大数据里的存储格式
hive里的存储格式
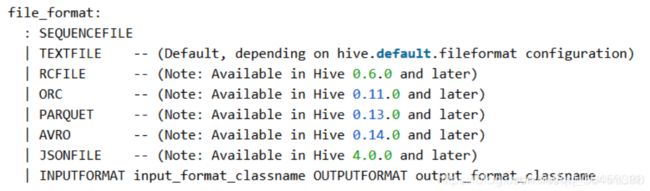
hive里默认存储是textfile
hive (default)> set hive.default.fileformat;
hive.default.fileformat=TextFile
数据表存储方式如下指定
hive (default)> create table t_2(id int) stored as INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat';
也可以直接
hive (default)> create table t_3(id int) stored as textfile;
看下两张表的结构
hive (default)> desc formatted t_2/t_3;
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat行式存储
优点:保证每一行在一个block里,如果是select *这种操作,行快
缺点:如果ABCD是不同类型,只能使用一种压缩格式,压缩比不好

列式存储
优点:不同数据类型的列可以采用合适的压缩(内部自己解决,不需要手动设定),如果只要几列,列式更快,比如只要3列行式存储仍要全量读取。这里几列一组是随机的。

TextFile格式
hive存储的默认格式,行式存储。
文本格式里所有的内容都是字符串,然而hive里数据有schema(元数据信息),也就是数据可以有多种数值类型。所以textfile存储过程中会有转换类型,这种资源开销较大。
Sequencefile格式
record是存储的数据,采用key-value方式存储。所以体积要更大。如果压缩,只是压缩值。
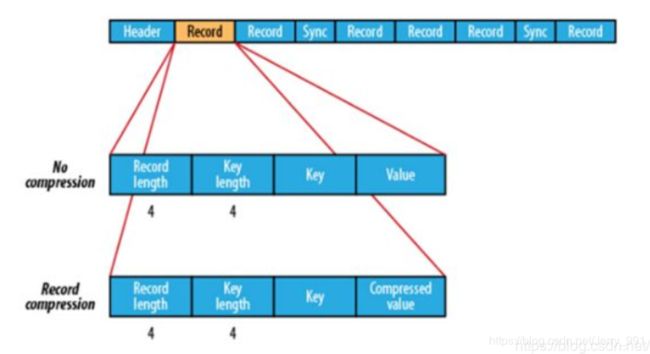
性能:
create table page_views_sequencefile(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
stored as sequencefile;
load data local inpath '/home/hadoop/data/page_views.dat' overwrite into table page_views_sequencefile;
报错,文件读不了,因为文本格式不能直接转变成其他格式,要先以textfile存储,然后导出数据到其他格式的表。这里用insert方式导数。
insert into table page_views_sequencefile select * from page_views;
数据反而更大了,这就是因为存储是键值对的方式
[hadoop@hadoop000 data]$ hadoop fs -du -h /user/hive/warehouse/page_views
18.1 M 18.1 M /user/hive/warehouse/page_views/page_views.dat
[hadoop@hadoop000 data]$ hadoop fs -du -h /user/hive/warehouse/page_views_sequencefile
20.6 M 20.6 M /user/hive/warehouse/page_views_sequencefile/000000_0
RCfile
行列混合存储
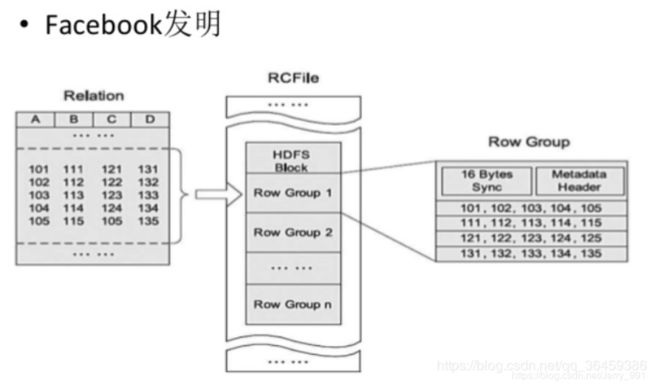
性能:
create table page_views_rcfile(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
stored as rcfile;
insert into table page_views_rcfile select * from page_views;
[hadoop@hadoop000 data]$ hadoop fs -du -h /user/hive/warehouse/page_views
18.1 M 18.1 M /user/hive/warehouse/page_views/page_views.dat
[hadoop@hadoop000 data]$ hadoop fs -du -h /user/hive/warehouse/page_views_sequencefile
20.6 M 20.6 M /user/hive/warehouse/page_views_sequencefile/000000_0
有问题,这个窗口启动了压缩方式,要换一个窗口
[hadoop@hadoop000 data]$ hadoop fs -du -h /user/hive/warehouse/page_views_rcfile
3.2 M 3.2 M /user/hive/warehouse/page_views_rcfile/000000_0
重建个窗口
hive (default)> insert overwrite table page_views_rcfile select * from page_views;
正常结果
[hadoop@hadoop000 data]$ hadoop fs -du -h /user/hive/warehouse/page_views_rcfile
17.9 M 17.9 M /user/hive/warehouse/page_views_rcfile/000000_0
parquet列式存储

和orc是两种主流存储方式
默认gzip
create table page_views_parquet(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
stored as parquet;
insert into table page_views_parquet select * from page_views;
[hadoop@hadoop000 data]$ hadoop fs -du -h /user/hive/warehouse/page_views_parquet
13.1 M 13.1 M /user/hive/warehouse/page_views_parquet/000000_0
不压缩就这么厉害啦,试试压缩咯
hive (default)> set parquet.compression=gzip;
hive (default)> set parquet.compression;
parquet.compression=gzip
create table page_views_parquet_gzip stored as parquet as select * from page_views;
[hadoop@hadoop000 data]$ hadoop fs -du -h /user/hive/warehouse/page_views_parquet_gzip
3.9 M 3.9 M /user/hive/warehouse/page_views_parquet_gzip/000000_0
ORC存储
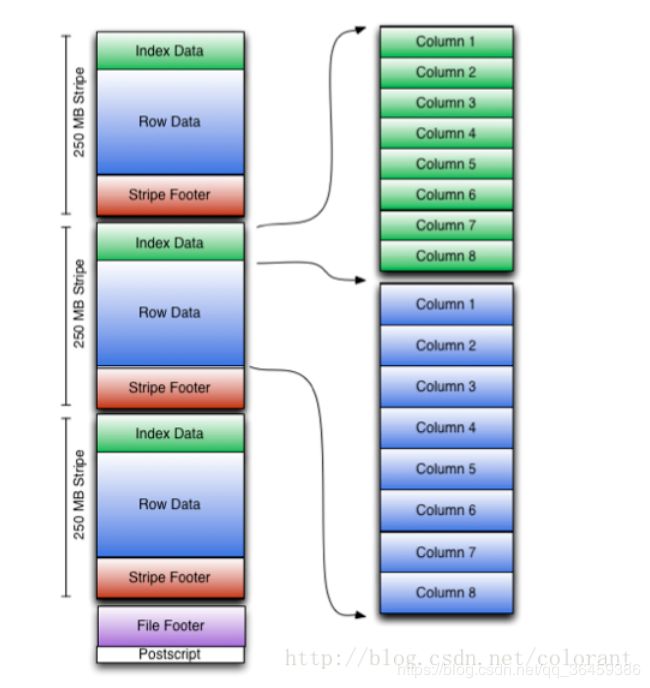
默认zlib:
create table page_views_orc(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
stored as orc;
insert into table page_views_orc select * from page_views;
[hadoop@hadoop000 data]$ hadoop fs -du -h /user/hive/warehouse/page_views_orc
2.8 M 2.8 M /user/hive/warehouse/page_views_orc/000000_0
从查询角度比较各种存储
hive (default)> select count(1) from page_views where session_id='B58W48U4WKZCJ5D1T3Z9ZY88RU7QA7B1';
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 4.48 sec HDFS Read: 1902268
hive (default)> select count(1) from page_views_sequencefile where session_id='B58W48U4WKZCJ5D1T3Z9ZY88RU7QA7B1';
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 4.74 sec HDFS Read: 2050926
hive (default)> select count(1) from page_views_rcfile where session_id='B58W48U4WKZCJ5D1T3Z9ZY88RU7QA7B1';
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 3.73 sec HDFS Read: 3725383
hive (default)> select count(1) from page_views_parquet where session_id='B58W48U4WKZCJ5D1T3Z9ZY88RU7QA7B1';
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 4.55 sec HDFS Read: 2687017
hive (default)> select count(1) from page_views_orc where session_id='B58W48U4WKZCJ5D1T3Z9ZY88RU7QA7B1';
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 3.8 sec HDFS Read: 1257463