JAVA 与 MyCat(5) 类的加载 Java内省/反射机制 注解Annotation 详解
通过mycat来学习java了^^。
接前一篇:http://blog.csdn.net/john_chang11/article/details/78734051
上一篇了解了XML解析的四种方式,并对MyCat的源码进行了修改,这一篇接着往下看:
dtd = XMLRuleLoader.class.getResourceAsStream(dtdFile);
xml = XMLRuleLoader.class.getResourceAsStream(xmlFile);
// 读取出语意树
Element root = ConfigUtil.getDocument(dtd, xml).getRootElement();
// 加载Function
loadFunctions(root);
// 加载TableRule
loadTableRules(root);看loadFunctions(root);方法的内容:
private void loadFunctions(Element root)
throws ClassNotFoundException, InstantiationException, IllegalAccessException, InvocationTargetException {
List list = root.elements("function");
for (Element e : list) {
// 获取name标签
String name = e.attributeValue("name");
// 如果Map已有,则function重复
if (functions.containsKey(name)) {
throw new ConfigException("rule function " + name + " duplicated!");
}
// 获取class标签
String clazz = e.attributeValue("class");
// 根据class利用反射新建分片算法
AbstractPartitionAlgorithm function = createFunction(name, clazz);
// 根据读取参数配置分片算法
ParameterMapping.mapping(function, ConfigUtil.loadElements(e));
// 每个AbstractPartitionAlgorithm可能会实现init来初始化
function.init();
// 放入functions map
functions.put(name, function);
}
} 先看一下MyCat是如何完成类的动态加载和初始化。
第一步:
createFunction(name, clazz);
private AbstractPartitionAlgorithm createFunction(String name, String clazz)
throws ClassNotFoundException, InstantiationException, IllegalAccessException, InvocationTargetException {
Class clz = Class.forName(clazz);
// 判断是否继承AbstractPartitionAlgorithm
if (!AbstractPartitionAlgorithm.class.isAssignableFrom(clz)) {
throw new IllegalArgumentException(
"rule function must implements " + AbstractPartitionAlgorithm.class.getName() + ", name=" + name);
}
return (AbstractPartitionAlgorithm) clz.newInstance();
}第二步:
ParameterMapping.mapping(function, ConfigUtil.loadElements(e));
public static void mapping(Object object, Map parameter) throws IllegalAccessException,
InvocationTargetException {
//获取用于导出clazz这个JavaBean的所有属性的PropertyDescriptor
PropertyDescriptor[] pds = getDescriptors(object.getClass());
for (int i = 0; i < pds.length; i++) {
PropertyDescriptor pd = pds[i];
Object obj = parameter.get(pd.getName());
Object value = obj;
Class cls = pd.getPropertyType();
//类型转换
if (obj instanceof String) {
String string = (String) obj;
if (!StringUtil.isEmpty(string)) {
string = ConfigUtil.filter(string);
}
if (isPrimitiveType(cls)) {
value = convert(cls, string);
}
} else if (obj instanceof BeanConfig) {
value = createBean((BeanConfig) obj);
} else if (obj instanceof BeanConfig[]) {
List private static PropertyDescriptor[] getDescriptors(Class clazz) {
//PropertyDescriptor类表示JavaBean类通过存储器导出一个属性
PropertyDescriptor[] pds;
List list;
PropertyDescriptor[] pds2 = descriptors.get(clazz);
//该clazz是否第一次加载
if (null == pds2) {
try {
BeanInfo beanInfo = Introspector.getBeanInfo(clazz);
pds = beanInfo.getPropertyDescriptors();
list = new ArrayList();
//加载每一个类型不为空的property
for (int i = 0; i < pds.length; i++) {
if (null != pds[i].getPropertyType()) {
list.add(pds[i]);
}
}
pds2 = new PropertyDescriptor[list.size()];
list.toArray(pds2);
} catch (IntrospectionException ie) {
LOGGER.error("ParameterMappingError", ie);
pds2 = new PropertyDescriptor[0];
}
}
descriptors.put(clazz, pds2);
return (pds2);
}
第三步:
function.init();
private static int[] toIntArray(String string) {
String[] strs = io.mycat.util.SplitUtil.split(string, ',', true);
int[] ints = new int[strs.length];
for (int i = 0; i < strs.length; ++i) {
ints[i] = Integer.parseInt(strs[i]);
}
return ints;
}MyCat通过上面三步,完成分表函数的动态加载和初始化,一共涉及到三个Java知识点:类的动态加载(也就是类的运行时加载)、Java内省、Java反射机制,现在就来看看Java的这部分内容。
本文部分内容引用网络文章:http://wiki.jikexueyuan.com/project/java-vm/java-debug.html
1.类的加载
JVM 的类加载是通过 ClassLoader 及其子类来完成的,类的层次关系和加载顺序可以由下图来描述: 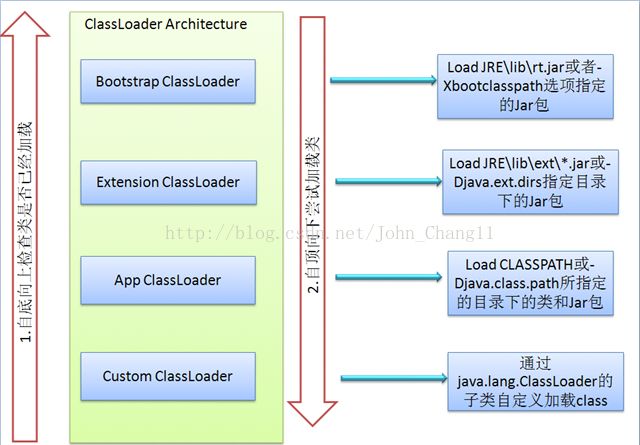
本图片引自网络文章:http://wiki.jikexueyuan.com/project/java-vm/java-debug.html
1)Bootstrap ClassLoader
负责加载$JAVA_HOME中jre/lib/rt.jar里所有的 class,由 C++ 实现,不是 ClassLoader 子类。2)Extension ClassLoader
负责加载Java平台中扩展功能的一些 jar 包,包括$JAVA_HOME中jre/lib/*.jar或-Djava.ext.dirs指定目录下的 jar 包。3)App ClassLoader
负责加载 classpath 中指定的 jar 包及目录中 class。4)Custom ClassLoader
属于应用程序根据自身需要自定义的 ClassLoader,如 Tomcat、jboss 都会根据 J2EE 规范自行实现 ClassLoader。加载过程中会先检查类是否被已加载,检查顺序是自底向上,从 Custom ClassLoader 到 BootStrap ClassLoader 逐层检查,只要某个 Classloader 已加载就视为已加载此类,保证此类只所有 ClassLoader加载一次。而加载的顺序是自顶向下,也就是由上层来逐层尝试加载此类。
代码验证:
package io.mycat.test.clss;
public class ClssLdr {
public static void main(String[] args) throws ClassNotFoundException {
// 获取默认的系统类加载器,即应用程序类加载器:App ClassLoader
ClassLoader classLoader = ClassLoader.getSystemClassLoader();
System.out.println("应用程序类加载器:" + classLoader);
// 获取应用类加载器的父类加载器,即扩展类加载器:Extension ClassLoader
classLoader = classLoader.getParent();
System.out.println("扩展类加载器:" + classLoader);
// 获取扩展类加载器的父类加载器,即启动类加载器:Bootstrap ClassLoader
classLoader = classLoader.getParent();
System.out.println("启动类加载器:" + classLoader); // 输出为Null,无法被Java程序直接引用
// 获取当前类的类加载器,应该是应用程序类加载器
classLoader = ClssLdr.class.getClassLoader();
System.out.println("当前类的类加载器:" + classLoader);
classLoader = Class.forName("io.mycat.test.clss.ClssLdr").getClassLoader();
System.out.println("当前类的类加载器:" + classLoader);
// 获取JDK提供的Object类的类加载器,应该启动类加载器
classLoader = Class.forName("java.lang.Object").getClassLoader();
System.out.println("JDK提供的Object类的类加载器:" + classLoader); // 输出为Null
// 启动类加载器BootstrapLoader寻找类的路径
System.out.println("启动类加载器寻找类的路径:" + System.getProperty("sun.boot.class.path"));
// 扩展类加载器ExtClassLoader寻找类的路径
System.out.println("扩展类加载器寻找类的路径:" + System.getProperty("java.ext.dirs"));
// 应用程序类加载器AppClassLoader寻找类的路径
System.out.println("应用程序类加载器寻找类的路径:" + System.getProperty("java.class.path"));
}
}
应用程序类加载器:sun.misc.Launcher$AppClassLoader@1d16e93
扩展类加载器:sun.misc.Launcher$ExtClassLoader@1db9742
启动类加载器:null
当前类的类加载器:sun.misc.Launcher$AppClassLoader@1d16e93
当前类的类加载器:sun.misc.Launcher$AppClassLoader@1d16e93
JDK提供的Object类的类加载器:null
启动类加载器寻找类的路径:D:\jre1.8\lib\resources.jar;D:\jre1.8\lib\rt.jar;...
扩展类加载器寻找类的路径:D:\jre1.8\lib\ext;C:\Windows\Sun\Java\lib\ext
应用程序类加载器寻找类的路径:E:\java\mycat1.6\bin;E:\java\mycat1.6\lib\ehcache-core-2.6.11.jar;...扩展阅读:类的加载过程
该部分内容引自网络文章:http://wiki.jikexueyuan.com/project/java-vm/java-debug.html,略有修正
类从被加载到虚拟机内存中开始,到卸载出内存为止,它的整个生命周期包括:加载、验证、准备、解析、初始化、使用和卸载七个阶段。它们开始的顺序如下图所示:

其中类加载的过程包括了加载、验证、准备、解析、初始化五个阶段。在这五个阶段中,加载、验证、准备和初始化这四个阶段发生的顺序是确定的,而解析阶段则不一定,它在某些情况下可以在初始化阶段之后开始,这是为了支持 Java 语言的运行时绑定(也成为动态绑定或晚期绑定)。另外注意这里的几个阶段是按顺序开始,而不是按顺序进行或完成,因为这些阶段通常都是互相交叉地混合进行的,通常在一个阶段执行的过程中调用或激活另一个阶段。
这里简要说明下 Java 中的绑定:绑定指的是把一个方法的调用与方法所在的类(方法主体)关联起来,对 Java 来说,绑定分为静态绑定和动态绑定:
- 静态绑定:即前期绑定。在程序执行前方法已经被绑定,此时由编译器或其它连接程序实现。针对 Java,简单的可以理解为程序编译期的绑定。Java 当中的方法只有 final,static,private 和构造方法是前期绑定的。
- 动态绑定:即晚期绑定,也叫运行时绑定。在运行时根据具体对象的类型进行绑定。在 Java 中,几乎所有的方法都是后期绑定的。
下面详细讲述类加载过程中每个阶段所做的工作。
加载
加载时类加载过程的第一个阶段,在加载阶段,虚拟机需要完成以下三件事情:
- 通过一个类的全限定名来获取其定义的二进制字节流。
- 将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。
- 在 Java 堆中生成一个代表这个类的 java.lang.Class 对象,作为对方法区中这些数据的访问入口。
注意,这里第 1 条中的二进制字节流并不只是单纯地从 Class 文件中获取,比如它还可以从 Jar 包中获取、从网络中获取(最典型的应用便是 Applet)、由其他文件生成(JSP 应用)等。
相对于类加载的其他阶段而言,加载阶段(准确地说,是加载阶段获取类的二进制字节流的动作)是可控性最强的阶段,因为开发人员既可以使用系统提供的类加载器来完成加载,也可以自定义自己的类加载器来完成加载。
加载阶段完成后,虚拟机外部的 二进制字节流就按照虚拟机所需的格式存储在方法区之中,而且在 Java 堆中也创建一个 java.lang.Class 类的对象,这样便可以通过该对象访问方法区中的这些数据。
说到加载,不得不提到类加载器,下面就具体讲述下类加载器。
类加载器虽然只用于实现类的加载动作,但它在 Java 程序中起到的作用却远远不限于类的加载阶段。对于任意一个类,都需要由它的类加载器和这个类本身一同确定其在就 Java 虚拟机中的唯一性,也就是说,即使两个类来源于同一个 Class 文件,只要加载它们的类加载器不同,那这两个类就必定不相等。这里的“相等”包括了代表类的 Class 对象的 equals()、isAssignableFrom()、isInstance()等方法的返回结果,也包括了使用 instanceof 关键字对对象所属关系的判定结果。
站在 Java 虚拟机的角度来讲,只存在两种不同的类加载器:
- 启动类加载器:它使用 C++ 实现(这里仅限于 Hotspot,也就是 JDK1.5 之后默认的虚拟机,有很多其他的虚拟机是用 Java 语言实现的),是虚拟机自身的一部分。
- 所有其他的类加载器:这些类加载器都由 Java 语言实现,独立于虚拟机之外,并且全部继承自抽象类 java.lang.ClassLoader,这些类加载器需要由启动类加载器加载到内存中之后才能去加载其他的类。
- 启动类加载器:Bootstrap ClassLoader,跟上面相同。它负责加载存放在JDK\jre\lib(JDK 代表 JDK 的安装目录,下同)下,或被-Xbootclasspath参数指定的路径中的,并且能被虚拟机识别的类库(如rt.jar,所有的java.*开头的类均被 Bootstrap ClassLoader 加载)。启动类加载器是无法被 Java 程序直接引用的。
- 扩展类加载器:Extension ClassLoader,该加载器由sun.misc.Launcher$ExtClassLoader实现,它负责加载JDK\jre\lib\ext目录中,或者由java.ext.dirs 系统变量指定的路径中的所有类库(如javax.*开头的类),开发者可以直接使用扩展类加载器。
- 应用程序类加载器:Application ClassLoader,该类加载器由 sun.misc.Launcher$AppClassLoader 来实现,它负责加载用户类路径(ClassPath)所指定的类,开发者可以直接使用该类加载器,如果应用程序中没有自定义过自己的类加载器,一般情况下这个就是程序中默认的类加载器。
- 在执行非置信代码之前,自动验证数字签名。
- 动态地创建符合用户特定需要的定制化构建类。
- 从特定的场所取得 java class,例如数据库中和网络中。
这几种类加载器的层次关系如下图所示:

这种层次关系称为类加载器的双亲委派模型。我们把每一层上面的类加载器叫做当前层类加载器的父加载器,当然,它们之间的父子关系并不是通过继承关系来实现的,而是使用组合关系来复用父加载器中的代码。该模型在 JDK1.2 期间被引入并广泛应用于之后几乎所有的 Java 程序中,但它并不是一个强制性的约束模型,而是 Java 设计者们推荐给开发者的一种类的加载器实现方式。
双亲委派模型的工作流程是:如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把请求委托给父加载器去完成,依次向上,因此,所有的类加载请求最终都应该被传递到顶层的启动类加载器中,只有当父加载器在它的搜索范围中没有找到所需的类时,即无法完成该加载,子加载器才会尝试自己去加载该类。
使用双亲委派模型来组织类加载器之间的关系,有一个很明显的好处,就是 Java 类随着它的类加载器(说白了,就是它所在的目录)一起具备了一种带有优先级的层次关系,这对于保证 Java 程序的稳定运作很重要。例如,类java.lang.Object 类存放在JDK\jre\lib下的 rt.jar 之中,因此无论是哪个类加载器要加载此类,最终都会委派给启动类加载器进行加载,这便保证了 Object 类在程序中的各种类加载器中都是同一个类
验证
验证的目的是为了确保 Class 文件中的字节流包含的信息符合当前虚拟机的要求,而且不会危害虚拟机自身的安全。不同的虚拟机对类验证的实现可能会有所不同,但大致都会完成以下四个阶段的验证:文件格式的验证、元数据的验证、字节码验证和符号引用验证。
- 文件格式的验证:验证字节流是否符合 Class 文件格式的规范,并且能被当前版本的虚拟机处理,该验证的主要目的是保证输入的字节流能正确地解析并存储于方法区之内。经过该阶段的验证后,字节流才会进入内存的方法区中进行存储,后面的三个验证都是基于方法区的存储结构进行的。
- 元数据验证:对类的元数据信息进行语义校验(其实就是对类中的各数据类型进行语法校验),保证不存在不符合 Java 语法规范的元数据信息。
- 字节码验证:该阶段验证的主要工作是进行数据流和控制流分析,对类的方法体进行校验分析,以保证被校验的类的方法在运行时不会做出危害虚拟机安全的行为。
- 符号引用验证:这是最后一个阶段的验证,它发生在虚拟机将符号引用转化为直接引用的时候(解析阶段中发生该转化,后面会有讲解),主要是对类自身以外的信息(常量池中的各种符号引用)进行匹配性的校验。
准备
准备阶段是正式为类变量分配内存并设置类变量初始值的阶段,这些内存都将在方法区中分配。对于该阶段有以下几点需要注意:
- 这时候进行内存分配的仅包括类变量(static),而不包括实例变量,实例变量会在对象实例化时随着对象一块分配在 Java 堆中。
- 这里所设置的初始值通常情况下是数据类型默认的零值(如 0、0L、null、false 等),而不是被在 Java 代码中被显式地赋予的值。
public static int value = 3;下表列出了 Java 中所有基本数据类型以及 reference 类型的默认零值:
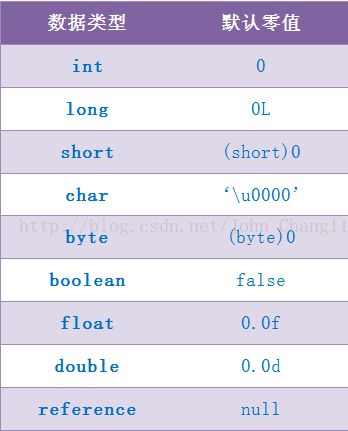
- 对基本数据类型来说,对于类变量(static)和全局变量,如果不显式地对其赋值而直接使用,则系统会为其赋予默认的零值,而对于局部变量来说,在使用前必须显式地为其赋值,否则编译时不通过。
- 对于同时被 static 和 final 修饰的常量,必须在声明的时候就为其显式地赋值,否则编译时不通过;而只被 final 修饰的常量则既可以在声明时显式地为其赋值,也可以在类初始化时显式地为其赋值,总之,在使用前必须为其显式地赋值,系统不会为其赋予默认零值。
- 对于引用数据类型 reference 来说,如数组引用、对象引用等,如果没有对其进行显式地赋值而直接使用,系统都会为其赋予默认的零值,即null。
- 如果在数组初始化时没有对数组中的各元素赋值,那么其中的元素将根据对应的数据类型而被赋予默认的零值。
假设上面的类变量 value 被定义为:
public static final int value = 3;解析
对同一个符号引用进行多次解析请求时很常见的事情,虚拟机实现可能会对第一次解析的结果进行缓存(在运行时常量池中记录直接引用,并把常量标示为已解析状态),从而避免解析动作重复进行。
解析动作主要针对类或接口、字段、类方法、接口方法四类符号引用进行,分别对应于常量池中的 CONSTANT_Class_info、CONSTANT_Fieldref_info、CONSTANT_Methodref_info、CONSTANT_InterfaceMethodref_info 四种常量类型。
- 1、类或接口的解析:判断所要转化成的直接引用是对数组类型,还是普通的对象类型的引用,从而进行不同的解析。
- 2、字段解析:对字段进行解析时,会先在本类中查找是否包含有简单名称和字段描述符都与目标相匹配的字段,如果有,则查找结束;如果没有,则会按照继承关系从上往下递归搜索该类所实现的各个接口和它们的父接口,还没有,则按照继承关系从上往下递归搜索其父类,直至查找结束,查找流程如下图所示:

从下面一段代码的执行结果中很容易看出来字段解析的搜索顺序:
class Super{
public static int m = 11;
static{
System.out.println("执行了super类静态语句块");
}
}
class Father extends Super{
public static int m = 33;
static{
System.out.println("执行了父类静态语句块");
}
}
class Child extends Father{
static{
System.out.println("执行了子类静态语句块");
}
}
public class StaticTest{
public static void main(String[] args){
System.out.println(Child.m);
}
}执行了super类静态语句块
执行了父类静态语句块
33执行了super类静态语句块
11
最后需要注意:理论上是按照上述顺序进行搜索解析,但在实际应用中,虚拟机的编译器实现可能要比上述规范要求的更严格一些。如果有一个同名字段同时出现在该类的接口和父类中,或同时在自己或父类的接口中出现,编译器可能会拒绝编译。如果对上面的代码做些修改,将 Super 改为接口,并将 Child 类继承 Father 类且实现 Super 接口,那么在编译时会报出如下错误:
StaticTest.java:24: 对 m 的引用不明确,Father 中的 变量 m 和 Super 中的 变量 m
都匹配
System.out.println(Child.m);
^
1 错误- 3、类方法解析:对类方法的解析与对字段解析的搜索步骤差不多,只是多了判断该方法所处的是类还是接口的步骤,而且对类方法的匹配搜索,是先搜索父类,再搜索接口。
- 4、接口方法解析:与类方法解析步骤类似,知识接口不会有父类,因此,只递归向上搜索父接口就行了。
初始化
初始化是类加载过程的最后一步,到了此阶段,才真正开始执行类中定义的 Java 程序代码。在准备阶段,类变量已经被赋过一次系统要求的初始值,而在初始化阶段,则是根据程序员通过程序指定的主观计划去初始化类变量和其他资源,或者可以从另一个角度来表达:初始化阶段是执行类构造器()方法的过程。这里简单说明下类构造器()方法的执行规则:
- ()方法是由编译器自动收集类中的所有类变量的赋值动作和静态语句块中的语句合并产生的,编译器收集的顺序是由语句在源文件中出现的顺序所决定的,静态语句块中只能访问到定义在静态语句块之前的变量,定义在它之后的变量,在前面的静态语句中可以赋值,但是不能访问。
- ()方法与实例构造器()方法(类的构造函数)不同,它不需要显式地调用父类构造器,虚拟机会保证在子类的()方法执行之前,父类的()方法已经执行完毕。因此,在虚拟机中第一个被执行的()方法的类肯定是java.lang.Object。
- ()方法对于类或接口来说并不是必须的,如果一个类中没有静态语句块,也没有对类变量的赋值操作,那么编译器可以不为这个类生成()方法。
- 接口中不能使用静态语句块,但仍然有类变量(final static)初始化的赋值操作,因此接口与类一样会生成()方法。但是接口与类不同的是:执行接口的()方法不需要先执行父接口的()方法,只有当父接口中定义的变量被使用时,父接口才会被初始化。另外,接口的实现类在初始化时也一样不会执行接口的()方法。
- 虚拟机会保证一个类的()方法在多线程环境中被正确地加锁和同步,如果多个线程同时去初始化一个类,那么只会有一个线程去执行这个类的()方法,其他线程都需要阻塞等待,直到活动线程执行()方法完毕。如果在一个类的()方法中有耗时很长的操作,那就可能造成多个线程阻塞,在实际应用中这种阻塞往往是很隐蔽的。
class Father{
public static int a = 1;
static{
a = 2;
}
}
class Child extends Father{
public static int b = a;
}
public class ClinitTest{
public static void main(String[] args){
System.out.println(Child.b);
}
} 我们来看得到该结果的步骤。首先在准备阶段为类变量分配内存并设置类变量初始值,这样 A 和 B 均被赋值为默认值 0,而后再在调用()方法时给他们赋予程序中指定的值。当我们调用 Child.b 时,触发 Child 的()方法,根据规则 2,在此之前,要先执行完其父类Father的()方法,又根据规则1,在执行()方法时,需要按 static 语句或 static 变量赋值操作等在代码中出现的顺序来执行相关的 static 语句,因此当触发执行 Fathe r的()方法时,会先将 a 赋值为 1,再执行 static 语句块中语句,将 a 赋值为 2,而后再执行 Child 类的()方法,这样便会将 b 的赋值为 2。
如果我们颠倒一下 Father 类中“public static int a = 1;”语句和“static语句块”的顺序,程序执行后,则会打印出1。很明显是根据规则 1,执行 Father 的()方法时,根据顺序先执行了 static 语句块中的内容,后执行了“public static int a = 1;”语句。
另外,在颠倒二者的顺序之后,如果在 static 语句块中对 a 进行访问(比如将 a 赋给某个变量),在编译时将会报错,因为根据规则 1,它只能对 a 进行赋值,而不能访问。
总结
整个类加载过程中,除了在加载阶段用户应用程序可以自定义类加载器参与之外,其余所有的动作完全由虚拟机主导和控制。到了初始化才开始执行类中定义的 Java 程序代码(亦及字节码),但这里的执行代码只是个开端,它仅限于()方法。类加载过程中主要是将 Class 文件(准确地讲,应该是类的二进制字节流)加载到虚拟机内存中,真正执行字节码的操作,在加载完成后才真正开始。2.Class类
Class类没有公共构造方法,Class 对象是在加载类时由 Java 虚拟机以及通过调用类加载器中的 defineClass 方法自动构造的。
| 方法摘要 | ||
|---|---|---|
|
asSubclass(Class clazz) 强制转换该 Class 对象,以表示指定的 class 对象所表示的类的一个子类。 |
|
T |
cast(Object obj) 将一个对象强制转换成此 Class 对象所表示的类或接口。 |
|
boolean |
desiredAssertionStatus() 如果要在调用此方法时将要初始化该类,则返回将分配给该类的断言状态。 |
|
static Class |
forName(String className) 返回与带有给定字符串名的类或接口相关联的 Class 对象。 |
|
static Class |
forName(String name, boolean initialize, ClassLoader loader) 使用给定的类加载器,返回与带有给定字符串名的类或接口相关联的 Class 对象。 |
|
|
getAnnotation(Class annotationClass) 如果存在该元素的指定类型的注释,则返回这些注释,否则返回 null。 |
|
Annotation[] |
getAnnotations() 返回此元素上存在的所有注释。 |
|
String |
getCanonicalName() 返回 Java Language Specification 中所定义的底层类的规范化名称。 |
|
Class[] |
getClasses() 返回一个包含某些 Class 对象的数组,这些对象表示属于此 Class 对象所表示的类的成员的所有公共类和接口。 |
|
ClassLoader |
getClassLoader() 返回该类的类加载器。 |
|
Class |
getComponentType() 返回表示数组组件类型的 Class。 |
|
Constructor |
getConstructor(Class... parameterTypes) 返回一个 Constructor 对象,它反映此 Class 对象所表示的类的指定公共构造方法。 |
|
Constructor[] |
getConstructors() 返回一个包含某些 Constructor 对象的数组,这些对象反映此 Class 对象所表示的类的所有公共构造方法。 |
|
Annotation[] |
getDeclaredAnnotations() 返回直接存在于此元素上的所有注释。 |
|
Class[] |
getDeclaredClasses() 返回 Class 对象的一个数组,这些对象反映声明为此 Class 对象所表示的类的成员的所有类和接口。 |
|
Constructor |
getDeclaredConstructor(Class... parameterTypes) 返回一个 Constructor 对象,该对象反映此 Class 对象所表示的类或接口的指定构造方法。 |
|
Constructor[] |
getDeclaredConstructors() 返回 Constructor 对象的一个数组,这些对象反映此 Class 对象表示的类声明的所有构造方法。 |
|
Field |
getDeclaredField(String name) 返回一个 Field 对象,该对象反映此 Class 对象所表示的类或接口的指定已声明字段。 |
|
Field[] |
getDeclaredFields() 返回 Field 对象的一个数组,这些对象反映此 Class 对象所表示的类或接口所声明的所有字段。 |
|
Method |
getDeclaredMethod(String name, Class... parameterTypes) 返回一个 Method 对象,该对象反映此 Class 对象所表示的类或接口的指定已声明方法。 |
|
Method[] |
getDeclaredMethods() 返回 Method 对象的一个数组,这些对象反映此 Class 对象表示的类或接口声明的所有方法,包括公共、保护、默认(包)访问和私有方法,但不包括继承的方法。 |
|
Class |
getDeclaringClass() 如果此 Class 对象所表示的类或接口是另一个类的成员,则返回的 Class 对象表示该对象的声明类。 |
|
Class |
getEnclosingClass() 返回底层类的立即封闭类。 |
|
Constructor |
getEnclosingConstructor() 如果该 Class 对象表示构造方法中的一个本地或匿名类,则返回 Constructor 对象,它表示底层类的立即封闭构造方法。 |
|
Method |
getEnclosingMethod() 如果此 Class 对象表示某一方法中的一个本地或匿名类,则返回 Method 对象,它表示底层类的立即封闭方法。 |
|
T[] |
getEnumConstants() 如果此 Class 对象不表示枚举类型,则返回枚举类的元素或 null。 |
|
Field |
getField(String name) 返回一个 Field 对象,它反映此 Class 对象所表示的类或接口的指定公共成员字段。 |
|
Field[] |
getFields() 返回一个包含某些 Field 对象的数组,这些对象反映此 Class 对象所表示的类或接口的所有可访问公共字段。 |
|
Type[] |
getGenericInterfaces() 返回表示某些接口的 Type,这些接口由此对象所表示的类或接口直接实现。 |
|
Type |
getGenericSuperclass() 返回表示此 Class 所表示的实体(类、接口、基本类型或 void)的直接超类的 Type。 |
|
Class[] |
getInterfaces() 确定此对象所表示的类或接口实现的接口。 |
|
Method |
getMethod(String name, Class... parameterTypes) 返回一个 Method 对象,它反映此 Class 对象所表示的类或接口的指定公共成员方法。 |
|
Method[] |
getMethods() 返回一个包含某些 Method 对象的数组,这些对象反映此 Class 对象所表示的类或接口(包括那些由该类或接口声明的以及从超类和超接口继承的那些的类或接口)的公共 member 方法。 |
|
int |
getModifiers() 返回此类或接口以整数编码的 Java 语言修饰符。 |
|
String |
getName() 以 String 的形式返回此 Class 对象所表示的实体(类、接口、数组类、基本类型或 void)名称。 |
|
Package |
getPackage() 获取此类的包。 |
|
ProtectionDomain |
getProtectionDomain() 返回该类的 ProtectionDomain。 |
|
URL |
getResource(String name) 查找带有给定名称的资源。 |
|
InputStream |
getResourceAsStream(String name) 查找具有给定名称的资源。 |
|
Object[] |
getSigners() 获取此类的标记。 |
|
String |
getSimpleName() 返回源代码中给出的底层类的简称。 |
|
Class |
getSuperclass() 返回表示此 Class 所表示的实体(类、接口、基本类型或 void)的超类的 Class。 |
|
TypeVariable |
getTypeParameters() 按声明顺序返回 TypeVariable 对象的一个数组,这些对象表示用此 GenericDeclaration 对象所表示的常规声明来声明的类型变量。 |
|
boolean |
isAnnotation() 如果此 Class 对象表示一个注释类型则返回 true。 |
|
boolean |
isAnnotationPresent(Class annotationClass) 如果指定类型的注释存在于此元素上,则返回 true,否则返回 false。 |
|
boolean |
isAnonymousClass() 当且仅当底层类是匿名类时返回 true。 |
|
boolean |
isArray() 判定此 Class 对象是否表示一个数组类。 |
|
boolean |
isAssignableFrom(Class cls) 判定此 Class 对象所表示的类或接口与指定的 Class 参数所表示的类或接口是否相同,或是否是其超类或超接口。 |
|
boolean |
isEnum() 当且仅当该类声明为源代码中的枚举时返回 true。 |
|
boolean |
isInstance(Object obj) 判定指定的 Object 是否与此 Class 所表示的对象赋值兼容。 |
|
boolean |
isInterface() 判定指定的 Class 对象是否表示一个接口类型。 |
|
boolean |
isLocalClass() 当且仅当底层类是本地类时返回 true。 |
|
boolean |
isMemberClass() 当且仅当底层类是成员类时返回 true。 |
|
boolean |
isPrimitive() 判定指定的 Class 对象是否表示一个基本类型。 |
|
boolean |
isSynthetic() 如果此类是复合类,则返回 true,否则 false。 |
|
T |
newInstance() 创建此 Class 对象所表示的类的一个新实例。 |
|
String |
toString() 将对象转换为字符串。 |
|
获取Class类对象
- 类.class 如: String.class使用类名加“.class”的方式即会返回与该类对应的Class对象。这个方法可以直接获得与指定类关联的Class对象,而并不需要有该类的对象存在。
- Class.forName("类名");该方法可以根据字符串参数所指定的类名获取与该类关联的Class对象。如果该类还没有被装入,该方法会将该类装入JVM。forName方法的参数是类的完整限定名(即包含包名)。通常用于在程序运行时根据类名动态的载入该类并获得与之对应的Class对象。
- obj.getClass();所有Java对象都具备这个方法,该方法用于返回调用该方法的对象的所属类关联的Class对象

获取类信息
1.获取类的构造方法
- Constructor getConstructor(Class[] params) 根据构造函数的参数,返回一个具体的具有public属性的构造函数
- Constructor getConstructors() 返回所有具有public属性的构造函数数组
- Constructor getDeclaredConstructor(Class[] params) 根据构造函数的参数,返回一个具体的构造函数(不分public和非public属性)
- Constructor getDeclaredConstructors() 返回该类中所有的构造函数数组(不分public和非public属性)
2.获取类的成员属性
- Field getField(String name) 根据变量名,返回一个具体的具有public属性的成员变量
- Field[] getFields() 返回具有public属性的成员变量的数组
- Field getDeclaredField(String name) 根据变量名,返回一个成员变量(不分public和非public属性)
- Field[] getDelcaredFields() 返回所有成员变量组成的数组(不分public和非public属性)
3.获取类的成员方法
- Method getMethod(String name, Class[] params) 根据方法名和参数,返回一个具体的具有public属性的方法
- Method[] getMethods() 返回所有具有public属性的方法数组
- Method getDeclaredMethod(String name, Class[] params) 根据方法名和参数,返回一个具体的方法(不分public和非public属性)
- Method[] getDeclaredMethods() 返回该类中的所有的方法数组(不分public和非public属性)
Java反射
package io.mycat.route.function;
import io.mycat.config.model.rule.RuleAlgorithm;
import io.mycat.route.parser.util.Pair;
import io.mycat.route.util.PartitionUtil;
import io.mycat.util.StringUtil;
public final class PartitionByString extends AbstractPartitionAlgorithm implements RuleAlgorithm {
private int hashSliceStart = 0;
private int hashSliceEnd = 8;
protected int[] count;
protected int[] length;
protected PartitionUtil partitionUtil;
public PartitionByString() {
super();
}
public PartitionByString(int hashSliceStart, int hashSliceEnd, int[] count, int[] length) {
super();
this.hashSliceStart = hashSliceStart;
this.hashSliceEnd = hashSliceEnd;
this.count = count;
this.length = length;
}
public void setPartitionCount(String partitionCount) {
this.count = toIntArray(partitionCount);
}
public void setPartitionLength(String partitionLength) {
this.length = toIntArray(partitionLength);
}
public void setHashLength(int hashLength) {
setHashSlice(String.valueOf(hashLength));
}
public void setHashSlice(String hashSlice) {
Pair p = sequenceSlicing(hashSlice);
hashSliceStart = p.getKey();
hashSliceEnd = p.getValue();
}
public static Pair sequenceSlicing(String slice) {
...
return new Pair(start, end);
}
@Override
public void init() {
partitionUtil = new PartitionUtil(count, length);
}
private static int[] toIntArray(String string) {
String[] strs = io.mycat.util.SplitUtil.split(string, ',', true);
int[] ints = new int[strs.length];
for (int i = 0; i < strs.length; ++i) {
ints[i] = Integer.parseInt(strs[i]);
}
return ints;
}
@Override
public Integer calculate(String key) {
int start = hashSliceStart >= 0 ? hashSliceStart : key.length() + hashSliceStart;
int end = hashSliceEnd > 0 ? hashSliceEnd : key.length() + hashSliceEnd;
long hash = StringUtil.hash(key, start, end);
return partitionUtil.partition(hash);
}
@Override
public int getPartitionNum() {
int nPartition = 0;
for (int i = 0; i < count.length; i++) {
nPartition += count[i];
}
return nPartition;
}
} 运行时加载类
package io.mycat.test.clss;
public class Reflection {
public static void main(String[] args)
throws ClassNotFoundException, InstantiationException, IllegalAccessException {
// String className=从配置文件读取类名;
// 加载
// 假设从配置文件读到的类名为io.mycat.route.function.PartitionByString
Class clazz = Class.forName("io.mycat.route.function.PartitionByString");// 由于类在程序启动时不存在,所以只能用这种方式加载
}
}
获取构造方法及实例化
package io.mycat.test.clss;
import java.lang.reflect.Constructor;
import java.lang.reflect.Field;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Modifier;
import java.lang.reflect.Parameter;
import io.mycat.config.util.ConfigException;
public class Reflection {
public static void main(String[] args) throws ClassNotFoundException, InstantiationException,
IllegalAccessException, IllegalArgumentException, InvocationTargetException {x
Class clazz = Class.forName("io.mycat.route.function.PartitionByString");// 由于类在程序启动时不存在,所以只能用这种方式加载
// 获取构造方法
Constructor[] constructors = clazz.getConstructors();
for (Constructor constructor : constructors) {
System.out.println(constructor);
if (constructor.getParameterCount() == 0) {
System.out.println("无参构造方法。");
Object obj = constructor.newInstance();
System.out.println("无参构造实例完成。");
} else {
System.out.println("有参构造方法。");
Parameter[] pts = constructor.getParameters();
String strValue;
Object[] values = new Object[constructor.getParameterCount()];
int idx = 0;
for (Parameter pt : pts) {
System.out.println(" 参数类型:" + pt.getParameterizedType().getTypeName() + " 参数名称:" + pt.getName());
Class type = pt.getType();
String name = pt.getName();
strValue = "0";// 可以根据参数名称pt.getName(),从配置文件等地方获得参数值,为了重点突出,这里不再提供相关代码,而直接用字符串"0"代替
if (type.equals(String.class)) {
values[idx++] = strValue;
} else if (type.equals(Boolean.TYPE)) {
values[idx++] = Boolean.valueOf(strValue);
} else if (type.equals(Byte.TYPE)) {
values[idx++] = Byte.valueOf(strValue);
} else if (type.equals(Short.TYPE)) {
values[idx++] = Short.valueOf(strValue);
} else if (type.equals(Integer.TYPE)) {
values[idx++] = Integer.valueOf(strValue);
} else if (type.equals(Long.TYPE)) {
values[idx++] = Long.valueOf(strValue);
} else if (type.equals(Double.TYPE)) {
values[idx++] = Double.valueOf(strValue);
} else if (type.equals(Float.TYPE)) {
values[idx++] = Float.valueOf(strValue);
} else if (type.equals(Class.class)) {
try {
values[idx++] = Class.forName(strValue);
} catch (ClassNotFoundException e) {
throw new ConfigException(e);
}
} else {
values[idx++] = null;
}
}
Object obj = constructor.newInstance(values);
System.out.println("有参构造实例完成。");
}
}
// 无参构造实例快捷方式
// 实例化一个类对象,由于不知道是个什么,但不管是什么类,必然继承自java.lang.Object类,所以可以用Object类型变量接收实例化的对象
Object obj = clazz.newInstance();// 这种方式实例化,调用的是类的无参构造器,所以PartitionByString类必须有公开的无参构造方法
// 1、获取字段
// 1.1 获取Field的数组,私有字段也能获取
Field[] fields = clazz.getDeclaredFields();
for (Field field : fields) {
System.out.println(Modifier.toString(field.getModifiers()) + " " + field.getGenericType().getTypeName()
+ " " + field.getName());
}
Object obj2 = clazz.newInstance(0,0);
}
}public io.mycat.route.function.PartitionByString()
无参构造方法。
无参构造实例完成。
public io.mycat.route.function.PartitionByString(int,int)
有参构造方法。
参数类型:int 参数名称:hashSliceStart
参数类型:int 参数名称:hashSliceEnd
有参构造实例完成。
上面的代码中有参构造实例部分,需要使用构造方法的参数名称,从外部获取参数值,这有点不守规矩,因为在Java语言里,对于方法(method)来说,方法名称、参数类型和参数个数,是决定方法是否唯一的三要素,而参数名称并不重要,可以随便起名。构造方法也是方法,也适合这条定理,所以使用参数名称来获取参数值,有点不合规矩。而且从构造类Constructor里获取参数名,只有在Java 1.8版本以后才支持,而且需要在编译Java源文件时加上-Parameter参数,就是javac编译时加上这个参数才可以,1.8以前的版本是不支持获取方法的参数名称的。所以在使用Java反射机制实例化类时,不使用有参数构造方法,而使用无参构造方法,待实例化完成之后,再调用对象的get/set方法来设置属性值,这种方式比较通用。
获取属性(Field字段)及修改字段值
package io.mycat.test.clss;
import java.lang.reflect.Constructor;
import java.lang.reflect.Field;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Modifier;
import java.lang.reflect.Parameter;
import io.mycat.config.util.ConfigException;
public class Reflection {
public static void main(String[] args)
throws ClassNotFoundException, InstantiationException, IllegalAccessException, IllegalArgumentException,
InvocationTargetException, NoSuchMethodException, SecurityException, NoSuchFieldException {
Class clazz = Class.forName("io.mycat.route.function.PartitionByString");// 由于类在程序启动时不存在,所以只能用这种方式加载
// 实例化一个对象
Constructor constr = clazz.getConstructor(int.class, int.class);
Object obj2 = constr.newInstance(10, 20);// 获取字段
// 获取Field的数组,私有字段也能获取
Field[] fields = clazz.getDeclaredFields();
for (Field field : fields) {
System.out.println(Modifier.toString(field.getModifiers()) + " " + field.getGenericType().getTypeName()
+ " " + field.getName());
} // 获取指定字段,假设已经知道了字段名
Field field = clazz.getDeclaredField("hashSliceStart");
field.setAccessible(true); // 由于是私有字段,需要先为可访问,否则无法读和写
Object val = field.get(obj2);
System.out.println("获取指定对象字段'hashSliceStart'的Field的值: " + val);
// 修改字段值
field.set(obj2, 30);
val = field.get(obj2);
System.out.println("修改后指定对象字段'hashSliceStart'的Field的值: " + val);
}
}
private int hashSliceStart
private int hashSliceEnd
protected int[] count
protected int[] length
protected io.mycat.route.util.PartitionUtil partitionUtil
获取指定对象字段'hashSliceStart'的Field的值: 10
修改后指定对象字段'hashSliceStart'的Field的值: 30由上面代码可知,不管是私有字段还是公有字段,都可以通过Java反射机制获取,字段值都可以被Java反射机制修改。
获取方法(Method)及方法调用
package io.mycat.test.clss;
import java.lang.reflect.Constructor;
import java.lang.reflect.Field;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
import java.lang.reflect.Modifier;
import java.lang.reflect.Parameter;
import io.mycat.config.util.ConfigException;
public class Reflection {
public static void main(String[] args)
throws ClassNotFoundException, InstantiationException, IllegalAccessException, IllegalArgumentException,
InvocationTargetException, NoSuchMethodException, SecurityException, NoSuchFieldException {
Class clazz = Class.forName("io.mycat.route.function.PartitionByString");// 由于类在程序启动时不存在,所以只能用这种方式加载
// 实例化一个对象
Constructor constr = clazz.getConstructor(int.class, int.class);
Object obj2 = constr.newInstance(10, 20);
// 获取本类声明的所有方法(包括private方法,但不包括父类方法)
Method[] methods = clazz.getDeclaredMethods();
for (Method method : methods) {
System.out.println(Modifier.toString(method.getModifiers()) + " " + method.getReturnType().getSimpleName()
+ " " + method.getName());
}
// 获取指定的方法,假设已经知道了方法名
Method method = clazz.getDeclaredMethod("getHashSliceStart");// 第一个参数是方法名,后面的是方法里的参数
method.setAccessible(true); // 由于是私有方法,需要先设置为可访问,否则无法调用
Object value = method.invoke(obj2);
System.out.println("set方法调用前hashSliceStart : " + value);
Method method2 = clazz.getDeclaredMethod("setHashSliceStart", int.class);// 第一个参数是方法名,后面的是方法里的参数
// method2.setAccessible(true);// 由于是公有方法,无需先设置为可访问
method2.invoke(obj2, 30);
value = method.invoke(obj2);
System.out.println("set方法调用后hashSliceStart : " + value);
}
}
public void init
private static int[] toIntArray
public void setHashLength
public void setHashSlice
public static Pair sequenceSlicing
public Integer calculate
public int getPartitionNum
private int getHashSliceStart
public void setHashSliceStart
public void setPartitionCount
public void setPartitionLength
set方法调用前hashSliceStart : 10
set方法调用后hashSliceStart : 30由上面代码可知,不管是私有方法,还是公有方法,都可以被Java反射机制调用,使用方式与属性类似。
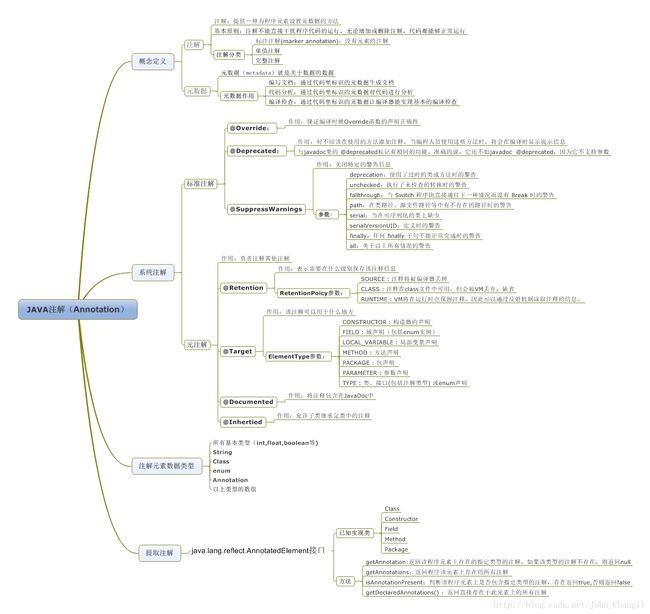
获取Annotation(注解)
什么是Annotation(注解)
- 从 JDK5.0 开始,Java 增加了对元数据(MetaData)的支持,也就是Annotation(注释)
- Annotation其实就是代码里的特殊标记,这些标记可以在编译,类加载, 运行时被读取,并执行相应的处理.通过使用Annotation,程序员可以在不改变原有逻辑的情况下,在源文件中嵌入一些补充信息.
- Annotation 可以像修饰符一样被使用,可用于修饰包,类,构造器, 方法,成员变量, 参数,局部变量的声明,这些信息被保存在Annotation的 “name=value”对中.
- Annotation能被用来为程序元素(类,方法,成员变量等)设置元数据
Annotation(注解)的用途是什么
- a.标记作用,用于告诉编译器一些信息
- b.编译时动态处理,如动态生成代码
- c.运行时动态处理,如得到注解信息
基本的 Annotation(注解)
- 使用 Annotation时要在其前面增加@符号,并把该Annotation 当成一个修饰符使用.用于修饰它支持的程序元素
- 三个基本的Annotation:
- @Override:限定重写父类方法,该注释只能用于方法
- @Deprecated:用于表示某个程序元素(类,方法等)已过时
- @SuppressWarnings:抑制编译器警告.
自定义Annotation(注解)
- 定义新的 Annotation类型使用@interface关键字
- Annotation 的成员变量在Annotation 定义中以无参数方法的形式来声明.其方法名和返回值定义了该成员的名字和类型.
- 可以在定义Annotation的成员变量时为其指定初始值,指定成员变量的初始值可使用default关键字
- 没有成员定义的Annotation称为标记;包含成员变量的Annotation称为元数据Annotation
package io.mycat.test.annotation;
import java.util.Date;
@Table("ruser")
public class User {
@Field(name = "id", type = "bigint")
private long id;
@Field(name = "user_name", type = "varchar")
private String name;
@Field(name = "user_name", type = "datetime")
private Date regDate;
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Date getRegDate() {
return regDate;
}
public void setRegDate(Date regDate) {
this.regDate = regDate;
}
}
package io.mycat.test.annotation;
import java.lang.annotation.Retention;
import java.lang.annotation.Target;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.ElementType;
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface Table {
public String value() default ""; //表名
}package io.mycat.test.annotation;
import java.lang.annotation.Retention;
import java.lang.annotation.Target;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.ElementType;
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.FIELD)
public @interface Field {
public String name() default ""; // 字段名称
public String type() default ""; // 字段类型
}
元注解
- @Target
- @Retention
- @Documented
- @Inherited
@Target:
@Target说明了Annotation所修饰的对象范围:Annotation可被用于 packages、types(类、接口、枚举、Annotation类型)、类型成员(方法、构造方法、成员变量、枚举值)、方法参数和本地变量(如循环变量、catch参数)。在Annotation类型的声明中使用了target可更加明晰其修饰的目标。
作用:用于描述注解的使用范围(即:被描述的注解可以用在什么地方)
取值(ElementType)有:
- CONSTRUCTOR:用于描述构造器
- FIELD:用于描述域
- LOCAL_VARIABLE:用于描述局部变量
- METHOD:用于描述方法
- PACKAGE:用于描述包
- PARAMETER:用于描述参数
- TYPE:用于描述类、接口(包括注解类型) 或enum声明
默认值:未标注则表示可修饰所有。
@Retention:
@Retention定义了该Annotation被保留的时间长短:某些Annotation仅出现在源代码中,而被编译器丢弃;而另一些却被编译在class文件中;编译在class文件中的Annotation,有些可能会被虚拟机忽略,而另一些在class被装载时将被读取(请注意并不影响class的执行,因为Annotation与class在使用上是被分离的)。使用这个元注解可以对 Annotation的“生命周期”限制。
作用:表示需要在什么级别保存该注释信息,用于描述注解的生命周期(即:被描述的注解在什么范围内有效)
取值(RetentionPoicy)有:
- SOURCE:在源文件中有效(即源文件保留),值为 SOURCE 大都为 Mark Annotation,这类 Annotation 大都用来校验,比如 Override, Deprecated, SuppressWarnings
- CLASS:在class文件中有效(即class保留)
- RUNTIME:在运行时有效(即运行时保留)
默认值:CLASS
@Documented:
@Documented用于表示该Annotation应该被作为被标注的程序成员的公共API,因此可以被例如javadoc此类的工具文档化。@Documented是一个标记注解,没有成员。
@Inherited:
@Inherited用于表示该Annotation是可以被继承的。如果一个使用了@Inherited修饰的Annotation类型被用于一个class,则这个Annotation将被用于该class的子类。注意:@Inherited Annotation类型是被标注过的class的子类所继承。类并不从它所实现的接口继承Annotation,方法并不从它所重载的方法继承annotation。当@Inherited Annotation类型的Retention是RetentionPolicy.RUNTIME,则反射API增强了这种继承性。如果我们使用java.lang.reflect去查询一个@Inherited Annotation时,反射代码检查将展开工作:检查class和其父类,直到发现指定的annotation类型被发现,或者到达类继承结构的顶层。@Inherited 元注解是一个标记注解,没有成员。
定义注解格式
public @interface 注解名 {定义体}
定义体:
定义体里定义注解的参数,参数名为方法名,且:
- 所有方法没有方法体,没有参数,只允许用public或默认(default)这两个访问权修饰,不允许抛异常。例如,String value();这里把方法设为defaul默认类型
- 方法返回值只能是int,float,boolean,byte,double,char,long,short,String, Class, annotation, enumeration 或者是他们的一维数组
- 若只有一个参数成员,最好使用 value() 函数。一个属性都没有表示该 Annotation 为 Mark Annotation
- 可以加 default 表示默认值
注解参数的默认值:
自定义注解示例:
package io.mycat.test.annotation;
import java.lang.annotation.Retention;
import java.lang.annotation.Target;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.ElementType;
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.FIELD)
public @interface Field {
public String name() default ""; // 字段名称
public String type() default ""; // 字段类型
}
注解的解析
运行时Annotation解析
- Class:类定义
- Constructor:构造器定义
- Field:累的成员变量定义
- Method:类的方法定义
- Package:类的包定义
- 方法1:
T getAnnotation(Class annotationClass): 返回改程序元素上存在的、指定类型的注解,如果该类型注解不存在,则返回null。 - 方法2:Annotation[] getAnnotations():返回该程序元素上存在的所有注解。
- 方法3:boolean is AnnotationPresent(Class annotationClass):判断该程序元素上是否包含指定类型的注解,存在则返回true,否则返回false.
- 方法4:Annotation[] getDeclaredAnnotations():返回直接存在于此元素上的所有注释。与此接口中的其他方法不同,该方法将忽略继承的注释。(如果没有注释直接存在于此元素上,则返回长度为零的一个数组。)该方法的调用者可以随意修改返回的数组;这不会对其他调用者返回的数组产生任何影响。
package io.mycat.test.annotation;
import java.lang.reflect.Field;
public class UserAnn {
public static void main(String[] args) throws ClassNotFoundException {
// 获得类
// Class clazz = new User().getClass(); //获取类的第一种方式
Class clazz = User.class; // 获取类的第二种方式
// Class clazz = Class.forName("io.mycat.test.annotation.User"); //获取类的第三种方式
// 读取类的注释
// Annotation[] anns = obj.getClass().getAnnotations(); //得到所有注释
Table table = clazz.getAnnotation(Table.class); // 取得指定注释
System.out.println("类【" + clazz.getSimpleName() + "】注释(表名): " + table.value());
// 读取属性的注释
Field[] fields = clazz.getDeclaredFields();
for (Field f : fields) {
// Annotation[] anns2 = f.getAnnotations(); //得到所有注释
Column column = f.getAnnotation(Column.class);// 取得指定注释
if (column != null) {
System.out.println("属性【" + f.getName() + "】注释(列名--类型): " + column.name() + " -- " + column.type());
}
}
}
}
类【User】注释(表名): ruser
属性【id】注释(列名--类型): id -- bigint
属性【name】注释(列名--类型): user_name -- varchar
属性【regDate】注释(列名--类型): user_name -- datetime
编译时Annotation解析
package io.mycat.test.annotation;
import java.util.Set;
import javax.annotation.processing.AbstractProcessor;
import javax.annotation.processing.RoundEnvironment;
import javax.annotation.processing.SupportedAnnotationTypes;
import javax.lang.model.element.Element;
import javax.lang.model.element.TypeElement;
@SupportedAnnotationTypes({ "io.mycat.test.annotation.User" })
public class UserProcessor extends AbstractProcessor {
@Override
public boolean process(Set annotations, RoundEnvironment env) {
for (TypeElement te : annotations) {
for (Element element : env.getElementsAnnotatedWith(te)) {
Table table = element.getAnnotation(Table.class);
System.out.println(element.getEnclosingElement().toString() + " : " + table.value());
}
}
return true;
}
}
- 自定义的处理类UserProcessor需要继承AbstractProcessor,并实现process方法。
- SupportedAnnotationTypes 表示这个 Processor 要处理的 Annotation 名字。
- process 函数中参数 annotations 表示待处理的 Annotations,参数 env 表示当前或是之前的运行环境
- process 函数返回值表示这组 annotations 是否被这个 Processor 接受,如果接受后续子的 Processor 不会再对这个Annotations 进行处理
4.Java内省
package io.mycat.test.bean;
public class Partition {
private int start;
private int end;
public int getStart() {
return start;
}
public void setStart(int start) {
this.start = start;
}
public int getEnd() {
return end;
}
public void setEnd(int end) {
this.end = end;
}
}
package io.mycat.test.bean;
import java.beans.BeanInfo;
import java.beans.IntrospectionException;
import java.beans.Introspector;
import java.beans.PropertyDescriptor;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
public class PartitionParse {
public static void main(String[] args)
throws IntrospectionException, IllegalAccessException, IllegalArgumentException, InvocationTargetException {
BeanInfo beanInfo = Introspector.getBeanInfo(Partition.class); // 通过Introspector取得BeanInfo
PropertyDescriptor[] pds = beanInfo.getPropertyDescriptors(); // 通过BeanInfo取得PropertyDescriptors(所有属性)
Partition partition = new Partition(); // 实例化一个对象,方法调用时会用到
for (PropertyDescriptor pd : pds) { // 循环每一个属性
if (pd.getName().equals("start")) { // 找到名为"start"的属性
Method rMethod = pd.getReadMethod(); // 通过PropertyDescriptor取得get方法
System.out.println("start修改前值:" + rMethod.invoke(partition, null)); // 调用get方法
Method wMethod = pd.getWriteMethod(); // 通过PropertyDescriptor取得set方法
wMethod.invoke(partition, 10); // 调用set方法
System.out.println("start修改后值:" + rMethod.invoke(partition, null)); // 再次调用get方法,查看修改后的值
}
}
}
}start修改前值:0
start修改后值:10
package io.mycat.test.bean;
import java.beans.BeanInfo;
import java.beans.IntrospectionException;
import java.beans.Introspector;
import java.beans.MethodDescriptor;
import java.beans.PropertyDescriptor;
public class PartitionParse {
public static void main(String[] args) throws IntrospectionException {
BeanInfo beanInfo = Introspector.getBeanInfo(Partition.class);
PropertyDescriptor[] pds = beanInfo.getPropertyDescriptors();
for (PropertyDescriptor pd : pds) {
System.out.println(pd.getPropertyType().getName() + " " + pd.getName()); //打印所有属性
}
}
}java.lang.Class class
int end
int startpackage io.mycat.test.bean;
import java.beans.BeanInfo;
import java.beans.IntrospectionException;
import java.beans.Introspector;
import java.beans.MethodDescriptor;
import java.beans.PropertyDescriptor;
public class PartitionParse {
public static void main(String[] args) throws IntrospectionException {
BeanInfo beanInfo = Introspector.getBeanInfo(Partition.class);
MethodDescriptor[] mds = beanInfo.getMethodDescriptors();
for (MethodDescriptor md : mds) {
System.out.println(md.getMethod().getReturnType().getSimpleName() + " " + md.getName()); // 打印所有方法
}
}
}Class getClass
int getStart
void setStart
void setEnd
int getEnd
void wait
void notifyAll
void notify
void wait
int hashCode
void wait
boolean equals
String toStringpackage io.mycat.test.bean;
public class Partition {
private int middle;
public int getStart() {
return 1;
}
public void setEnd(int middle) {
}
public int middle() {
return 1;
}
}package io.mycat.test.bean;
import java.beans.BeanInfo;
import java.beans.IntrospectionException;
import java.beans.Introspector;
import java.beans.MethodDescriptor;
import java.beans.PropertyDescriptor;
public class PartitionParse {
public static void main(String[] args) throws IntrospectionException {
BeanInfo beanInfo = Introspector.getBeanInfo(Partition.class);
PropertyDescriptor[] pds = beanInfo.getPropertyDescriptors();
for (PropertyDescriptor pd : pds) {
System.out.println(pd.getPropertyType().getName() + " " + pd.getName()); // 打印所有属性
}
}
}java.lang.Class class
int end
int start再来验证一下,如果get方法没有返回类型,set方法没用参数或参数个数不是一个,会怎样:
package io.mycat.test.bean;
public class Partition {
public void getStart() {
// return 1;
}
public void setEnd() {
}
public void setMiddle(int m, int n) {
}
}class java.lang.Class class
null middle
5.MyCat里类的运行时加载和Java内省/反射机制的使用
private AbstractPartitionAlgorithm createFunction(String name, String clazz)
throws ClassNotFoundException, InstantiationException, IllegalAccessException, InvocationTargetException {
Class clz = Class.forName(clazz);
// 判断是否继承AbstractPartitionAlgorithm
if (!AbstractPartitionAlgorithm.class.isAssignableFrom(clz)) {
throw new IllegalArgumentException(
"rule function must implements " + AbstractPartitionAlgorithm.class.getName() + ", name=" + name);
}
return (AbstractPartitionAlgorithm) clz.newInstance();
}
public static void mapping(Object object, Map parameter) throws IllegalAccessException,
InvocationTargetException {
//获取用于导出clazz这个JavaBean的所有属性的PropertyDescriptor
PropertyDescriptor[] pds = getDescriptors(object.getClass());
for (int i = 0; i < pds.length; i++) {
PropertyDescriptor pd = pds[i];
Object obj = parameter.get(pd.getName());
Object value = obj;
Class cls = pd.getPropertyType();
//类型转换
if (obj instanceof String) {
String string = (String) obj;
if (!StringUtil.isEmpty(string)) {
string = ConfigUtil.filter(string);
}
if (isPrimitiveType(cls)) {
value = convert(cls, string);
}
} else if (obj instanceof BeanConfig) {
value = createBean((BeanConfig) obj);
} else if (obj instanceof BeanConfig[]) {
List private static PropertyDescriptor[] getDescriptors(Class clazz) {
// PropertyDescriptor类表示JavaBean类通过存储器导出一个属性
PropertyDescriptor[] pds;
List list;
PropertyDescriptor[] pds2 = descriptors.get(clazz);
// 该clazz是否第一次加载
if (null == pds2) {
try {
BeanInfo beanInfo = Introspector.getBeanInfo(clazz);
pds = beanInfo.getPropertyDescriptors();
list = new ArrayList();
// 加载每一个类型不为空的property
for (int i = 0; i < pds.length; i++) {
if (null != pds[i].getPropertyType()) {
list.add(pds[i]);
}
}
pds2 = new PropertyDescriptor[list.size()];
list.toArray(pds2);
} catch (IntrospectionException ie) {
LOGGER.error("ParameterMappingError", ie);
pds2 = new PropertyDescriptor[0];
}
}
descriptors.put(clazz, pds2);
return (pds2);
} package io.mycat.route.function;
import io.mycat.config.model.rule.RuleAlgorithm;
import io.mycat.route.parser.util.Pair;
import io.mycat.route.util.PartitionUtil;
import io.mycat.util.StringUtil;
public final class PartitionByString extends AbstractPartitionAlgorithm implements RuleAlgorithm {
private int hashSliceStart = 0;
private int hashSliceEnd = 8;
protected int[] count;
protected int[] length;
protected PartitionUtil partitionUtil;
public void setPartitionCount(String partitionCount) {
this.count = toIntArray(partitionCount);
}
public void setPartitionLength(String partitionLength) {
this.length = toIntArray(partitionLength);
}
public void setHashLength(int hashLength) {
setHashSlice(String.valueOf(hashLength));
}
public void setHashSlice(String hashSlice) {
Pair p = sequenceSlicing(hashSlice);
hashSliceStart = p.getKey();
hashSliceEnd = p.getValue();
}
public static Pair sequenceSlicing(String slice) {
...
return new Pair(start, end);
}
@Override
public void init() {
partitionUtil = new PartitionUtil(count, length);
}
private static int[] toIntArray(String string) {
...
return ints;
}
@Override
public Integer calculate(String key) {
...
return partitionUtil.partition(hash);
}
@Override
public int getPartitionNum() {
...
return nPartition;
}
}
512
2
0:2
另外,MyCat源码里,每使用内省解析一个类的属性后,就会将取得的属性组缓存起来(放在descriptors里),但是内省本来就会缓存,所以这里再缓存一次,没有必要。
public static void mapping2(Object object, Map parameter)
throws IllegalAccessException, InvocationTargetException {
// 获取Field的数组,私有字段也能获取
Field[] fields = object.getClass().getDeclaredFields();
for (Field field : fields) {
String fieldName = field.getName();
Object obj = parameter.get(fieldName);
Object value = obj;
Class cls = field.getType();
if (obj != null) {
// 类型转换
if (obj instanceof String) {
String string = (String) obj;
if (!StringUtil.isEmpty(string)) {
string = ConfigUtil.filter(string);
}
if (isPrimitiveType(cls)) {
value = convert(cls, string);
}
} else if (obj instanceof BeanConfig) {
value = createBean((BeanConfig) obj);
} else if (obj instanceof BeanConfig[]) {
List