坐标KNN聚类python实例
最近爬取搜房网上海新房的2000个小区和行政区,对其小区爬了坐标,去掉一些可见的异常点,结果分布如下,需要原数据的在这,可能会有噪声,只是自己拿来做做实验而已。链接:http://pan.baidu.com/s/1dFOiG5F 密码:cty5

首先尝试了一下K均值,结果如下
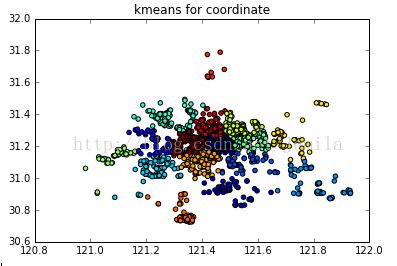
在这里K均值的缺点就暴露了,因为是无监督学习,所以仅仅依靠统计距离计算的准确率是不高的。
具体说来,K均值先通过人工选择K个样本作为K个初始均值向量,但是一般的操作是随机选择一些点作为初始聚类中心,而这些聚类中心需要尽可能的远。这便是Kmeans++。计算其他向量与K这个初始向量的距离,考察一遍之后再更新均值向量,迭代直到稳定。因此需要事先人工选择样本和中心个数,意味着需要一定的先验知识。同时K均值又对噪声和样本量比较敏感,比如上面两个图中最上面的样本和右上的样本其实是属于崇明区的,然而由于中间样本缺失,导致左右两头划分到不同的聚类中心去了。
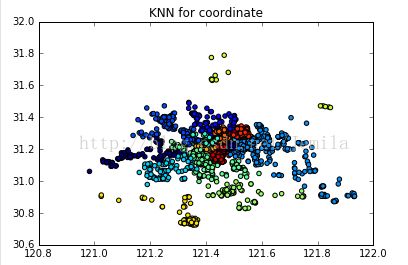
使用了Kmeans无监督之后,接下来用有监督的KNN方法试试。
import pandas as pd
import numpy as np
from sklearn.cross_validation import train_test_split
from sklearn import neighbors #导入K-means算法包
new_dff = pd.read_excel(u'C:/Users/user/Desktop/zuobiao.xlsx')
#将dataframe转为向量
x=pd.concat([new_dff['XLongitude'],new_dff['YLatitude']],axis=1)
X=x.astype('float')
X=X.as_matrix()
y=new_dff["District"]
print y.shape
Y=y.astype('int')
Y=np.array(Y)
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size = 0.2)
clf = neighbors.KNeighborsClassifier(algorithm='kd_tree')
clf.fit(x_train, y_train)
from sklearn import metrics#准确度
y_pred = clf.predict(x_test)
scores =[]
scores.append(metrics.accuracy_score(y_pred, y_test))
print scores
然后计算了训练集和测试集的准确度为0.93702和0.89779,默认参数n_neighbors=5.整个过程其实是这样的,训练集和测试集的比例为8:2.抽取出训练集,即这80%的数据是已经打好了label。它没有明显的训练过程,在程序开始运行时,把数据集加载到内存后,不需要进行训练,就可以针对测试集开始分类。对于测试集的一个样本,选取在它周围的5的距离最近的点,观察它们属于哪个分类,将该样本投给分类占比最大的那个类别,以此类推。
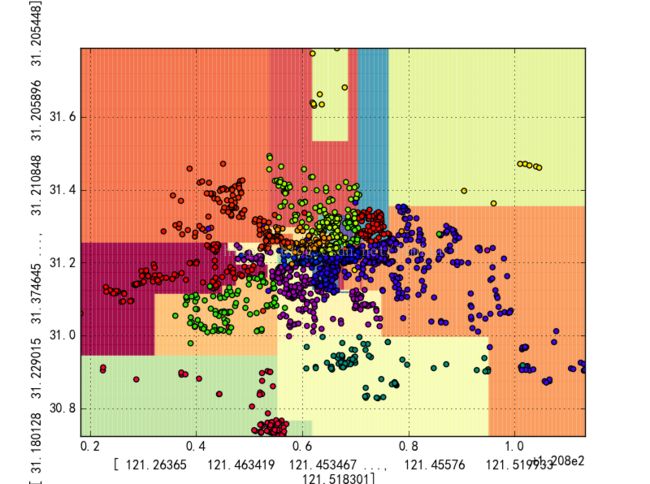
说到有监督,还是要拿分类器做一下试试,于是我就拿了决策树和SVM进行交叉验证,发现两个的准确度为0.8837和0.8304,不如KNN的效果更好。想想本来坐标分类就是基于距离测算,决策树的切割为横纵切割,而坐标在地图上是更加不规则的。以下为决策树的效果显示,从缺点来看,决策树将最上面的右上的样本隔开,中间多了两个类别,其实是不对的,样本量的缺失同样会对决策树造成不小的影响。
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
clf = DecisionTreeClassifier(criterion='entropy', max_depth=100, min_samples_leaf=3)
scores = cross_validation.cross_val_score(clf, X, Y, cv=10)
print scores.mean()
import matplotlib
clf = DecisionTreeClassifier(criterion='entropy', max_depth=100, min_samples_leaf=3)
dt_clf = clf.fit(X, Y)
N, M = 500, 500 # 横纵各采样多少个值
x1_min, x1_max = X[:, 0].min(), X[:, 0].max() # 第0列的范围
x2_min, x2_max = X[:, 1].min(), X[:, 1].max() # 第1列的范围
t1 = np.linspace(x1_min, x1_max, N)
t2 = np.linspace(x2_min, x2_max, M)
x1, x2 = np.meshgrid(t1, t2) # 生成网格采样点
x_test = np.stack((x1.flat, x2.flat), axis=1) # 测试点
y_hat = dt_clf.predict(x_test) # 预测值
y_hat = y_hat.reshape(x1.shape) # 使之与输入的形状相同
plt.pcolormesh(x1, x2, y_hat, cmap=plt.cm.Spectral, alpha=0.5) # 预测值的显示Paired/Spectral/coolwarm/summer/spring/OrRd/Oranges
plt.scatter(X[:, 0], X[:, 1], c=Y, edgecolors='k',cmap=plt.cm.prism) # 样本的显示
plt.xlabel(X[:, 0])
plt.ylabel(X[:, 1])
plt.xlim(x1_min, x1_max)
plt.ylim(x2_min, x2_max)
plt.grid()
plt.show()
from sklearn import svm
from sklearn import metrics#准确度
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size = 0.2)
clf = svm.SVC(C=0.8, kernel='poly', gamma=20, decision_function_shape='ovr')
clf.fit(x_train, y_train)
x1_min, x1_max = X[:, 0].min(), X[:, 0].max() # 第0列的范围
x2_min, x2_max = X[:, 1].min(), X[:, 1].max() # 第1列的范围
x1, x2 = np.mgrid[x1_min:x1_max:500j, x2_min:x2_max:500j] # 生成网格采样点
grid_test = np.stack((x1.flat, x2.flat), axis=1) # 测试点
grid_hat = clf.predict(grid_test) # 预测分类值
grid_hat = grid_hat.reshape(x1.shape) # 使之与输入的形状相同
matplotlib.rcParams['font.sans-serif'] = [u'SimHei']
matplotlib.rcParams['axes.unicode_minus'] = False
plt.pcolormesh(x1, x2, grid_hat, cmap=plt.cm.Spectral, alpha=0.8) # Paired/coolwarm/summer/spring/OrRd/Oranges
plt.scatter(X[:, 0], X[:, 1], c=Y, edgecolors='k', s=50, cmap=plt.cm.prism) # 样本的显示
plt.scatter(x_test[:, 0], x_test[:, 1], s=120, facecolors='none', zorder=10) # 圈中测试集样本
plt.xlabel(X[:, 0], fontsize=13)
plt.ylabel(X[:, 1], fontsize=13)
plt.xlim(x1_min, x1_max)
plt.ylim(x2_min, x2_max)
plt.title(u'SVM二特征分类', fontsize=15)
plt.grid()
plt.show()