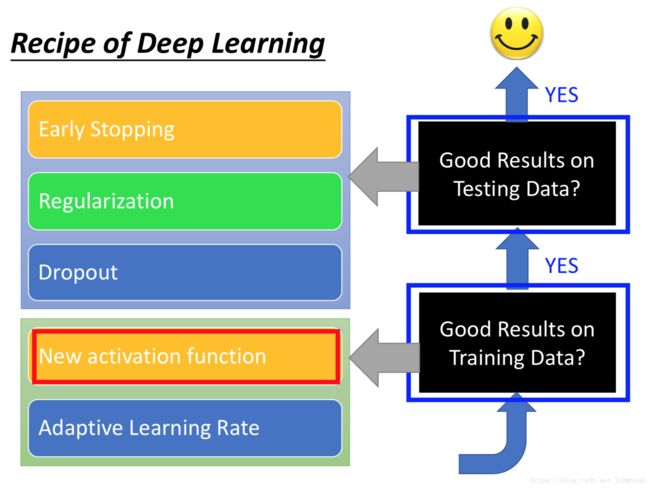
9、【李宏毅机器学习(2017)】Tips for Deep Learning(深度学习优化)
在上一篇博客中介绍了Keras,并使用Keras训练数据进行预测,得到的效果并不理想,接下来将以此为基础优化模型,提高预测的精度。
目录
- 误差分析
- 模型误差原因分析
- 模型优化方案
- New activation function
- Vanishing Gradient Problem
- ReLU
- Maxout
- Maxout介绍
- Maxiout方法的训练
- Adaptive Learning Rate
- Adagrad
- RMSProp
- Momentum
- Adam
- Early Stopping
- Regularization
- L2正则化
- L1正则化
- L2正则化vsL1正则化
- Dropout
误差分析
模型误差原因分析
在上一篇博客中,我们按照步骤建立了神经网络模型V1.0版本,效果很不理想,因此逐步回溯建模的过程,分析模型不理想的原因:
- 如果模型在训练集的准确率就不好,说明模型欠拟合,应该重新调整模型,提高训练集的拟合效果;
- 如果模型在训练集的准确率高而在测试集的准确率很低,就说明了模型存在过拟合的问题。

模型优化方案
针对这两种情况分别提出相应的优化措施。
New activation function
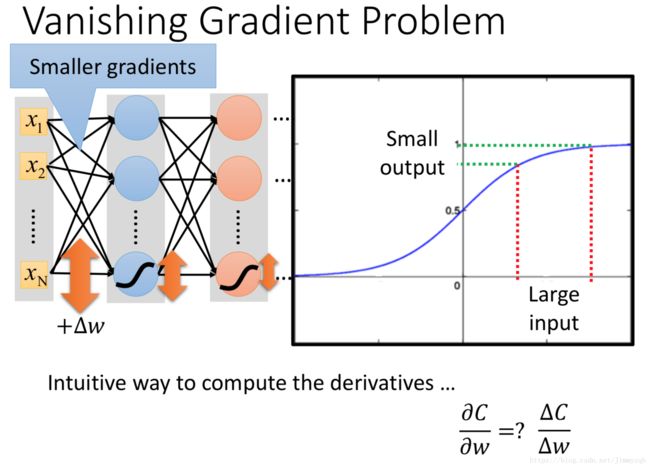
Vanishing Gradient Problem
常见的以sigmoid函数作为激活函数的神经网路在模型深度很高的时候往往存在梯度消失问题,接近input vector的神经层梯度小,在接近output vector的神经层梯度大,在学习速率一样的情况下,接近input vector的神经层学习速度慢,接近output vector的神经层学习速度快,因此会导致后面几层的神经层达到最优化而前面几层还没怎么进行调参,此时算法停止但并非最优解。如图,通过sigmoid函数会将变化减小,在多神经层的情况下,尽管很大,最终反映在后面几层的变动将大大减小。
ReLU
ReLU全称Rectified Linear Unit,以ReLU作为激活函数可以解决梯度消失问题,通过ReLU对于一个样本通常整个神经网络被简化为较简单的形式(剔除为output为0的神经元)。

ReLU还有多种变形:
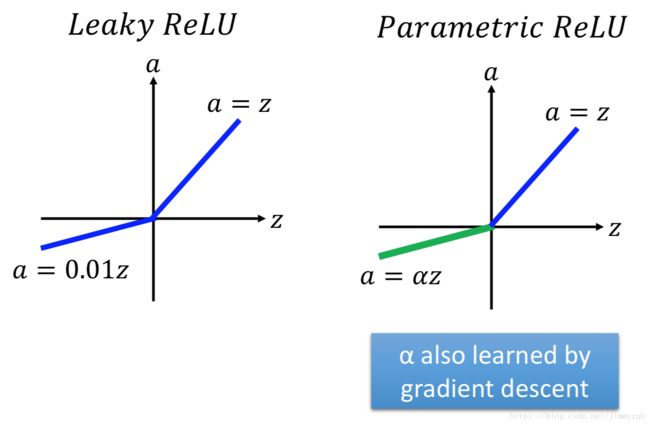
Maxout
Maxout介绍
Maxout让神经网络自动地学习适合的激活函数,如图, (x1,x2) ( x 1 , x 2 ) 作为输入向量,连接4个神经元,得到4个数值,以两个为一组,取组内最大值,再重复一次得到2、4。
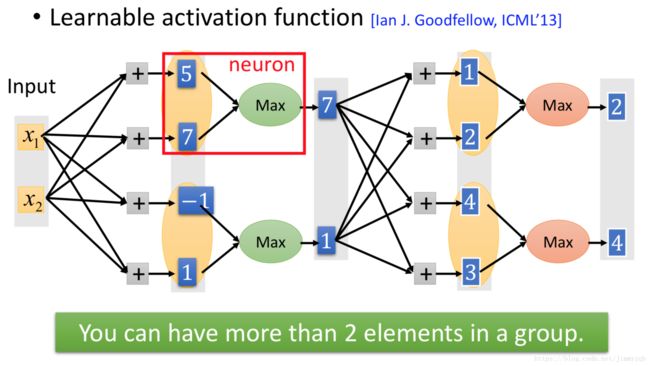
如图所示,可以通过Maxout得到ReLU:
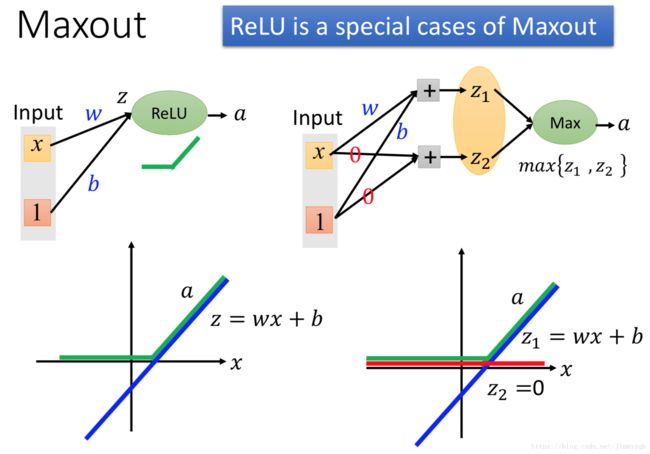
更一般地,我们可以通过Maxout(可以调节更多的神经元在一组)得到其他更复杂的函数:
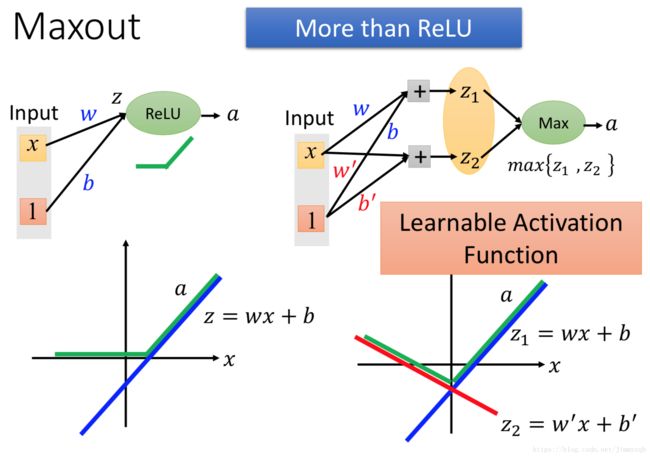
Maxiout方法的训练
对于一组给定的输入向量,红色框表示计算得到的各组之中的最大值,此时的激活函数相当于一个线性函数,此时再利用反向传播算法计算梯度更新参数。

Adaptive Learning Rate
传统的神经网络模型设定各个神经元在使用梯度下降算法更新参数时的学习速率是相同且恒定,为了提高模型的拟合效果,现在考虑采用自适应的学习速率进行模型拟合。
Adagrad
Adagrad是一种常见的自适应的学习速率算法,详见前博客。
RMSProp
如果Loss Funtion是很复杂的函数,依赖与二阶导数相对稳定前提的Adagrad算法并不适用,现在考虑一种新的算法RMSProp。RMSProp算法考虑了Loss Funtion分布的疏密因素(Loss Funtion函数等高线越稀疏,学习速率越大),按此逻辑设置不同的学习速率。

Momentum
为了尝试解决得到的解是局部最优的无效解,现在在梯度下降过程中引入物理学中的惯性,如图,在引入了惯性度量后,尽管局部最优点偏导数为0,但是由于惯性参数仍然会更新,因此能够一定程度上缓解局部最优化问题。

如图可以更直观地表示整个参数更新的原理和过程,初始化 θ0 θ 0 ,此时惯性 v0 v 0 为0,红色表示偏导数 ▽L ▽ L ,绿色表示由于之前运动所具有的关系(反向和原来的运动方向保持一致),这一点下一步的运动为 ▽L ▽ L 和 v v 的矢量和。
考虑上一时刻的运动方向等价于考虑了之前所有的 ▽L ▽ L

Adam
Adam是RMSProp和Momentum的结合,算法如下。

当模型在训练集拟合效果好而在测试集效果很差,说明产生了过拟合问题,
Early Stopping
当模型在训练集拟合效果好而在测试集效果很差,说明产生了过拟合问题,此时可以Early Stopping,防止过拟合问题,如图,如果模型在训练集的拟合效果好,随着epochs的增加在训练集上的Total loss应该单调递减,由于过拟合,在测试集上的Total loss先减后增,因此我们选择在测试集上的Total loss曲线上的最低点停止。

Regularization
L2正则化
现在使用正则化来解决过拟合问题,在原来的Loss Function上加上正则惩罚项,和原来没有加惩罚项的结果对比,参数更容易趋向于0,由此大大简化了模型的结构。

L1正则化
由于sgn(w)这一项使得L1相对于L2更容易得到趋近于0的解。

L2正则化vsL1正则化
L1和L2相比不同的地方在于二者都让参数接近于0,但是做法不一样:
- L2是乘以一个固定的小于1的值( 1−ηλ 1 − η λ ),因此L2对比较大的参数的惩罚比较强,L2得到的参数往往聚集于0附近,但不会非常靠近
- L1是减去一个固定的值( ηλsgn(wt) η λ s g n ( w t ) ),L1不管参数大小,惩罚相同,得到的参数差距拉的比较大,0附近的参数更接近于0
Dropout
每次一次开始训练的时候,都对样本的特征、神经元进行随机p%的求其丢弃,按此结构利用反向传播算法更新参数,
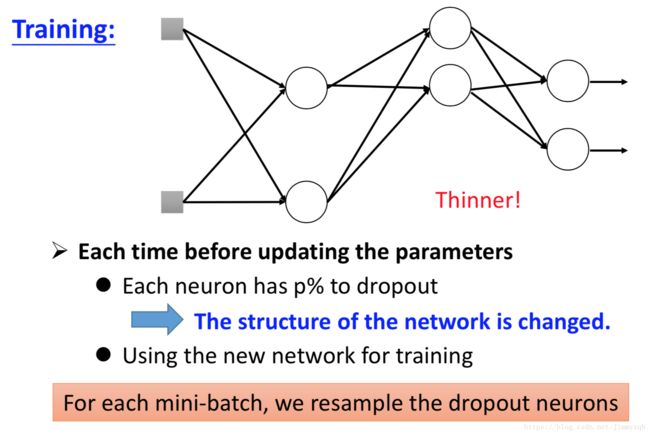
在测试集运行模型时应该使用全部的特征和神经元,且此时由训练集估计出来的 w w 应该全部乘以(1-p%)。
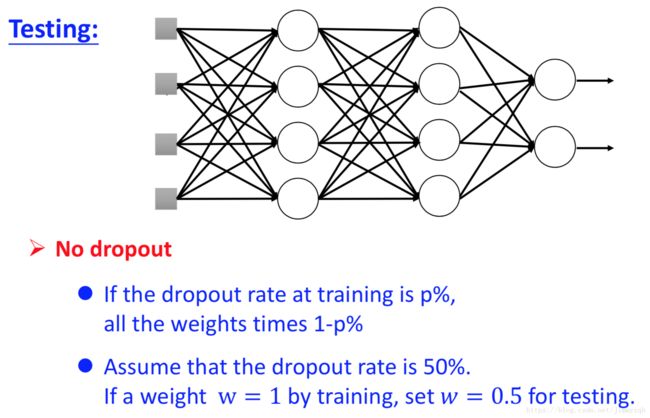
我们可以假设一个例子方便对第二点有一个直观的解释:
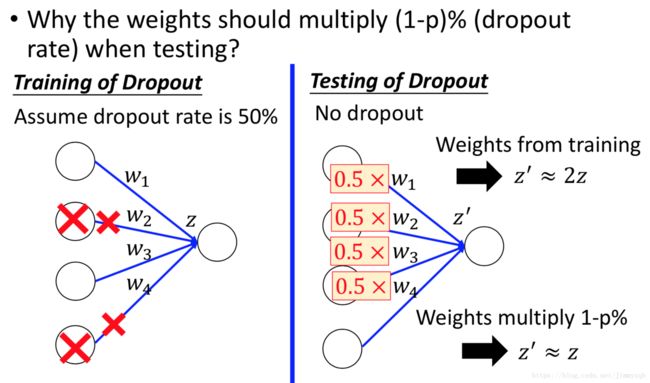
Dropout本质是一种ensemble的方法,左右两个模型近似:
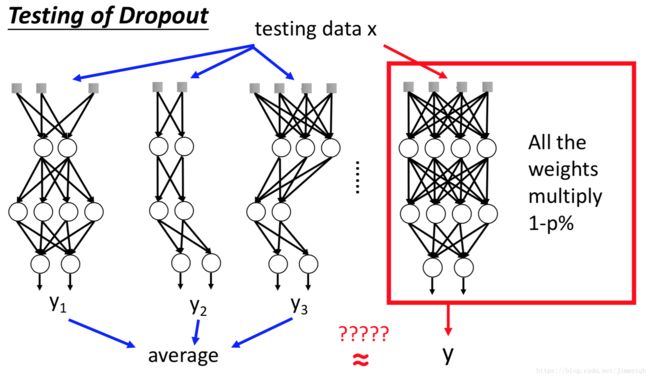
举个便于理解的例子,现在假设有输入向量为二维,只有一个神经元的神经网络,Dropout有4种可能,4种可能的输出的平均值等于参数乘以(1-p%):

尽管这个关系只在激活函数为线性函数的时候才严格相等,但是在实际的运用中不管激活函数的形式如何,近似关系都成立。