python3.6爬虫案例:爬取百度歌单。
一、写在前面。
由于先前实验室学术研究的需要,自己开始学习python爬虫技术。学习的过程中写了几个爬虫的案例,分别有:百度音乐歌单爬取,百思不得姐视频爬取、潮秀网图片爬取(里面尺度有点大,学习乐趣也不少^_^)、顶点小说爬取、历史天气爬取等。接下来就按照顺序一一贴出来和大家一起分享,希望对学习爬虫的朋友有所益处,也欢迎大家一起学习交流。
这次我们先聊聊爬取百度音乐歌单,网址链接为:http://music.baidu.com/tag。我们打开看看长什么样^_^。

我们把这些歌单按照标签分类爬取:标签(热门、心情等)可以创建文件夹,歌单创建txt文件名,txt文本内放歌曲信息(序号、歌名、歌手等)。
在开始之前我先和大家说下本次小项目使用了哪些模块:requests、BeautifulSoup、os等模块。requests模块用于请求网页;BeautifulSoup用于解析网页、os模块用于创建文件夹。说到这我们可以开始进入正题啦。
二、爬取步骤说明。
思路:我们首先爬取标签以及标签下歌单的链接;然后据此爬取所有歌单下的歌曲信息。
1.爬取标签及歌单链接。
点击网页右键的检查(大多浏览器均支持)查看网页源代码可以发现:所有的歌曲标签在网页标签
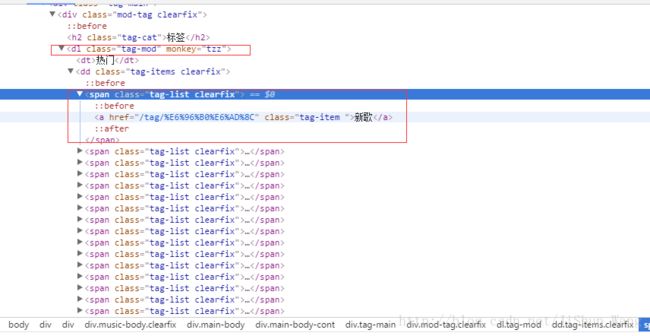
找到了所需信息的位置,我们就可以写代码啦!文件为:CrawlSongTag.py。
import requests
from bs4 import BeautifulSoup
#获取网页信息
def get_html(url):
html = requests.get(url)
html.encoding = 'utf-8'
return html
def get_info(html):
f = open('F://python program//百度音乐分类歌单//songTag.txt', 'w', encoding = 'utf-8')
soup = BeautifulSoup(html.text, 'lxml')
tagOne = soup.find_all('dl', attrs={'class':'tag-mod'})
for tag_items in tagOne:
tag = tag_items.find('dt').get_text()#获取标签名
f.write(tag + ':\n')
tag_list = tag_items.find_all('span', attrs={'class':['tag-list','clearfix']})
for tag_item in tag_list:
info = tag_item.find('a')
title = info.get_text()#获取分类名称
href = info['href']#获取分类的链接
f.write('\t' + title + ';' + href + '\n')
f.close()
def main():
url = 'http://music.baidu.com/tag'
soup = get_html(url)
get_info(soup)
print('Over!')
if __name__ == '__main__':
main()运行上面的代码会得到songTag.txt文件,瞧下:

2.歌曲爬取。
我们随便找一个标签下的歌单看下,比如热门下的新歌:

发现歌曲还不少呢。经过定位可知:歌曲信息位于
import os
import requests
from bs4 import BeautifulSoup
FILE = 'F://python program//百度音乐分类歌单//'
#创建新的文件夹
def creatFile(element):
path = FILE
title = element
new_path = os.path.join(path, title)
if not os.path.isdir(new_path):
os.makedirs(new_path)
return new_path
#获取网页信息
def downLoad(url):
html = requests.get(url)
html.encoding = 'utf-8'
return html
#爬取网页中的指定信息
def get_info(html, flag, fOut):
f = open(fOut, 'a', encoding = 'utf-8')
soup = BeautifulSoup(html.text, 'lxml')
li =soup.find_all('li', attrs={'class':['bb-dotimg','clearfix','song-item-hook','csong-item-hook']})
for i in li:
song_item = i.find('div', attrs={'class':['song-item','clearfix']})
# time.sleep(0.1)
try:
singerRaw = song_item.find('span', attrs={'class':'singer'})
singer = singerRaw.find('span', attrs={'class':'author_list'})['title']#歌手
ul = song_item.find('span', attrs={'class':'song-title'})
info = ul.find('a', attrs={'target':'_blank'})
title = info.get_text()#获取歌曲标题
songUrl = info['href']#获取歌曲链接
f.write(str(flag) + ';'+ singer+ ';' + title + ';'+'http://music.baidu.com'+ songUrl +'\n')
flag += 1
except:
print('歌曲已经下架,爬取有误!')
pageurl = soup.find('a', attrs={'class':'page-navigator-next'})
f.close()
if pageurl:
# print(pageurl['href'])
return flag, pageurl['href'].strip()
return flag, None
def main():
fInput = open('F://python program//百度音乐分类歌单//songTag.txt', 'r', encoding = 'utf-8')
print("-----")
line = fInput.readline()
while line:
print('开始下一个主题音乐爬取')
lin = line.strip()
if len(lin) < 7:
b = list(lin)[0:-1]
b = str(b[0]+b[1])
path = creatFile(b)
line = fInput.readline()
else:
store = lin.split(';')
tag = store[0]
fOutput =path+'//'+tag+'.txt'
href = store[1]
url = href.strip()
i = 1
print(tag+'--'+url)
while url:#用于歌曲页码下一页的跳转
urls = 'http://music.baidu.com' + url
html = downLoad(urls)
i,url = get_info(html, i, fOutput) #i是歌单下歌曲序号,url为下一页的网址链接。
line = fInput.readline()
fInput.close()
print("over")
if __name__ == '__main__':
main()运行程序后我们可以得到下面的文件夹:(限于网速就不全重新运行了,代码是正确的,运来歌单网页代码也没有变化,大家自行敲一遍运行即可。)
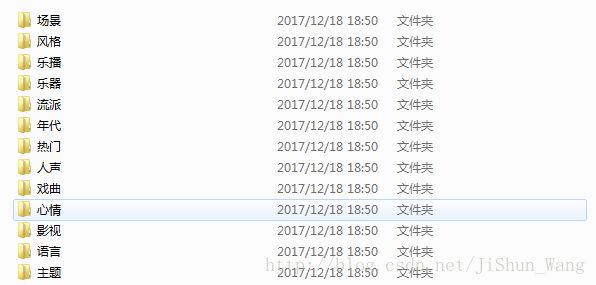
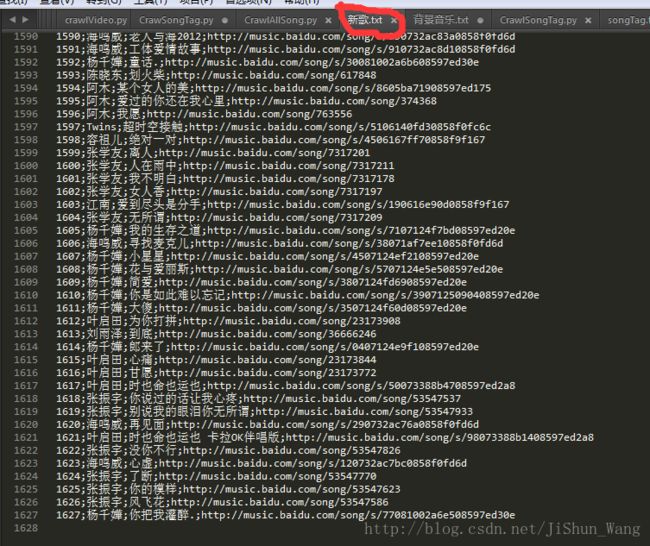
重新爬取了“新歌”歌单,歌曲挺多:
三、总结。
到这里程序的说明基本上结束了,总体看来还是比较简单的难度不大。今后我会陆续将其他小项目更新。希望大家持续关注,有问题大家可以留言交流。