Hadoop(六)————Hive
1、什么是Hive
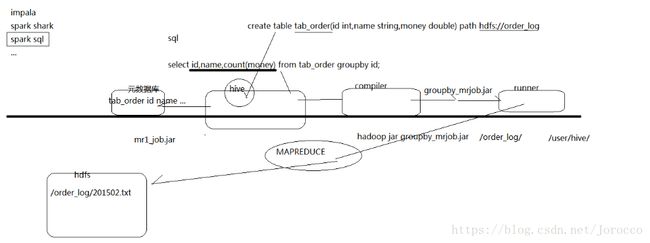
2、Hive的安装
Hive只需要在一个节点上安装即可,因为它不是一个集群。
2.1 上传tar包
2.2 解压
tar -zxvf hive-0.9.0.tar.gz -C /app/2.3 安装hive
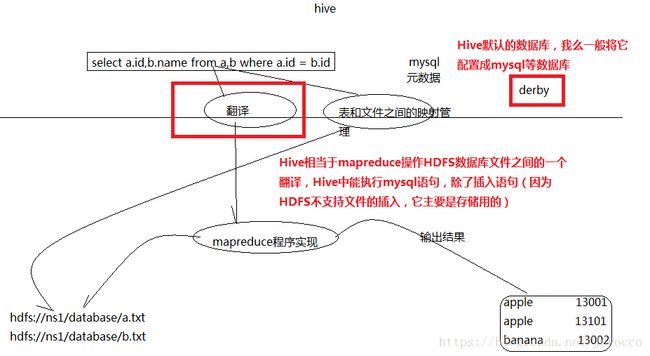
运行hive发现内置默认的metastore存在问题(1.换执行路径后,原来的表不存在了。2.只能有一个用户访问同一个表),所以配置成mysql(因为数据都是存在数据库中的,hive只是充当一个翻译的角色)。
查询以前安装的mysql相关包
rpm -qa | grep mysql
暴力删除这个包
rpm -e mysql-libs-5.1.66-2.el6_3.i686 --nodeps
rpm -ivh MySQL-server-5.1.73-1.glibc23.i386.rpm
rpm -ivh MySQL-client-5.1.73-1.glibc23.i386.rpm
执行命令设置mysql使得通过用户名和密码能访问到mysql
/usr/bin/mysql_secure_installation
GRANT ALL PRIVILEGES ON hive.* TO 'root'@'%' IDENTIFIED BY 'hadoop' WITH GRANT OPTION;
FLUSH PRIVILEGES
将mysql配置到hive启动中
#重命名hive的配置文件
cp hive-default.xml.template hive-site.xml
修改hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://Master:3306/hive?createDatabaseIfNotExist=truevalue>
property>
<property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>com.mysql.jdbc.Drivervalue>
property>
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>rootvalue>
property>
<property>
<name>javax.jdo.option.ConnectionPasswordname>
<value>hadoopvalue>
property>
configuration>
安装hive和mysq完成后,将mysql的连接jar包(mysql-connector-java-5.1.37-bin.jar
)拷贝到hive的lib目录下
进入到hive的bin目录下启动hive
执行:./hive即可(前提是得把hadoop集群启动起来,hive是建立在hdfs的基础上的)3、hive的使用
CREATE TABLE page_view(viewTime INT, userid BIGINT,
page_url STRING, referrer_url STRING,
ip STRING COMMENT 'IP Address of the User')
COMMENT 'This is the page view table'
PARTITIONED BY(dt STRING, country STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
STORED AS SEQUENCEFILE; TEXTFILE
create table tab_ip_seq(id int,name string,ip string,country string)
row format delimited
fields terminated by ','
stored as sequencefile;
insert overwrite table tab_ip_seq select * from tab_ext;
//create & load
create table tab_ip(id int,name string,ip string,country string)
row format delimited
fields terminated by ','
stored as textfile;
load data local inpath '/home/hadoop/ip.txt' into table tab_ext;
/上面建的数据库都是在HDFS的/user/hive/warehouse目录下的,比如建个master库,则它在HDFS上的路径为/user/hive/warehouse/master.db
//通过load导的数据都是转到了master.db下(注意:不通过hive导数据操作,直接通过hadoop fs -put将数据上传到master.db下的表中,在hive中通过表查询也能查询到数据)
//external(不要求数据必须到/user/hive/warehouse下,并且执行drop删除表操作的时候,它只删除元数据,即只是在hive中查询不到数据了(删除了hive和HDFS的关联而已),但它在HDFS上依然没有任何变化,但上面那种manager_table则都会被删除掉)
CREATE EXTERNAL TABLE tab_ip_ext(id int, name string,
ip STRING,
country STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE
//指定数据的任意位置
LOCATION '/external/hive';
// CTAS 用于创建一些临时表存储中间结果
//将表tab_ip_ext中id name ip country字段的数据存储到表tab_ip_ctas中new_id new_name new_ip new_country字段中
//它会在tab_ip_ext同目录下创建一个tab_ip_ctas文件并在它的下面创建一个000000_0文件,里面存储的就是拿到的数据
CREATE TABLE tab_ip_ctas
AS
SELECT id new_id, name new_name, ip new_ip,country new_country
FROM tab_ip_ext
SORT BY new_id;
//insert from select 用于向临时表中追加中间结果数据
create table tab_ip_like like tab_ip;
insert overwrite table tab_ip_like
select * from tab_ip;
//PARTITION
create table tab_ip_part(id int,name string,ip string,country string)
//按part_flag字段分区(也可以是上面的任意字段)
partitioned by (part_flag string)
row format delimited fields terminated by ',';
//它其实就是在表tab_ip_part目录下新建一个part_flag=part1的文件
load data local inpath '/home/hadoop/ip.txt' overwrite into table tab_ip_part
partition(part_flag='part1');
load data local inpath '/home/hadoop/ip_part2.txt' overwrite into table tab_ip_part
partition(part_flag='part2');
select * from tab_ip_part;
//按分区查询数据,并且会在原有字段的基础上添加一个part_flag字段
select * from tab_ip_part where part_flag='part2';
select count(*) from tab_ip_part where part_flag='part2';
alter table tab_ip change id id_alter string;
ALTER TABLE tab_cts ADD PARTITION (partCol = 'dt') location '/external/hive/dt';
//write to hdfs
insert overwrite local directory '/home/hadoop/hivetemp/test.txt' select * from tab_ip_part where part_flag='part1';
insert overwrite directory '/hiveout.txt' select * from tab_ip_part where part_flag='part1';
//对集合数据进行处理
//array
create table tab_array(a array<int>,b array<string>)
row format delimited
fields terminated by '\t'
//数组数据以','为分割符分隔数据
collection items terminated by ',';
示例数据
tobenbrone,laihama,woshishui 13866987898,13287654321
abc,iloveyou,itcast 13866987898,13287654321
select a[0] from tab_array;
select * from tab_array where array_contains(b,'word');
insert into table tab_array select array(0),array(name,ip) from tab_ext t;
//map
create table tab_map(name string,info map<string,string>)
row format delimited
fields terminated by '\t'
//集合里面键值对以';'作为分隔符
collection items terminated by ';'
//map和keys之间以':'作为分隔符
map keys terminated by ':';
示例数据:
fengjie age:18;size:36A;addr:usa
furong age:28;size:39C;addr:beijing;weight:180KG
load data local inpath '/home/hadoop/hivetemp/tab_map.txt' overwrite into table tab_map;
insert into table tab_map select name,map('name',name,'ip',ip) from tab_ext;
//struct
create table tab_struct(name string,info structint,tel:string,addr:string>)
row format delimited
fields terminated by '\t'
collection items terminated by ','
load data local inpath '/home/hadoop/hivetemp/tab_st.txt' overwrite into table tab_struct;
insert into table tab_struct select name,named_struct('age',id,'tel',name,'addr',country) from tab_ext;
//cli shell
hive -S -e 'select country,count(*) from tab_ext' > /home/hadoop/hivetemp/e.txt
有了这种执行机制,就使得我们可以利用脚本语言(bash shell,python)进行hql语句的批量执行