推荐系统
1、推荐系统的发展历史
1994年,美国明尼苏达大学的GroupLens研究组推出了GroupLens系统,该系统首次提出了基于协同过滤来进行推荐的思想,并将推荐问题建立了一个形式化的模型。该推荐系统模型引领了推荐系统今后十几年的发展。GroupLens所提出的推荐系统就是目前基于用户的协同过滤推荐算法(user-based collaboration filtering algorithms)。在此之后,基于物品的协同过滤算法(item-based collaborative filtering algorithms),基于矩阵分解的协同过滤算法(SVD-based/NMF-based)等算法逐渐被提出。

2、推荐系统的输入数据
推荐系统的输入数据可以归纳为用户(user)、物品(item)和评价(review)三个层面。
(1)物品(item)
用来描述一个物品的性质,也被称为item profile。比如对于图书推荐,item profile可以包括图书类别、作者、出版社、出版时间等;对于新闻推荐,item profile可以包括新闻文本内容、关键词、时间等。

(2)用户(user)
用来描述一个用户的“个性”,即user profile,例如用户的性别、年龄,年收入等。
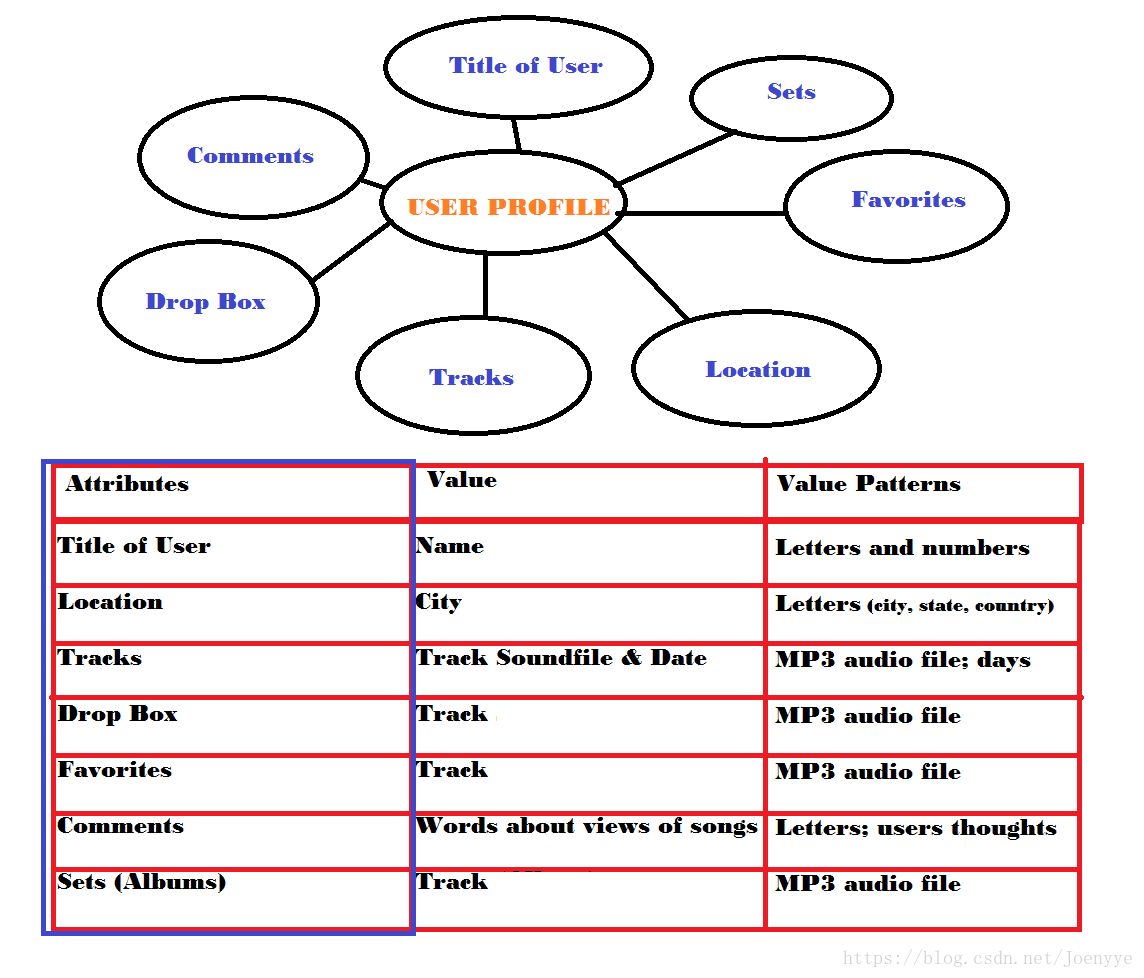
(3)评价(review)
评价可以是用户对某一物品的打分、评论等反映用户对物品喜爱程度的度量。总体可以分为两类,一是显式的用户反馈,例如评分、评论。二是隐式的用户反馈,例如用户查看了某物品的信息、用户在某一页面的停留时间、用户将商品放入心愿单。

3、推荐系统的输出数据
对于一个特定的用户,推荐系统给他的输出是一个“推荐列表”,该推荐列表按照优先级顺序给出了该用户可能感兴趣的物品。
推荐系统另外一个重要的输出是“推荐理由”,它表述系统为什么认为推荐该物品是合理的,如“购买了xx商品的用户有90%也购买了该商品”等等。
为了解决推荐合理性的问题,推荐理由在产业界作为一个重要的吸引用户接受推荐的方法,在学术界越来越受到关注。

4、推荐系统的两大核心问题
(1)预测(prediction)
“预测”所要解决的主要问题是推断用户对每一个物品的喜好程度。其主要手段是根据已有的信息来计算用户对某个未打分的物品可能的打分。
(2)推荐(recommendation)
“推荐”所要解决的问题是根据预测环节所计算的结果,向用户推荐他没有打分的物品。“推荐”的核心步骤就是对推荐结果的排序(ranking)。按照预测分值的高低直接排序是一种比较合理的方法,但是在实际系统中,排序要考虑的因素很多,比如年龄段,用户在最近一段时间内的购买记录等,user profile往往在这个环节派上用场。
5、推荐方法的分类
(1)依据推荐结果是否因人而异
主要分为大众推荐和个性推荐。大众推荐的典型例子就是查询推荐,往往只与当前查询有关,而很少与该用户直接相关。例如微博的热门新闻或是明星推荐。个性化推荐会根据用户的兴趣爱好、历史记录等匹配推荐,例如今日头条的广告语“你关心的,才是头条”和“信息创造价值”,都是强调个性化推荐。
(2)依据推荐方法的不同
根据如何发现数据的相关性,产生了不同的推荐方法。大部分推荐系统的推荐原理还是基于物品或用户的相似性,大致可分为:基于人口统计学的推荐(demographic-based recommendation,基于内容的推荐(content-based recommendation ),基于协同过滤的推荐(collaborative filtering-based recommendation),以及混合型推荐系统(hybrid recommendation)。
其中基于协同过滤的推荐被研究的最为深入,他又可以分为基于用户的推荐(user-based recommendation),基于物品的推荐(item-based recommendation),基于社交网络关系的推荐(social-based recommendation),基于模型的推荐(model-based recommendation)等。
(3)依据推荐模型的构建方式的不同
可以分为基于用户或物品本身的启发式推荐(heuristic-based,又称为memory-based recommendation)、基于关联规则的推荐(association rule mining for recommendation),基于模型的推荐,以及混合型推荐系统。
6、典型推荐算法的概述
(1)基于人口统计学的推荐(demographic-based)
demographic-based方法对应于user-profile,user profile中记录了该用户的性别、年龄、活跃时间等元数据。该方法的基本假设是,一个用户有可能会喜欢与其相似的用户所喜欢的物品。
(2)基于内容的推荐(content-based)
基本假设是,一个用户可能会喜欢和他曾经喜欢过的物品相似的物品。
(3)基于协同过滤的推荐
根据用户对物品或内容信息的偏好,发现物品或者内容本身的相关性,或用户的相关性,然后再给予这些关联性进行推荐。用户对物品的喜好或评分矩阵往往是一个很大的稀疏矩阵,为了减少计算量,可对物品或用户进行聚类(clustering items for collaborative filtering)。
user-based方法是假设“用户可能会喜欢和他具有相似爱好的用户所喜欢的物品”,与demographic方法不同的是,这里的相似用户不是通过user profile进行计算出来的,而是用用户的打分历史记录计算出来的。这里的基本思想是,具有相似偏好的用户,他们在所有物品上的打分情况也是相似的。
item-based方法是亚马逊的专利算法,基本假设是“用户可能会喜欢与他之前喜欢的物品相似的物品”。与content-based方法不同之处是,相似物品不是通过item profile计算的,而是通过物品被打分的历史记录来计算的。
基于模型的推荐是先用历史数据训练得到一个模型,在用此模型进行预测。
6、推荐系统的评价指标
目前评估推荐系统的指标可分为“准确度(accuracy)”和“可用性(usefulness)”。其中准确度衡量的是推荐系统的预测结果与用户行为之间的误差,还可以细分为“预测准确度(prediction accuracy)”和“决策支持准确度(decision-support accuracy)”。
预测准确度又可分为“评分预测准确度”、“使用预测准确度”、“排序预测准确度”等,以MAE\NMAE\RMSE\ARMSE等常用的统计指标,计算推荐系统对消费者喜好的预测与消费者实际的喜好的误差平均值。
决策支持准确度以correlation(关联度,包括pearson、spearman、kendall Tau等)、reversal rate、precision、recall\F-measure、ROC curve、swetA指标、AVS(average ranking score,平均排序分)等为主要工具。
推荐系统的可用性一般用覆盖率(召回率)来描述,包括用户覆盖率和物品覆盖率。