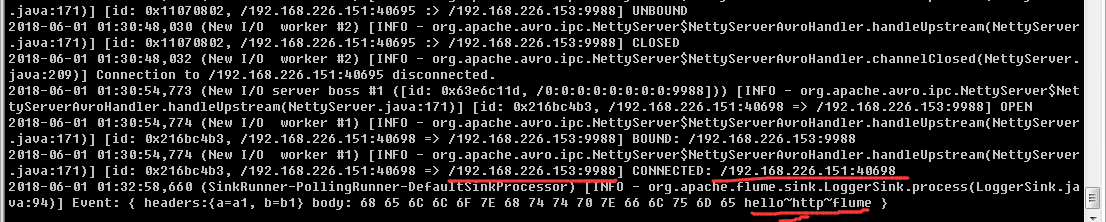
从另外的连接,通过命令发送HTTP请求到指定端口(hadoop01)
[root@hadoop01 mydata]# curl -X POST -d '[{ "headers" :{"a" : "a1","b" : "b1"},"body" : "hello~http~flume~hadoop01~hadoop02"}]' http://0.0.0.0:8888
angent端接收到http请求信息(hadoop02)

3、Avro Sink,扇出流-复制
hadoop01(http,avro)
->hadoop02(avro,logger)
->hadoop03(avro,logger)
hadoop01配置文件:example091.conf
#配置agent a1
a1.sources=r1
a1.channels=c1 c2
a1.sinks=k1 k2
#配置对应的source
a1.sources.r1.type=http
a1.sources.r1.port=8888
#配置对应的sink
a1.sinks.k1.type=avro
a1.sinks.k1.hostname=hadoop02
a1.sinks.k1.port=9988
a1.sinks.k2.type=avro
a1.sinks.k2.hostname=hadoop03
a1.sinks.k2.port=9988
#配置对应的channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.channels.c2.type=memory
a1.channels.c2.capacity=1000
a1.channels.c2.transactionCapacity=100
#配置绑定关系(一个sink对应一个channel)
a1.sources.r1.channels=c1 c2
a1.sinks.k1.channel=c1
a1.sinks.k2.channel=c2
hadoop02配置文件:example092.conf
#配置agent a1
a1.sources=r1
a1.channels=c1
a1.sinks=k1
#配置对应的source
a1.sources.r1.type=avro
a1.sources.r1.bind=0.0.0.0
a1.sources.r1.port=9988
#配置对应的sink
a1.sinks.k1.type=logger
#配置对应的channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
#配置绑定关系(一个sink对应一个channel)
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
hadoop03配置文件:example093.conf
#配置agent a1
a1.sources=r1
a1.channels=c1
a1.sinks=k1
#配置对应的source
a1.sources.r1.type=avro
a1.sources.r1.bind=0.0.0.0
a1.sources.r1.port=9988
#配置对应的sink
a1.sinks.k1.type=logger
#配置对应的channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
#配置绑定关系(一个sink对应一个channel)
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
启动顺序,从后向前,
先启动hadoop02 agent、hadoop03 agent(与arvo多级流动类似)
再启动hadoop01 agent

......

从另外的连接,通过命令发送HTTP请求到指定端口(hadoop01)
[root@hadoop01 mydata]# curl -X POST -d '[{ "headers" :{"a" : "a1","b" : "b1"},"body" : "hello~http~flume"}]' http://0.0.0.0:8888
angent端接收到http请求信息(hadoop02、hadoop03)

4、Avro Sink,扇出流-多路复用(路由)
hadoop01(http,avro)
->hadoop02(avro,logger)—— c1
->hadoop03(avro,logger)—— c2
hadoop01配置文件:example0101.conf
#配置agent a1
a1.sources=r1
a1.channels=c1 c2
a1.sinks=k1 k2
#配置对应的source
a1.sources.r1.type=http
a1.sources.r1.port=8888
a1.sources.r1.selector.type=multiplexing
a1.sources.r1.selector.header=gender
a1.sources.r1.selector.mapping.male=c1
a1.sources.r1.selector.mapping.female=c2
a1.sources.r1.selector.default=c1
#配置对应的sink
a1.sinks.k1.type=avro
a1.sinks.k1.hostname=hadoop02
a1.sinks.k1.port=9988
a1.sinks.k2.type=avro
a1.sinks.k2.hostname=hadoop03
a1.sinks.k2.port=9988
#配置对应的channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.channels.c2.type=memory
a1.channels.c2.capacity=1000
a1.channels.c2.transactionCapacity=100
#配置绑定关系(一个sink对应一个channel)
a1.sources.r1.channels=c1 c2
a1.sinks.k1.channel=c1
a1.sinks.k2.channel=c2
hadoop02配置文件:example0102.conf(与example092.conf一样)
hadoop03配置文件:example0103.conf(与example093.conf一样)
启动顺序,从后向前,
先启动hadoop02 agent、hadoop03 agent(与arvo sink 扇出流-复制,一样)
再启动hadoop01 agent(与arvo sink 扇出流-复制,一样)
从另外的连接,通过命令发送HTTP请求到指定端口(hadoop01)
[root@hadoop01 mydata]# curl -X POST -d '[{ "headers" :{"gender" : "male","name" : "jay"},"body" : "hello~jay"}]' http://0.0.0.0:8888
angent端接收到http请求信息(hadoop02)

[root@hadoop01 mydata]# curl -X POST -d '[{ "headers" :{"gender" : "female","name" : "shirly"},"body" : "hello~shirly"}]' http://0.0.0.0:8888
angent端接收到http请求信息(hadoop03)

[root@hadoop01 mydata]# curl -X POST -d '[{ "headers" :{"gender" : "ladyboy","name" : "haha"},"body" : "hello~haha"}]' http://0.0.0.0:8888
angent端接收到http请求信息(hadoop02)

5、Avro Sink,扇入流
hadoop02(http,avro)->hadoop01(avro,logger)
hadoop03(http,avro)->hadoop01(avro,logger)
hadoop01配置文件:example0111.conf
#配置agent a1
a1.sources=r1
a1.channels=c1
a1.sinks=k1
#配置对应的source
a1.sources.r1.type=avro
a1.sources.r1.bind=0.0.0.0
a1.sources.r1.port=9988
#配置对应的sink
a1.sinks.k1.type=logger
#配置对应的channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
#配置绑定关系(一个sink对应一个channel)
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
hadoop02配置文件:example0112.conf
#配置agent a1
a1.sources=r1
a1.channels=c1
a1.sinks=k1
#配置对应的source
a1.sources.r1.type=http
a1.sources.r1.port=8888
#配置对应的sink
a1.sinks.k1.type=avro
a1.sinks.k1.hostname=hadoop01
a1.sinks.k1.port=9988
#配置对应的channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
#配置绑定关系(一个sink对应一个channel)
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
hadoop03配置文件:example0113.conf
a1.sources=r1
a1.channels=c1
a1.sinks=k1
#配置对应的source
a1.sources.r1.type=http
a1.sources.r1.port=8888
#配置对应的sink
a1.sinks.k1.type=avro
a1.sinks.k1.hostname=hadoop01
a1.sinks.k1.port=9988
#配置对应的channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
#配置绑定关系(一个sink对应一个channel)
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
启动顺序,从后向前,
先启动hadoop01 agent

......

再启动hadoop02 agent、hadoop03 agent


启动hadoop02,hadoop03agent后,hadoop01接收到连接信息
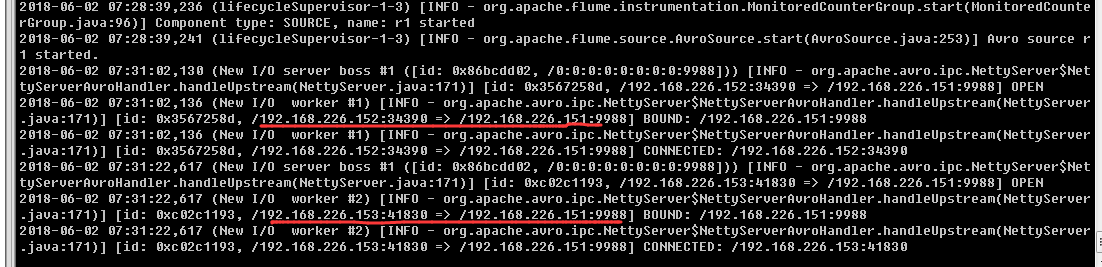
从另外的连接,通过命令发送HTTP请求到指定端口(hadoop02)
[root@hadoop02 ~]# curl -X POST -d '[{ "headers" :{"gender" : "male","name" : "jay"},"body" : "hello~jay"}]' http://0.0.0.0:8888
从另外的连接,通过命令发送HTTP请求到指定端口(hadoop03)
[root@hadoop03 ~]# curl -X POST -d '[{ "headers" :{"gender" : "female","name" : "shirly"},"body" : "hello~shirly"}]' http://0.0.0.0:8888
hadoop01angent端接收到(hadoop02、hadoop03)http请求信息

6、hdfs Sink
hadoop01配置文件:example012.conf
#配置agent a1
a1.sources=r1
a1.channels=c1
a1.sinks=k1
#配置对应的source
a1.sources.r1.type=http
a1.sources.r1.port=8888
#配置对应的sink
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path=hdfs://0.0.0.0:9000/flume
#配置对应的channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
#配置绑定关系(一个sink对应一个channel)
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
启动hadoop01 agent

......

从另外的连接,通过命令发送HTTP请求到指定端口(hadoop01)
[root@hadoop01 ~]# curl -X POST -d '[{ "headers" :{"gender" : "male","name" : "jay"},"body" : "hello~jay"}]' http://0.0.0.0:8888
hadoop01agent接收到http请求信息
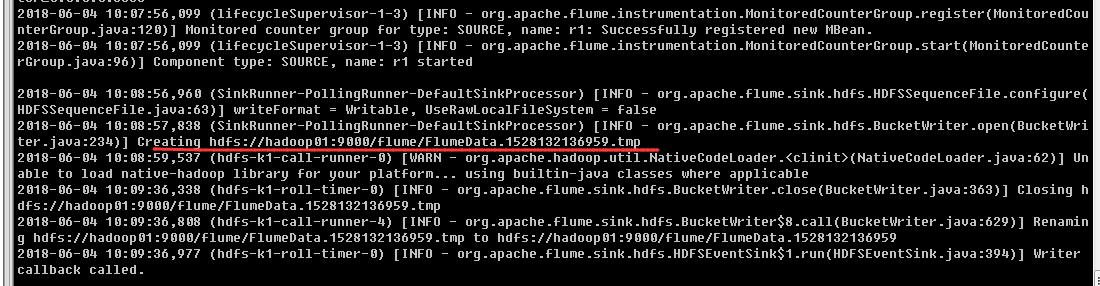
查看hdfs上保存的文件信息
